
昨年YAMAHAが発表した「HEARTalk」(ハートーク)という技術をご存知ですか?これは機械による音声合成において、イントネーションを人に合わせることで、自然で心がこもった感じの応答を実現するユニークな技術です。当時、まだ技術発表という感じではありましたが、私が書いているAV Watchの連載記事でも「機械と心の通った対話が実現? ヤマハの自然応答技術HEARTalkが目指すもの」とレポートしたことがありました。
そのHEARTalkのシステムがついに一般に向けて発売されることになりました。一般ユーザー向けというよりも、いわゆるMake市場向け、つまり自作・工作・開発好きな人に向けての回路基板、HEARTalk UU-001という製品での発売となるのですが、ちょっと衝撃的ともいえるすごいものになっていました。DTMとは若干方向性が違うかもしれませんが、音モノとして非常に面白いものだったので、実演のビデオを見ながら、これがどんなものなのか紹介してみたいと思います。

6月7日より発売されるHEARTalkの基板。左から宇田道信さん、松原弘明さん、浦純也さん
近年、音声合成の技術は非常に進歩してきて、生活のさまざまなところに入ってきています。でも、いくら滑らかな音声になったとはいえ、どうしても単調であり、機械的という印象がありますよね。その機械的な音声合成の世界に心を与えるようにするユニークな技術がHEARTalkなのです。
まずは以下のビデオをご覧になってみてください。
どうですか?ちょっとビックリしますよね!ここでデモしてくれたのはヤマハ株式会社の新規事業開発部 HEARTalkグループの浦純也さん。浦さんによると、ここでの会話は、基本的なシナリオは決まっているけれど、人が機械側に合わせているのではなく、人の発する声に応じて、機械がしゃべっているとのこと。

HEARTalkグループの浦純也さん
もう少し具体的にいえば、人がしゃべる言葉の発音・イントネーションを認識した上で、機械側がしゃべるタイミングや人の問いかけにマッチした「うーんと」とか「えーっと」といった表現をしているそうです。従来の音声合成とは明らかに異なる世界のようですが、どうしてこんなことができるのでしょうか?

HEARTalkグループ主幹の松原弘明さん
HEARTalkグループ主幹の松原弘明さんは「音声合成・対話システムはどんどん進化していますが、たとえばカーナビやSiriなどと対話すると、機械の声とすぐに分かってしまう不自然さがあります。人間同士の会話だと、話し相手の声の強弱、音程、間、抑揚といった韻律などを感じ取って、応答者も話し方を細かく変化させています。実はこれが心が通った会話では大変重要なんです。でも対話システムなどの場合は、話し相手の韻律を無視して応答します。つまり相手が嬉しそうに話しているのに、機械は暗い印象の抑揚のない低い声で返事をしたり、逆に相手が悲しそうなのに高く強い明るい声で返事したりしてしまうわけです。そうするとどうしても不自然な会話になってしまいますよね」と話します。
「そこで人間の呼びかけの韻律をリアルタイムに解析し、応答に適した自然な韻律を導出することができるようにしたシステムが、このHEARTalkなのです」と松原さん。普段、会話に音程があると意識をすることはあまりないですが、音程の動きを見た上で機械が人に調子を合わせるようにしているのだとか……。浦さんはもうひとつシンプルなデモを見せてくれました。
単純に「おはよう」を繰り返しているだけですが、ルールにしたがって発音させると、すごく自然に聴こえてきます。このような返答ができるようにするため「おはよう」という単語をド~シまでの1オクターブの12音程の音声ファイルでライブラリに登録されているために、こんなことが実現できているのですね。

浦さんによるデモで使っていたシステム。スピーカーにHEARTalk UU-001が接続されている
とはいえ、既存の音声合成に音階をつけるというのは簡単にはいきません。もちろん、ピッチシフトなどを使う方法はありますが、自然に聴こえるようするのは事実上厳しい。そこで、松原さん、浦さんたちのチームが思いついたのが、フィラー=FILLERと呼ばれる「つなぎ言葉」を利用するワザ。つまり「う~んと」とか「え~と」、「え?」といった言葉を利用するのです。その簡単なデモが以下のビデオです。
フィラーなしだと、いかにも人工の音声合成という機械的な印象ですが、フィラーをつけると、その後は同じなのに、ちょっと感情がこもった風に聴こえますよね。これをさらに応用したのが最初のビデオだったわけです。

HEARTalk UU-001はHEARTalkのシステムやマイクなどが搭載された小さな基板
こうしたHEARTalkのシステム、松原さんによると、現在さまざまなロボットメーカーが組み込みを行っているそうですが、実際に製品などになって登場するまでには、まだしばらく時間がかかりそうとのこと。そこで、もっと多くの人たちにこの技術を使ってもらえるように、基板にSDK(ソフトウェア開発キット)などを付属させる形での販売をスタートさせるとのことです。

HEARTalk UU-001の設計にも携わったウダー開発者の宇田道信さん
実は、その基板設計に関わったのが、DTMステーションでも何度か取材したことのあるウダーの開発者である宇田道信さん。宇田さんは、ポケットミクの開発者でもあり、ポケットミクの心臓部であるNSX-1の開発をした松原さん、浦さんとは長年の付き合いなのだとか……。
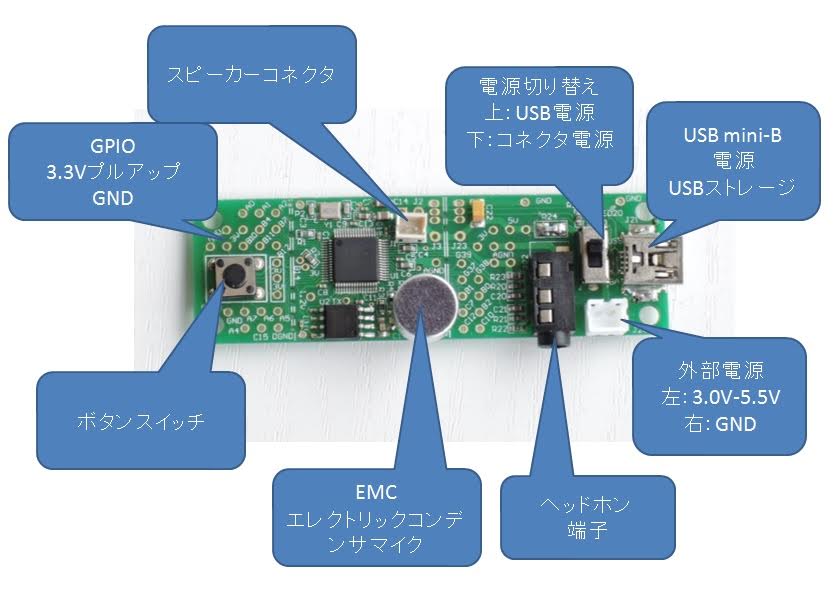
HEARTalk UU-001の基板上には電源回路、マイク、ヘッドホン・スピーカー出力などが並んでいる
小さな基板の上にHEARTalkを処理するチップやマイク、ヘッドホンやスピーカー出力、そしてPCとデータのやりとりをするためのUSB端子などが装備されています。
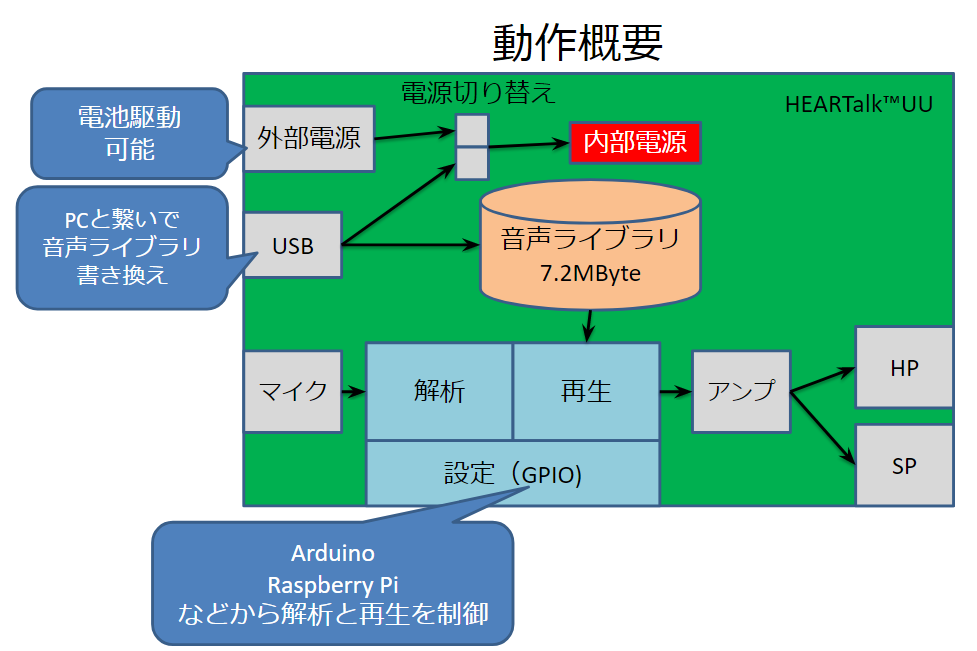
基板部分のブロックダイアグラム。このボードに電源を送れば単体でも動作するようになっている
「あらかじめサンプリングした音声をUSB経由でこのボードに転送することが可能です。ルールにしたがった計84種類・計7.2MBの音声を収録することができ、これを使って応答できるシステムになっています」と宇田さんは説明してくれるとともに、実際のデモを行ってくれました。
この機械の応答、ちょっと笑っちゃいますよね。ビデオの中でも宇田さんが説明しているとおり、ここでデモした機械は今度発売される基板を中枢に、スイッチなどを取り付け、ソフトウェアを追加してコントロールしたもの。ある程度プログラムを組むスキルは必要になりますが、こんなことができるんですね。

スイッチサイエンスから発売される基板にスイッチなどを取り付けた宇田さんによるシステム
先ほどの図にもあったとおり、この基板での解析結果などはGPIO経由で外部とのやりとりが可能になっているため、ロボットやオモチャなどに組み込んで使うことも可能です。また、スピーカーを駆動するアンプも搭載されているので、小さなスピーカーであれば、外部アンプなしに、これ単体で鳴らすこともできるようになっているのです。
また、ここに収録されているライブラリは任意のものに差し替えることが可能です。つまり、これによって自分の声で返事をするシステムができたり、自分の声で返事をするロボットの開発も可能になるわけです。これは、なかなか未来な感じで魅了的ですよね。
気になる流通形態と価格ですが、スイッチサイエンス経由で、9,180円(税込み)で本日6月6日より発売されるとのこと。興味のある方は入手して試してみてはいかがでしょうか?
なお昨年5月に発表した際にはヤマハとともにフュートレック、NTTテクノクロス(旧NTTアイティ)の3社で対話システムの開発をしている旨の発表もありました。これについて伺ってみたところ、「諸事情により当初予定よりも遅れてはいるものの、3社協業での研究開発を鋭意進めています。いずれ非常に面白いシステムを発表できると思いますので、楽しみに待っていてください」と松原さん。こちらのほうも期待ですね!
【関連情報】
HEARTalk UU-001製品情報(ウダデンシ)
【価格チェック】
◎スイッチサイエンス ⇒ HEARTalk UU-001
◎Amazon ⇒ HEARTalk UU-001


コメント