本日8月1日、音声合成技術の世界に、また画期的な動きがありました。「Seiren Voice」や「Yukarinライブラリ」の開発者としても知られるヒロシバ(@hiho_karuta)さんが、ITAコーパスを利用した商用利用も可能なAI音声合成システム、VOICEVOXなるソフトウェアをオープンソースのとして無料でリリースしたのです。具体的には現時点Windowsで動くシステムで、「ずんだもん」および「四国めたん」の声でテキストを読み上げるシステムとなっています。
これがオープンソースとなったことで、一般ユーザーが自由に利用できるというだけでなく、さまざまなシステムに組み込んで喋らせることが可能になったのが画期的なところ。たとえばロボットなどに組み込んで対話型のシステムを作ることや、観光案内システムに導入して喋らせる……といったこともできるほか、クラウド型のシステムを構築し、ブラウザを経由して対話できるようにするといったことも可能になるのです。ややシステム寄りの話で、その意義がよく理解できない……という人も少なくないと思うので、仕掛け人であるITAコーパスのプロジェクト責任者であり、SSS合同会社の小田恭央さんにオンラインインタビューするとともに、システムを開発したヒロシバさんにもメールインタビューすることができたので、その内容を紹介していきたいと思います。
 四国めたん、ずんだもんを喋らせることができるVOICEVOXがオープンソースとしてフリーウェア公開された
四国めたん、ずんだもんを喋らせることができるVOICEVOXがオープンソースとしてフリーウェア公開された
今回、オープンソースとして公開されたAI音声合成システム、VOICEVOXは、まさに人が喋っているような滑らかな感じで喋ってくれるソフトウェア。6月12日に研究者向けに公開された「ITAコーパス マルチモーダルデータベース」を元にディープラーニングさせて作られたもの。
 クラウドファンディングを通じ、喋る際の唇の動きをデータベース化させていた
クラウドファンディングを通じ、喋る際の唇の動きをデータベース化させていた
「ITAコーパス って何だ?」という方が大半だと思いますが、これは以前「読唇術を実現するためのデータベース作成!? 口の動きだけで言葉を認識し、違う声にする究極のバ美肉技術のための研究資金をクラウドファンディング中」という記事で取り上げたデータベースで、東北イタコの歌唱データベース制作のクラウドファンディングのストレッチゴールとして登場したもの。
 ITAコーパス マルチモーダルデータベースとして研究者向けに公開されている(https://zunko.jp/multimodal_dev/login.php)
ITAコーパス マルチモーダルデータベースとして研究者向けに公開されている(https://zunko.jp/multimodal_dev/login.php)
簡単にいうと、声優さんが喋る言葉を録音するとともに、それに音素ラベルを付けてデータベース化を行う一方、その喋るところをビデオ撮影し、唇(くちびる)の動きも一緒にデータベース化したものです。目的は読唇術をシステム的に実現することで、カメラで捉えた唇の動きを元に音声合成ができる研究を進めよう、というものでした。
今回公開されたVOICEVOXはそのITAコーパスのデータベースの中の唇の動きは一旦無視し、音声データベースだけを取り出してディープラーニングさせて音声合成システムとして仕上げたものとなっています。以下からダウンロードできるので、ぜひ、試してみてください。

Windowsの実行ファイルとなっており、ZIPファイルを展開した上で、適当なフォルダにコピーしてVOICEVOX.exeを起動すれば、インストール作業不要で使うことができます。初回起動時に、CPUモードで使うかGPUモードで使うかの選択画面が現れるのでいずれかを選ぶことで、最適化されるようになっています。この際、GPUを選ぶことで、より高速に処理できるようになりますが、NVIDIA製でメモリが3GB以上あるGPUを搭載していることが条件となります。
 初回起動時にCPUモードで使うか、GPUモードで使うかを設定する
初回起動時にCPUモードで使うか、GPUモードで使うかを設定する
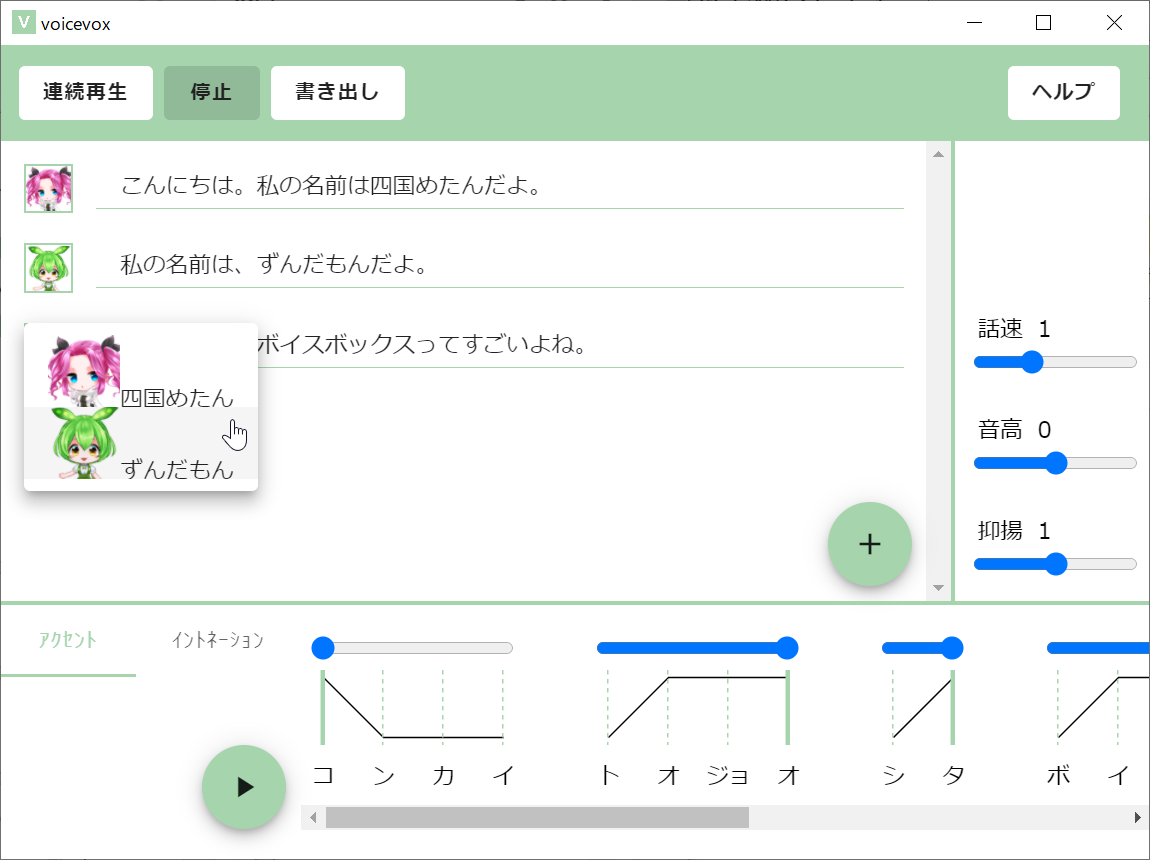
起動すれば、使い方はシンプル。これまでVOICEROIDやCeVIOなどの音声合成ソフトを使ったことのある方ならすぐにわかるはずです。右下の「+」ボタンを押すことで文章入力が可能になるので、キャラクタとして、ずんだもん、または四国めたんを選択した上でテキストを入力し、再生ボタンを押せば、喋ってくれます。
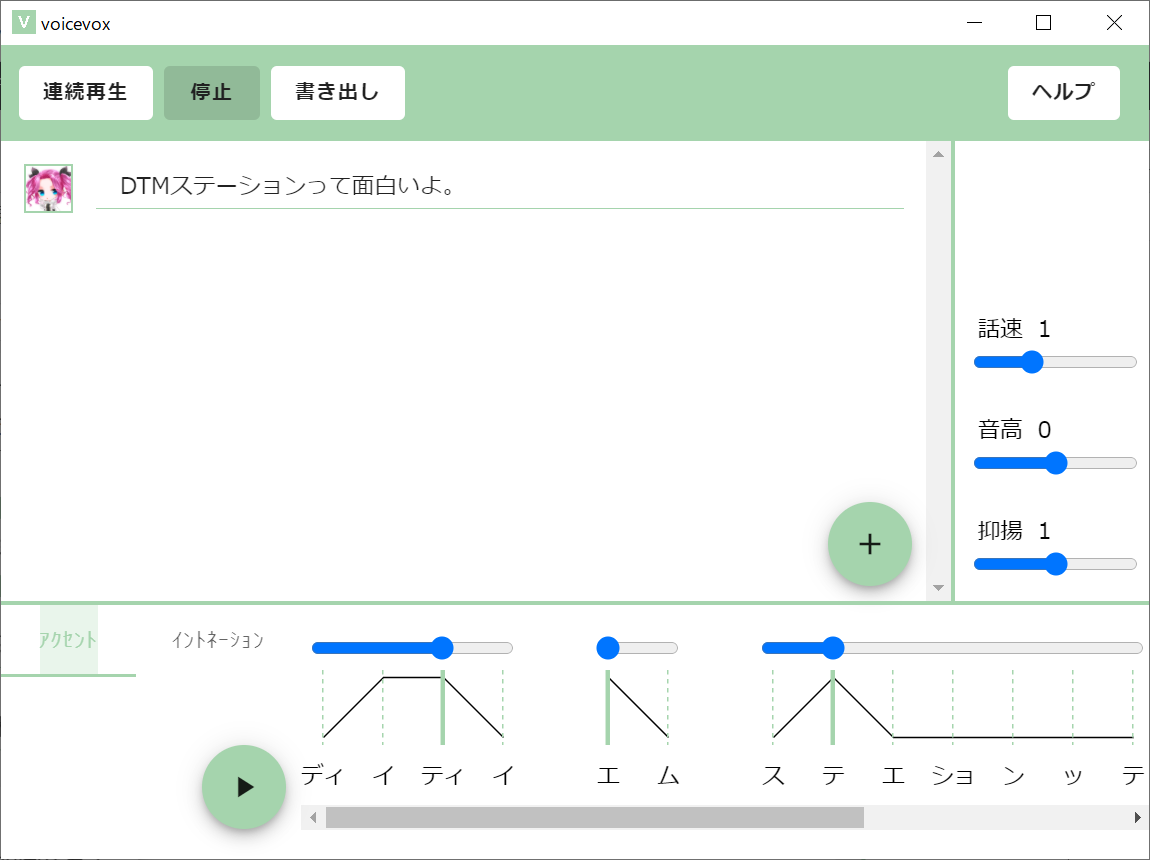 テキストを入力すれば、すぐに喋らせることができ、アクセントもユーザーが調整できる
テキストを入力すれば、すぐに喋らせることができ、アクセントもユーザーが調整できる
必要に応じて話すスピード(話速)、声の高さ(音高)抑揚の大きさ(抑揚)という3つのパラメータを調整することで、雰囲気を変更することも可能です。
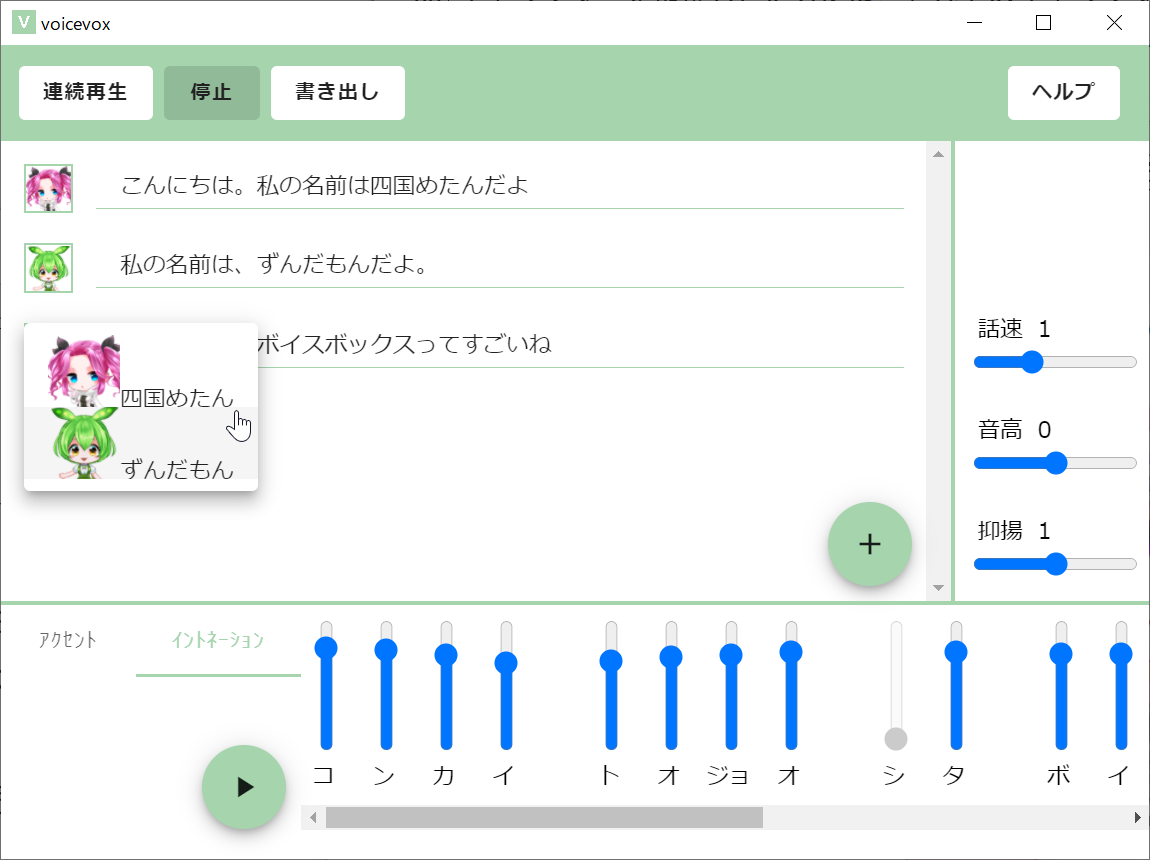
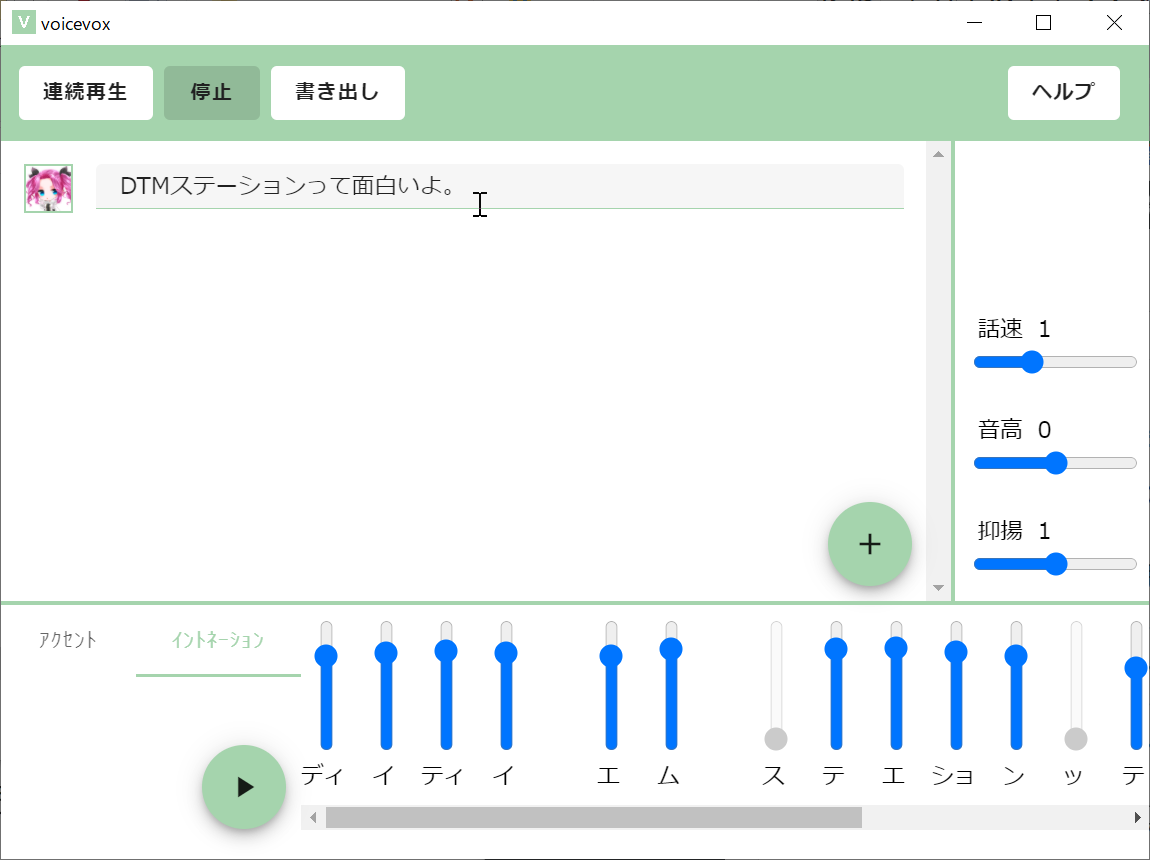 イントネーションタブをクリックすることで、イントネーションも自由に調整可能
イントネーションタブをクリックすることで、イントネーションも自由に調整可能
また、イントネーションがおかしい場合には、イントネーションタブをクリックして出てくる画面で調整することもできるし、アクセントがおかしい場合には、アクセントタブをクリックして調整することが可能です。さらに単に喋らせるだけでなく、WAVファイルとして書き出すことも可能になっています。試してみたところ書き出す場合は16bit/24kHzのモノラルとなっているようですね。
複数の文を入力していった場合、001.wav、002.wav、003.wav……と自動で連番生成されます。また一度書き出した後、同じフォルダに再度書き出すと上書きされてしまうので、その点は注意が必要ですね。
とっても便利に使えそうなソフトですが、これはどのようにして誕生したのか、SSSの小田さん、開発者のヒロシバさんにお話しを伺ってみました。
--VOICEVOXが誕生した経緯を教えてください
ヒロシバ:僕はVOICEROID 結月ゆかりのような音声合成キャラクターが大好きなのですが、人気のあるキャラクターを作るのってすごくお金がかかるんですよね。なので、「お金を払っても良いからそのキャラクターを利用したい人」からお金を払ってもらってキャラクターを運営する、という構図ができており、これは新規キャラクター参戦にとっての壁だと感じています。でも世の中には「お金は一旦いいからキャラクターを作りたい」という人が結構います。そして「無料だったらそのキャラクターを利用したい人」は多くいるはずです。この二者を繋げるような無料の音声合成ソフトウェアがあれば、参戦の壁が取り除かれて、僕の大好きな音声合成キャラクターが増えるのでは!?と思ったのが、VOICEVOXの開発を始めたきっかけです。
 VOICEVOXを開発した、ヒロシバさん
VOICEVOXを開発した、ヒロシバさん
--そのキャラクターの声の元素材として、先日公開されたITAコーパスが使われたわけですね。改めてITAコーパス制作の経緯を教えてもらえますか?
小田:昨年、東北イタコの歌唱データベース制作プロジェクトのクラウドファンディングを行った際、そのストレッチゴールとしてITAコーパス読唇データベースを作るということになり、261%という達成をすることができました。いろいろと苦労はあったのですが、みなさんのご協力をいただき、データベースを完成させることができ、先日6月12日に公開したのです。現在、いろいろな研究者の方がこのデータベースをダウンロードして、使っていただいていますが、その中で、いち早く連絡いただいたのが、ヒロシバさんでした。いろいろなやり取りをした結果、オープンソースとして公開するという形になったのです。
SSS合同会社の小田恭央さん
--ITコーパスには東北イタコ、四国めたん、ずんだもんの3つがありますが、このうちの四国めたんとずんだもんのデータをディープラーニングで学習してモデルを作ったということなのでしょうか?
ヒロシバ:そうです。ITAコーパスでは各々のキャラクターで十分な音声データ量と、人による正確な音素ラベルがセットで配布されており、そのままディープラーニングの学習データとして活用できました。アクセントやイントネーション、音素長をユーザーが調整できるようにしたかったので、最近ディープラーニング界で流行りのEnd-to-Endモデルを使わず、自作のモデルを使って工夫をしています。
 四国めたんのキャラクタ
四国めたんのキャラクタ
--非常になめらかな喋りで驚きます。ところで今回オープンソースでの公開となっていますが、単にフリーウェアとして無料で配布というのと、オープンソースでの公開というのは、どんな意味合いの違いが出てくるのでしょうか?
小田:いろいろな違いがあると思います。すでに無料で利用できるTTS(Text To Speech:喋る音声合成ソフト)は存在していますが、オープンソースにしたことで、システムに組み込むことが可能となるのが大きな違いです。Windowsサーバーなどに組み込んでおけばネット経由で喋らせることもできるし、ロボットなどに組み込むといったことも可能になります。しかも四国めたん、ずんだもんの声を使う場合、クレジットに「Voice:四国めたん」「Voice:ずんだもん」と記載すれば商用でも非商用でも申請無しで無料で使用することができるようにしたので、さまざまな応用ができるはずだ、と考えています。
 ずんだもんのキャラクタ
ずんだもんのキャラクタ
--利用マシンをWindowsに限定すると、少し制約が出るかもしれませんが、このVOICEVOXはMacやAndroid、またLinuxなど、ほかのOSに持っていくことは容易にできるものなのでしょうか?
ヒロシバ:音声合成エンジンはWebサーバーとして分離できる形に作っているので、計算リソースさえあればそのままWebクラウド版が作れます。ブラウザからクラウド版を利用すれば、MacでもAndroidでも自由に使えるようになるはずです。
--今大きく盛り上がっているTTSの世界ですが、無料でここまでのクオリティのものが出てしまうと、有料版が売れなくなってしまう心配はないですか?特に小田さんの場合、有料版もいろいろ手掛けているので、自分の首を絞めていることにならないのでしょうか?
小田:無償版の登場が有償版を滅ぼすことはないだろうと考えています。それよりも、このまま放置していても、無償版はどうせ出てきます。ディープラーニングの世界は日々進化しており、いろいろなところが参入してきています。たとえばGoogleなどが、APIを叩けばすぐに使える非常に安いもの、または無償のものをここ1、2年で出してくるのでは……と危惧しているのです。せっかく日本の音声合成界が盛り上がっているのに、外資に全部やられてしまっては困ります。放置して置いたら、やられてしまうので、どうせ出てくるなら、早く手を打っておいたほうがいいと考え、四国めたん、ずんだもんを無料で使えるよう調整しました。
--TTS自体は50年以上の歴史があるし、もともとはアメリカでスタートしたものではありますが、昨今の日本のTTSは独自の文化として進展してきていますから、そこを守っていくという意義は大きそうですね。でも、実際このVOICEVOXをどのような使い方をしてほしいですか?
ヒロシバ:キャラクターを活用したい方には、特に動画制作に使ってほしいですね。よくニコニコ動画を見ているので、VOICEVOX発のキャラクターがニコ動のランキングに並ぶ日が来てくれるととても嬉しいなと思います。
小田:さまざまな使い方が考えられると思いますが、将来的には地方での観光情報などのシステムに活用してもらえたらいいな、と思っています。どの地域でも、観光に関する文字情報はあるけれど、声がないのが実態。これを実際に人が読んで録音していく……となると莫大な予算が必要になってきますが、TTSであればテキスト情報さえあれば、簡単にしゃべらせることが可能です。ここに対話型のシステムなどを組み合わせれば、さまざまな応用ができるはずです。
--現在、VOICEVOXで利用できるのは、四国めたん、ずんだもんの2キャラクタですが、今後キャラクタが増える可能性はありますか?
ヒロシバ:ぜひ増やしていきたいです。特に人気が出そうなキャラクターをどんどん増やしたいです。キャラクターを提供したい方には、ぜひそのキャラクターを世間一般に布教するために使ってほしいです。新規の音声ライブラリ作成の流れを現時点ではまだ決められていませんが、何らかの形で依頼を受け付ける、もしくは作成方法を公開したいと考えています。
--最後にDTMステーション読者のみなさんにコメントなどあればお願いします。
ヒロシバ:VOICEVOXはデザインや操作性や実行速度など、いろんな部分に課題があると思いますが、自分自身は音声ライブラリの作成に注力したく、手が足りていない状況です。VOICEVOXはオープンソースなので、誰でも開発に参加することができます。ぜひみなさんの力をお借りしたいです。また、VOICEVOXの音声合成エンジン部分はWebサーバーになっているので、外部ソフトウェアから簡単に音声合成することができます。たとえばライブコメント読み上げなどに利用出来ると思います。詳しくはエンジンのドキュメントをご参照ください。
小田:四国めたん、ずんだもんともに、クレジットさえ記載いただければ、商用を含め、ご自由に使っていただくことができるので、まずは一度試してみてください。その上で、ぜひいろいろなアイディアで活用していただけると嬉しいですね。
ーーありがとうございました。
【関連情報】
VOICEVOX情報
VOICEVOXソフトウェアのソースコード
音声合成エンジンのソースコード
ITAコーパス マルチモーダルデータベース


コメント