DTMとは直接関係ないですが、音声合成・音声認識もDTMステーションの記事テーマの一つとして、これまでもいろいろ取り上げてきました。その音声認識を実現する製品として、とにかく便利すぎると感じているのが、ソースネクストが販売するAutoMemoです。これは、普通にボイスレコーダーとして録音すると、その内容が自動でクラウドにアップロードされるとともに、AIが音声認識して、文字起こしされて読めるようになる、というデバイス。
その文字認識の精度が高く、まさに「使い物になる」んです。しかも話者認識もするので、誰がしゃべったのかまで、キレイに整理して表示されるのは、まさに驚き。数年前には信じられなかったことが実現できている、まさに夢のデバイスです。私自身が、AutoMemoを知ったのは2022年11月でしたが、それ以来個人的にサブスク契約し、もはや絶対に手放せないものとなっていますが、それから10か月の間にも、機能が進化してきているのです。ただブラックボックスな部分も多く、裏で何をしているのか、見えない点もあるのも事実。実際どのような仕組みになっているのかなど、ソースネクストに話を聞きに行ってみました。【PR】
 ソースネクストのAutoMemo開発担当者にお話しを伺ってみた
ソースネクストのAutoMemo開発担当者にお話しを伺ってみた
録音した音声をAIが文字起こししてくれるAutoMemo
AutoMemoについて、ご存じない方も多いと思うので、簡単に紹介すると、これはソースネクストが販売している小さなAIボイスレコーダーです。初代のAutoMemo、2代目のAutoMemo S、そして先日発売されたAutoMemo Rの3機種がありますが、現行品として販売されているのはAutoMemo SとAutoMemo R。私自身はAutoMemo Sユーザーなのですが、先日、AutoMemo Rをソースネクストから借りて試してみたところ、なるほど、こっちのほうが断然便利にできているな…と感じているところです。
 左から初代AutoMemo、AutoMemo S、AutoMemo R
左から初代AutoMemo、AutoMemo S、AutoMemo R
一般的なボイスレコーダーと同様、取材のときや、会議のときに机の上に置いて、録音ボタンを押せば、その場の声が録音されるのですが、すごいのはここから。あらかじめWi-Fi設定をしておくと、録音終了後、録音データが自動でクラウドにアップロードされて、AIエンジンが自動で文字起こししてくれるのです。その結果はアプリやブラウザで読むことができ、しかも話者認識も自動でしてくれるのです。
もちろんAIはしゃべっている人が誰かを知らないため、最初はAさん、Bさん、Cさん……となっていますが、編集機能を用いてユーザーが名前を付けることで、より読みやすくなる、というわけです。
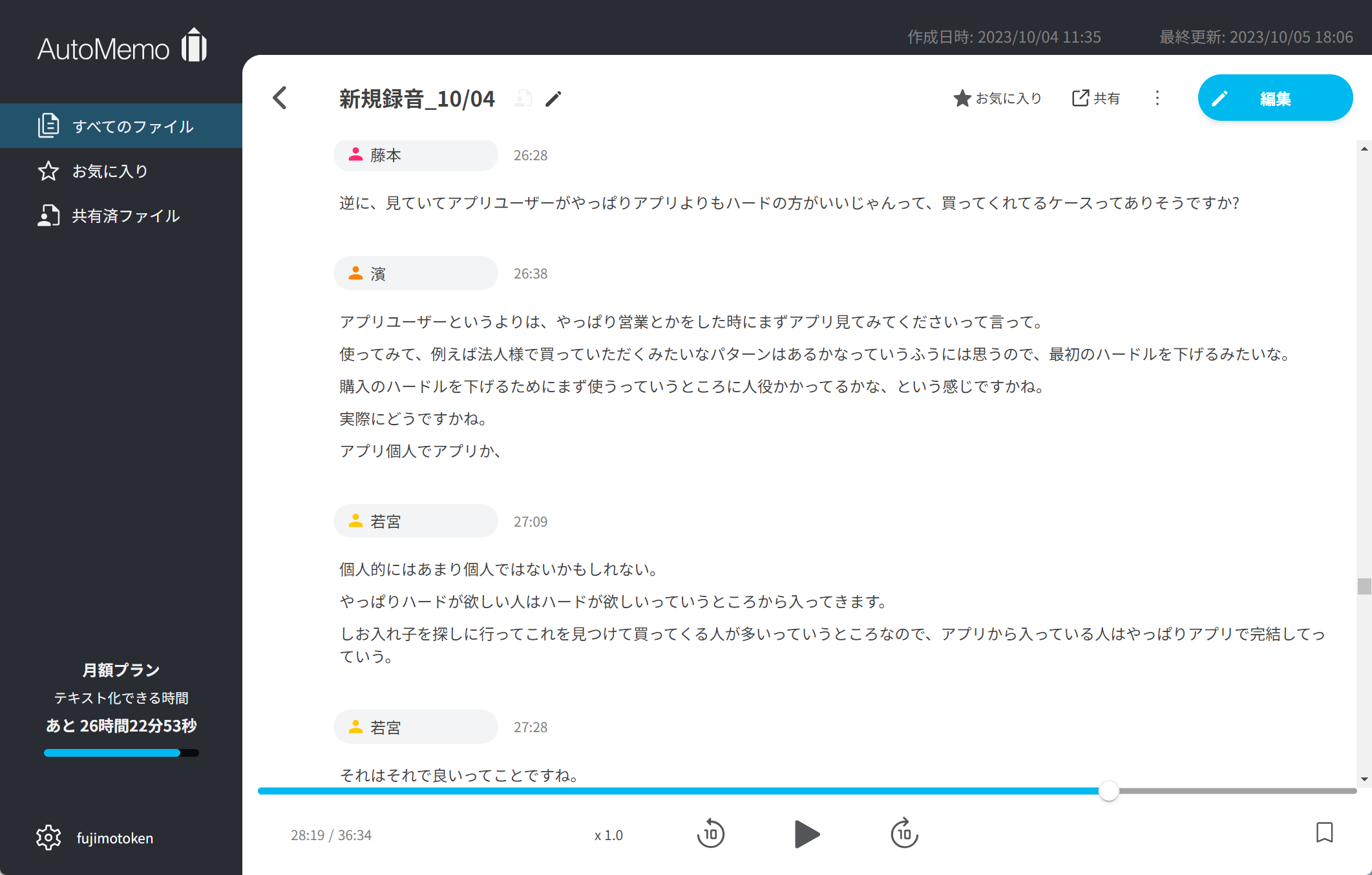 会話をほぼ完全な形で認識してくれるとともに、話者認識もした形でブラウザ上に表示してくれるオートメモHome
会話をほぼ完全な形で認識してくれるとともに、話者認識もした形でブラウザ上に表示してくれるオートメモHome
さすがに100%の認識率というわけにはいかないものの、十分使えるレベル。また、「ここは何を言っているんだ?」と思う部分があれば、その文字のところにカーソルを持ってきて再生ボタンを押せば、声で聴くこともできる仕様になっているのです。つまり、音声データも文字データもクラウド上にあり、その容量は無制限。ただし、月々に音声認識する時間が決まっていて、1時間までならお試しプランということで無料、30時間までは1,480円などとなっています。
 ソースネクストの濱雅妃さん(左)と若宮亜里沙さん(右)
ソースネクストの濱雅妃さん(左)と若宮亜里沙さん(右)
しかも私が使い始めた昨年11月当初と比べて、さらに認識率が大幅に上がっていると感じていました。どうも裏側で進化しているようなんですよね。この辺がどうなっているのかなど伺いにソースネクストに行ってきました。対応してくれたのはAutoMemoの企画担当である濱雅妃さんと、開発担当である若宮亜里沙さんのお二人です。
ポケトークの音声認識技術の転用として誕生したAutoMemo
--もともとAutoMemoの事業を行うようになったキッカケなどについて教えてください。
若宮:当社では以前からAI通訳機であるポケトークを出していますが、このポケトークは通訳する前に音声認識を行っています。たとえば日本語でしゃべると、それを日本語の文字にした上で翻訳して音声にしているのです。この音声認識がかなりの精度を持っていたので、これをほかに生かせないだろうか……というところででてきたアイディアがAutoMemoだったのです。
 ソースネクストの自動翻訳機、ポケトーク
ソースネクストの自動翻訳機、ポケトーク
濱:さまざまなメーカーからボイスレコーダーは出ていましたが、一貫して文字起こしまで行う機材はありませんでした。たしかに音声認識して文字にするアプリはあったけれど、専用機はなかったので、これは行けるのでは…と企画を進めていったのです。ポケトークも専用機であることの強みを感じていました。もちろん、アプリでも近いことはできるはずですが、直接話すからこそ、それに合う形でのマイク性能にこだわれますし、端末のUXをシンプルにすることで使いやすくなる。だから専用機にすることで大きな強みを発揮できるはずだ、と2019年の後半ごろからプロジェクトを始動させたのです。
--私自身は昨年11月ごろから使っているので、その前のことを知らないのですが、最初に製品が出たのはいつごろだったんですか?
濱:2020年12月です。そのときに出したのはスティック型の録音専用機で、再生機能も持っていなかったのです。録音したデータはクラウドにアップされるので、音を聴くのはアプリがあればいいはず、と機能をシンプルにしていました。当時、価格としては19,800円での発売となりました。
 AutoMemoの企画担当者、濱雅妃さん
AutoMemoの企画担当者、濱雅妃さん
若宮:大きな話題にはなったのですが、当初は認識率が75%というものでした。75%というと、それなりの精度があるようにも思えますが、実用面からすると、まだまだ使えないというのが実情でした。またその時点では句読点がつかなかったり、フィラーと呼ばれる「えー」とか「あー」という会話中の間を埋める発話を認識することができなかったため、使いにくかったのです。ポケトークの場合は短い言葉をマイクに向かってしゃべるだけなので、その音声認識エンジンで事足りたのですが、AutoMemoの場合、1時間とか2時間録音して使うので、用途がまったく違います。もちろん、いろいろチューニングは行っていましたが、そのエンジンではなかなか無理があったというのが実際のところでした。
よりよい音声認識エンジンに変更し、ソースネクストがチューニング
--その後、エンジンの改良を行ったのですか?
若宮:エンジンの改良というよりは、エンジンの載せ替えを行っています。公表はしていませんが、初代のエンジンは海外製のものでしたが、2代目のエンジンは日本製のものにしています。もちろん、単に載せ替えたというだけでなく、いろいろとチューニングも行ってボイスレコーダーとして使いやすいものにしていきました。
--チューニングとはどんなことをするんですか?
若宮:クラウドにアップした後、音声認識に入れる前に、音量の調整を行ったり、ノイズ除去を行うほか、先ほどのフィラーの除去なども行っています。またハルシネーションと呼ばれる、ノイズの大きい部分をAIが頑張って認識しようとしてしまうため、幻聴のような文字がいっぱい出てきてしまうんです。素のままで通すと、その幻聴のようなものが酷かったため、チューニングによって抑えるようにしました。
 ディスプレイも搭載し、音声認識した結果を読むことも可能なAIボイスレコーダー、AutoMemo S
ディスプレイも搭載し、音声認識した結果を読むことも可能なAIボイスレコーダー、AutoMemo S
濱:その2代目のエンジンにしたのがAutoMemo S発売のタイミングでした。AutoMemo Sはディスプレイを付けて、ここで文字を読めるようにしたほか、再生機能も搭載し、これ一つで、一通りのことができるようにしました。またこのAutoMemo S発売のタイミングで初代AutoMemoの価格を下げています。
--なるほど、ハードとソフト、両軸で進化させてきたわけですね。そして、今回さらに新機種としてAutoMemo Rを出されたわけですよね?
濱:AutoMemo Sは機能をすべて盛り込んだこともあって、先進感が強すぎるという面もありました。その心理的ハードルを下げ、一般的なボイスレコーダーの使い勝手に寄せた、というのがAutoMemo Rなんです。そのためAutoMemo Rにはタッチディスプレイがなくなっています。またスリープ状態で置いておくと5分で自動的に電源が落ちるようになっているので、1か月放置しておいてもバッテリーの容量が残っているという点も大きな違いです。ユーザーによって好みは分かれると思うので、AutoMemo SとAutoMemo Rは併売としており、従来のボイスレコーダーに慣れていてそうした使い方をしたい方はAutoMemo Rを、搭載のディスプレイで文字を確認したい方はAutoMemo Sを選んでいただければと思います。
 文字表示機能などをなくし、より一般的なボイスレコーダーに寄せた最新機種、AutoMemo R
文字表示機能などをなくし、より一般的なボイスレコーダーに寄せた最新機種、AutoMemo R
最新バージョンはOpenAI社のエンジンを採用
--一方で、先日オートメモHomeというものが登場し、従来より圧倒的に使いやすくなっていたことには驚きました。この辺の経緯を少し教えていただけますか?
若宮:細かな改良は常に行っているのですが、いくつかの大きな動きがありました。まず今年3月に先ほどお話した日本製の音声認識エンジンから、OpenAI社のエンジンに変更しました。これによって、さらに大きく音声認識率が向上しています。もちろんOpenAI社のエンジンを単にそのまま使っているわけではなく、当社でいろいろチューニングしている形です。さらに、この8月に話者分離機能を追加しました。この話者分離はOpenAI社のものではなく、また別のものを使っているのですが、こうしたものを組み合わせた形で、オートメモHomeをスタートさせたので、より使い勝手がよくなっているかと思います。
濱:この話者分離機能の搭載とオートメモHomeのスタートと、AutoMemo Rの発売が同じタイミングとなっていました。
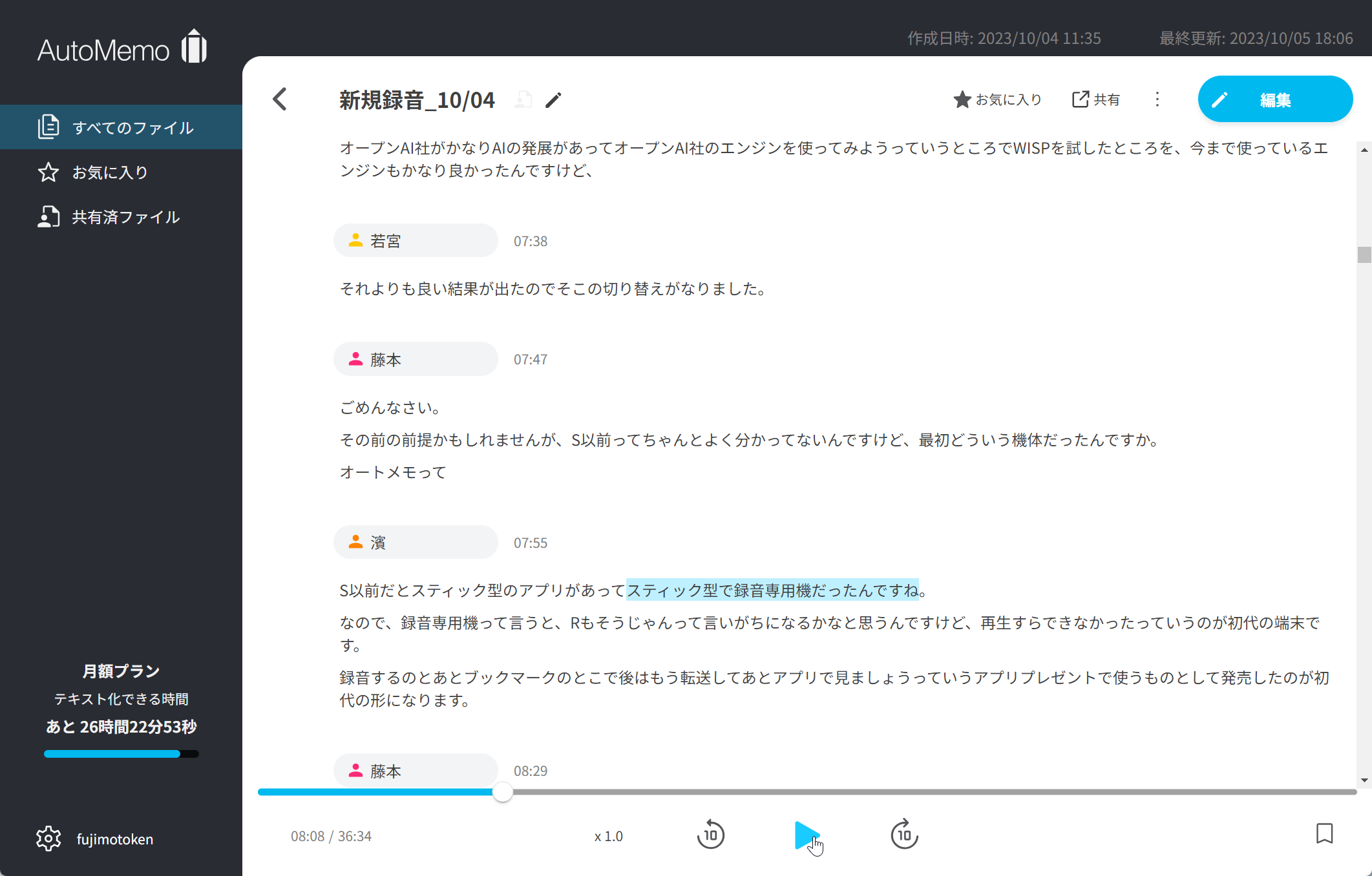 文字と音声は連動しているので、気になる部分で再生ボタンを押せば、その時の音声を聴くことができる
文字と音声は連動しているので、気になる部分で再生ボタンを押せば、その時の音声を聴くことができる
--これまで自分のGoogleDriveやOneDriveなどのクラウドにテキストファイルとMP3ファイルが保存される形だったのが、オートメモHomeでブラウザから見れるようになり、それを他の人に共有できるようになったのも圧倒的に便利ですね。一方で、iOSやAndroid版のアプリはいつごろからあったのですか?
濱:アプリ自体はAutoMemoの初代機が出たタイミングからありましたが、機能はいろいろ追加されていきました。当初は、あくまでもテキストが読めて、音声が再生できる形でしたが、2022年9月に録音機能も搭載し、一通りのことができるようになっています。

スマホアプリ版のオートメモ。文字と合わせて音声を再生できるだけでなく、これで録音もできる
--私が最初に使った時点で、すでに録音もできるようになっていましたが、これがあると、AutoMemoのハードウェアなしに、すべてができてしまいますよね?このアプリは無料で提供されているし、これだとハードが売れずに儲からないのではないですか?
若宮:アプリで一通りできるようにしたのですが、やはりアプリには弱点もあります。まずは、スマホであるため着信があると録音が途切れてしまうという問題があります。また、録音容量の制限があったり、バッテリーの持ちの問題もあるので、やはり専用機ならではの良さがあると考えています。一方で、まずはいろいろな方に試していただきたい、使っていただきたいというのがあり、無料で開放している格好です。また企業などでは、個人のスマホにデータを残さない…といった方針があるところも多く、専用のハードを購入いただいています。
 AutoMemoの開発担当である若宮亜里沙さん
AutoMemoの開発担当である若宮亜里沙さん
--使っていて、大丈夫なの?と思うのが容量についてです。録音したデータはクラウドに残りますが、ずっと消えずに残っていますよね?それなりに大きなデータだと思うので、ソースネクストとしても費用がかさむのではと思いますが、今後、バッサリ消去されてしまう…なんて可能性はあるのでしょうか?
濱:容量無制限というのがAutoMemoの大きなウリのひとつですし、できるだけシンプルに分かりやすくするというのがAutoMemoのコンセプトでもあるので、ここは残したいと思っています。ただ、確かにサーバーコストは大きくなっていくので、古いデータは、クラウドのサーバーでも取り出すのに多少時間がかかるところに移動させる…といったことは少し考えているところです。
外部音声対応や要約機能など、今後も進化していく
--AutoMemo、とっても便利に使っていますが、一つ不満があるのが、ほかのレコーダーで録った音を認識させたい場合、アナログでダビングしないといけないという点。時間もかかるし、ダビングで音質も落ちそうなので、これはなんとかならないでしょうか?
若宮:その点は、現在開発を進めており、まだ時期は未定ではありますが、今後搭載する予定です。MP3やWAVなどの音声ファイルでも、MP4などの動画でも使えるようになるので、もうしばらくお待ちください。
--それはとっても嬉しいです。ほかにも今後搭載される機能があれば教えていただけますか?
若宮:いろいろ便利になるように開発を進めていますが、来年には文字起こし結果を要約する機能なども搭載する予定です。話者ごとに要約する…といったことまでできたらいいな、と考えています。また、その内容をもとにToDoを作成する…といった機能も盛り込んでいければと考えているところです。ぜひ、今後の展開もご期待ください。
--ありがとうございました。
【関連情報】
AutoMemo製品情報
【価格チェック&購入】
◎ソースネクスト ⇒ AutoMemo R

コメント