SunoAIやUdioなど、AI音楽生成ツールの普及により、誰でも簡単に楽曲を作れる時代になりました。しかし「生成されたボーカルを好きなキャラクターの歌声にしたい」というニーズに応えることができるツールは限られていたし、その精度という面でも限界があり、実現がなかなか難しいというのも事実でした。そんな中、東北ずん子・ずんだもんプロデューサーの小田恭央さんがリリースした無料ソフト「Voiceger」(ボイジャー)が11月4日にバージョン2.0へとアップデートし、大きな注目を集めています。
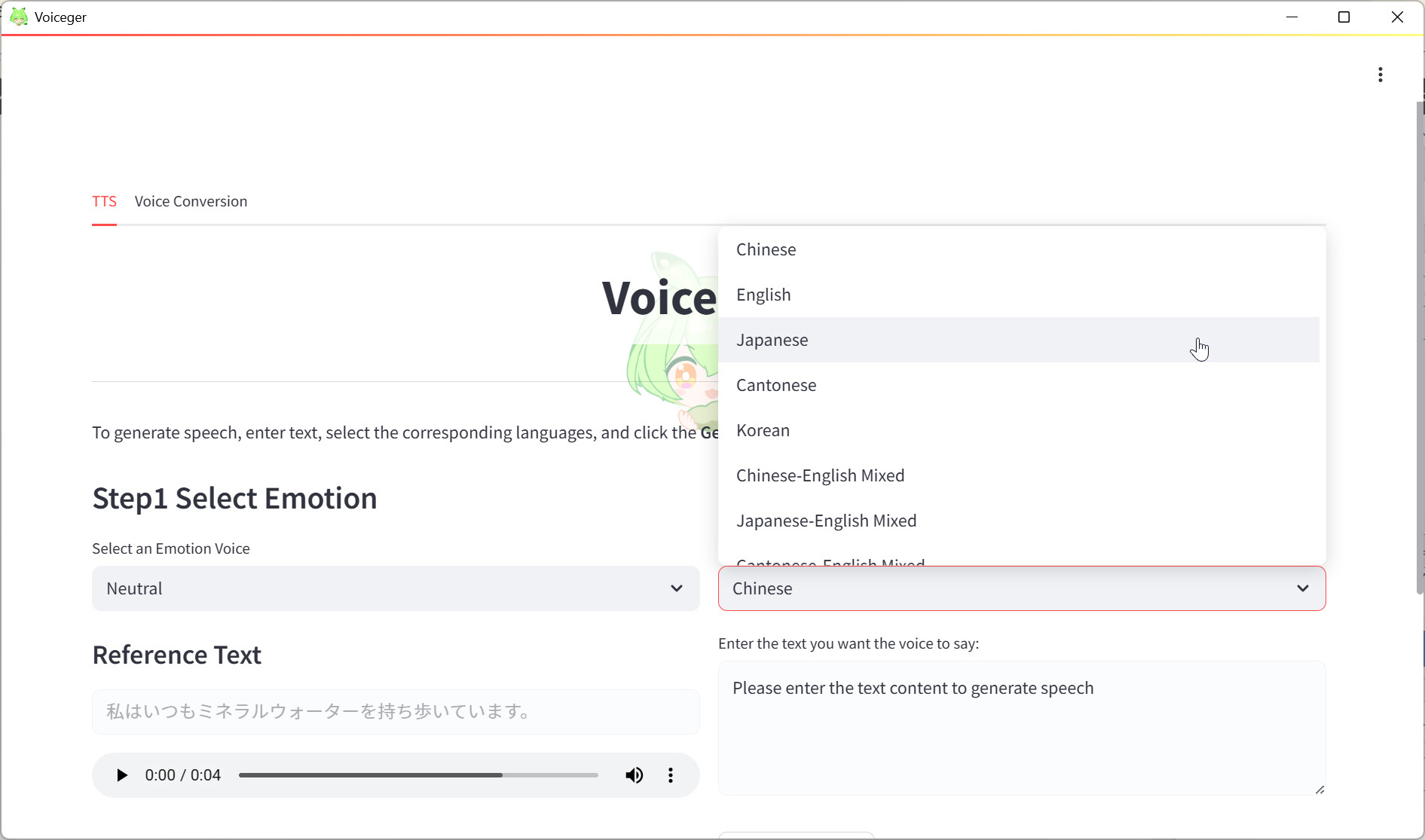
Voiceger自体は多国語対応のTTS(=Text to Speech:文字を入力するとしゃべるソフト)として今年8月5日にリリースされて話題になっていたフリーのソフトですが、今回、新たに歌声変換機能「Voice Conversion」を搭載し、あらゆる歌声をずんだもんの声に変換できるようになりました。使い方は驚くほどシンプルで、MP3やWAVファイルをドラッグ&ドロップするだけ。歌い方や表現はそのままに、声だけをずんだもんに変えてくれます。ボカロ、AI生成楽曲、人間の歌声など、どんな音源でも対応可能。さらにクレジット表記さえすれば商用利用も無料という太っ腹な仕様です。音楽制作の新しい可能性を切り開くこのソフトを詳しく紹介しましょう。
さまざまな歌声をずんだもんの歌声に変換してしまう無料ソフト、Voiceger
ドラッグ&ドロップだけの簡単操作
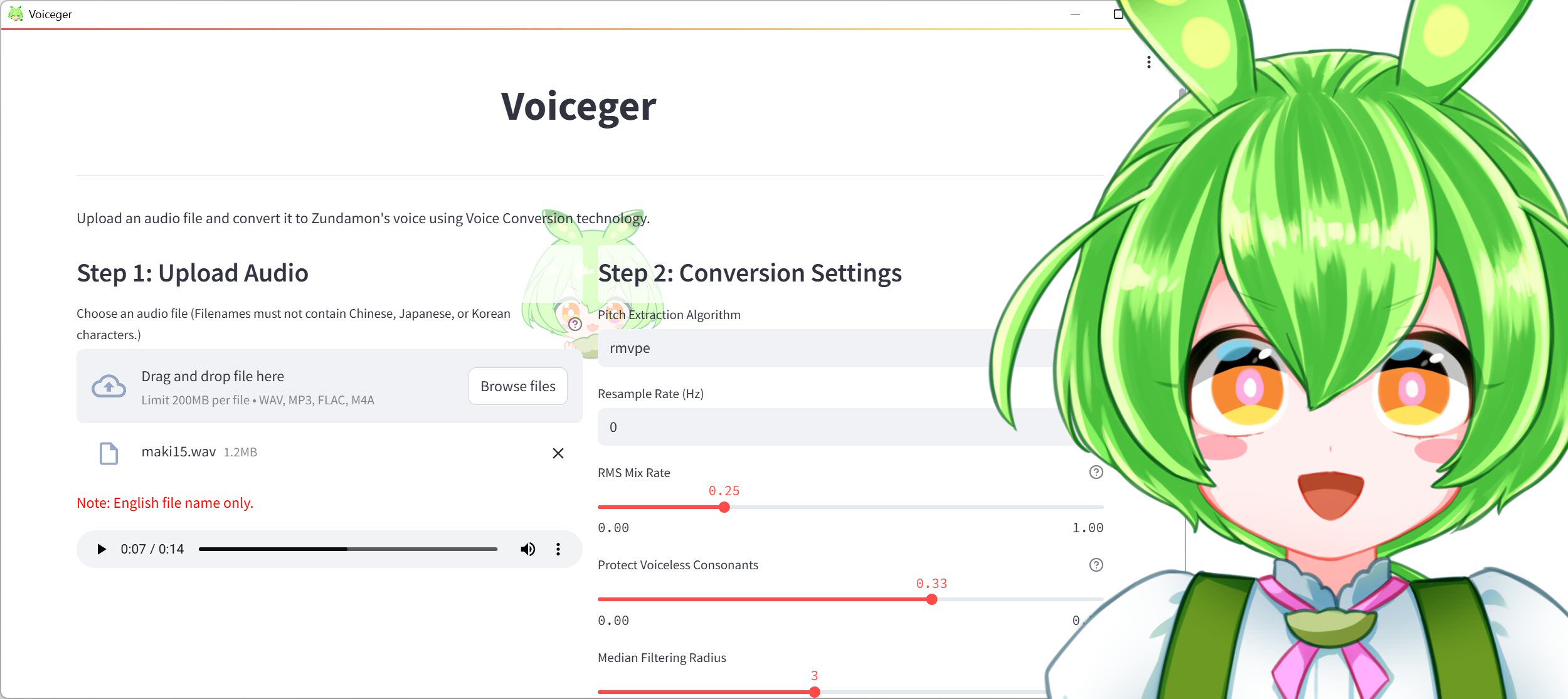
Voicegerは、音声ファイルを読み込むだけでずんだもんの歌声に変換できるWindowsアプリケーションです。起動すると「TTS」と「Voice Conversion」の2つのタブが表示されます。TTSは以前から搭載されていた多言語テキスト読み上げ機能(8月5日リリース)で、今回新たに追加されたのが「Voice Conversion」、つまり歌声変換機能です。
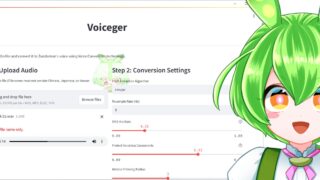
Voicegerを起動後、Voice Conversionタブをクリック
使い方は極めてシンプルです。Voice Conversionタブを開き、変換したい音声ファイル(WAV、MP3、FLAC、M4A形式に対応、上限200MB)をドラッグ&ドロップするだけ。パラメータは基本的にデフォルト設定のままで問題なく、変換ボタンを押せば処理が始まります。出力されるのはモノラルのWAVファイルで、サンプリングレートは入力ファイルのものがそのまま維持されます。
小田さんは開発の背景についてこう語ります。「今って歌声の音声合成技術が急に進化していて、さまざまなソフトが作れるようになりました。ラップが歌えるようになったり、演歌が歌えるようになったり……。でも目的に合わせて、これらを全部声優さんに歌ってもらってうちでたくさん作っていく、というのには無理があるんですよね。何かいい解決方法はないだろうか……と思って作ったのがVoicegerなんです」

つまり、Voicegerは急速に進化する音声合成技術に対応するための「フィルター」として機能する、というもの。どんな最新ツールで生成された歌声でも、Voicegerを通せばずんだもんの声になる。新しい表現手法が登場するたびに個別対応するのではなく、ユーザー側で自由に変換できる環境を整えた、というわけなのです。
多彩なユースケース
Voicegerの最も注目すべき点は、その応用範囲の広さでしょう。いくつかの具体的なユースケースを見てみましょう。
1. AI生成楽曲との組み合わせ
Suno AIなどのAI音楽生成サービスで楽曲を作成した際、生成されたボーカルをそのまま使うこともできますが、「もっと好きなキャラクターの声で歌わせたい」と思うことも多いはずです。最近のAIツールは楽曲を複数のトラックに分離するSTEM出力に対応しているため、ボーカルトラックだけを抽出してVoicegerに入力すれば、簡単にずんだもんバージョンが完成します。
2. クラシックなボカロ曲の再現
初音ミクやGUMIなど、往年のボカロで制作された楽曲のボーカルトラックをVoicegerに通せば、独特のボカロらしい歌い方はそのままに、ずんだもんの声で歌わせることができます。ボカロ特有の機械的な抑揚や歌い回しの癖も保持されるため、「ボカロテイストのずんだもん」という新しい表現が可能になります。
3. ラップ、演歌、ロックなど多ジャンル対応
ジャンルの幅も広く、ラップ、ロック、演歌など様々なジャンルに対応。これまで特定のキャラクターでしか表現できなかったジャンルも、Voicegerを使えばずんだもんで表現できるようになります。
4. 多言語対応
日本語だけでなく、英語や中国語など多言語の歌声も変換できます。ただし「ベースになる母音や子音に対応した音素が入ってない言語になればなるほどちょっと微妙になりやすい」とのことで、学習データとの相性には留意が必要です。
![]()
もっともVoicegerでは、うまく変換できないケースもあります。最も重要なのは「コーラスなど複数の声があると大体うまくいかない」という点です。Voicegerは単一の歌声を対象としているため、事前にボーカルをモノラルで抽出しておく必要があります。また、男性ボーカルの場合は「ずんだもんの声の低いやつがあんまりいい声にならない」ため、事前にオクターブを上げておくことが推奨されます。
パラメータ設定:基本はデフォルトでOK
Voice Conversionの画面には複数のパラメータが用意されていますが、小田さん自身も「パラメータをいじることって、多分、最初ほとんどないと思う」と語っており、基本的にはデフォルト値のままで問題ありません。とはいえ、各パラメータの意味を理解しておくことで、より細かな調整が可能になります。
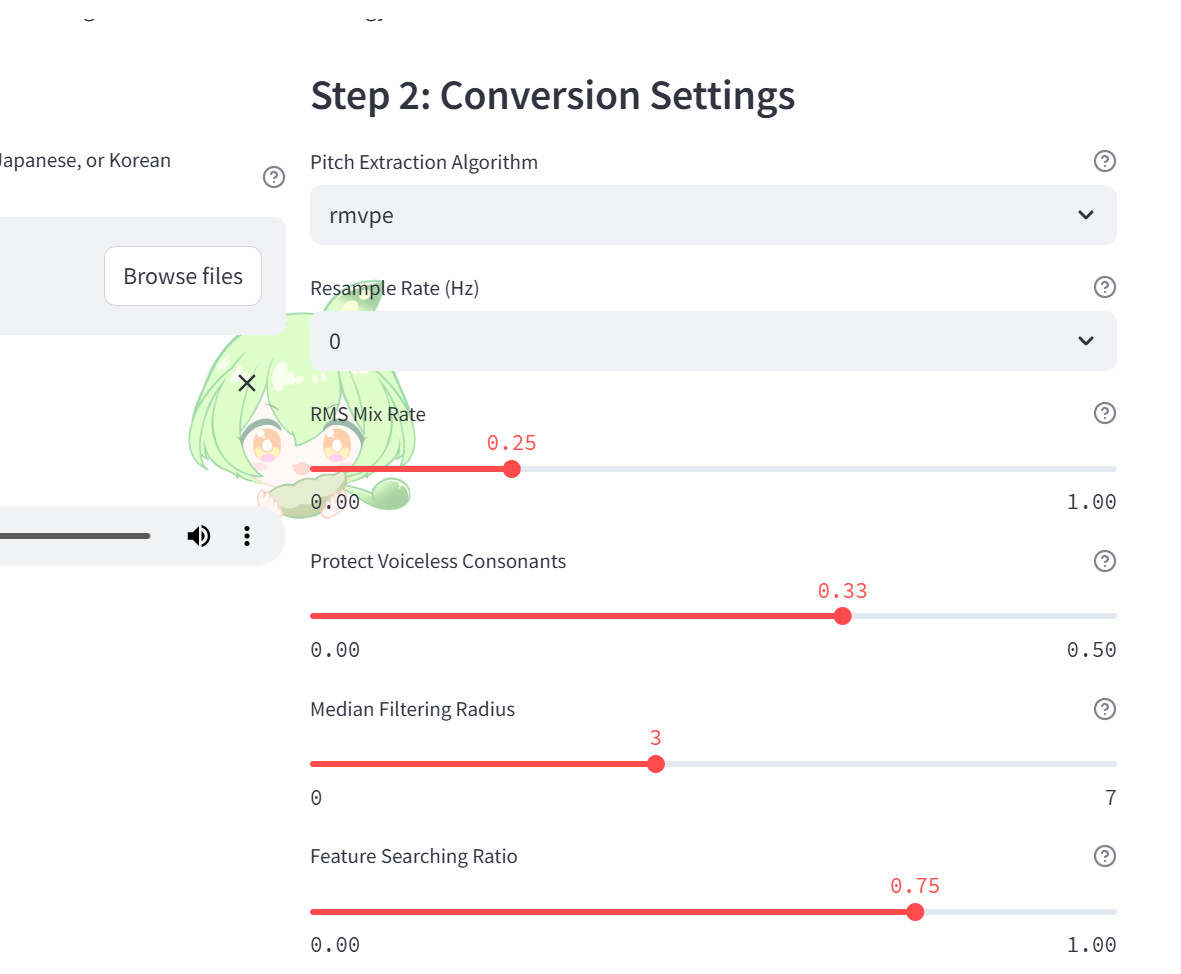
| パラメータ名 | 説明 | デフォルト値 |
|---|---|---|
| Pitch Extraction Algorithm | ピッチ抽出アルゴリズム(RMVPEは高速、Crepeは高精度) | rmvpe |
| Resample Rate (Hz) | 出力サンプリングレート(0で元のレートを維持) | 0 |
| RMS Mix Rate | 音量エンベロープのミキシング制御 | 0.25 |
| Protect Voiceless Consonants | 無声子音とブレス音の保護 | 0.33 |
| Median Filtering Radius | F0カーブのスムージング半径 | 3 |
| Feature Searching Ratio | インデックス特徴検索の比率 | 0.75 |
画面内の各パラメータ名の横にある「?」アイコンをクリックすると、英語での詳細説明が表示されます。細かく調整したい場合はそちらも参考にするとよいでしょう。
技術背景と開発哲学
Voicegerの歌声変換機能は、「RVC-Project/Retrieval-based-Voice-Conversion-WebUI」というオープンソースプロジェクトをベースに、ずんだもんの歌声データでファインチューニングを行ったものです。さまざまなライブラリが組み込まれているため、システムの制約として「ASCII文字以外が受け付けない」という仕様になっています。具体的には、ファイル名、フォルダ名、インストールパスのすべてが英数字でなければなりません。日本語のファイル名やフォルダ名ではエラーが発生するため注意が必要です。
興味深いのは、Voicegerがオープンソースとして公開されている点です。公式にはWindows用のインストーラーのみが提供されていますが、コマンドラインを使えばMacやLinuxでも利用可能です。改造も自由ですが、「声の利用規約は守ってください」とのこと。
もう一つユニークなのは、小田さんの開発姿勢です。「機能自体は増やす気はあんまりないです。実験台にしたかったっていうのが、一番大きい」と語るように、Voicegerはあくまで基本的なエンジン部分を提供するツールとして位置づけられています。

無料で提供している理由について、小田さんはこう説明します。「DTM分かってる人は個別にMelodyneとか買ってお金を使う形になってるからいいんじゃないかなって思います。多分、楽譜を書けない・読めない人でも音楽をやる時代がもうすぐ来ると思うんで、その時にVoicegerをきっかけに足りない機能が多いと気付いて、DTMの有料ソフトにも手を出す人が増えてきたらいいなって思ってます」
つまり、Voicegerは音楽制作の民主化を促進するための「呼び水」なのです。このツールが広まり、多くの人が音楽制作に触れるようになれば、より高機能な有料ソフトへの需要も生まれる。そうした健全なエコシステムの形成を見据えた戦略と言えそうです。
VoicegerとVOICEBOXとの関係
読者の中には「VOICEBOXとの違いは?」と疑問に思う方もいるでしょう。これらは完全に別のプロジェクトであり、目的も異なります。
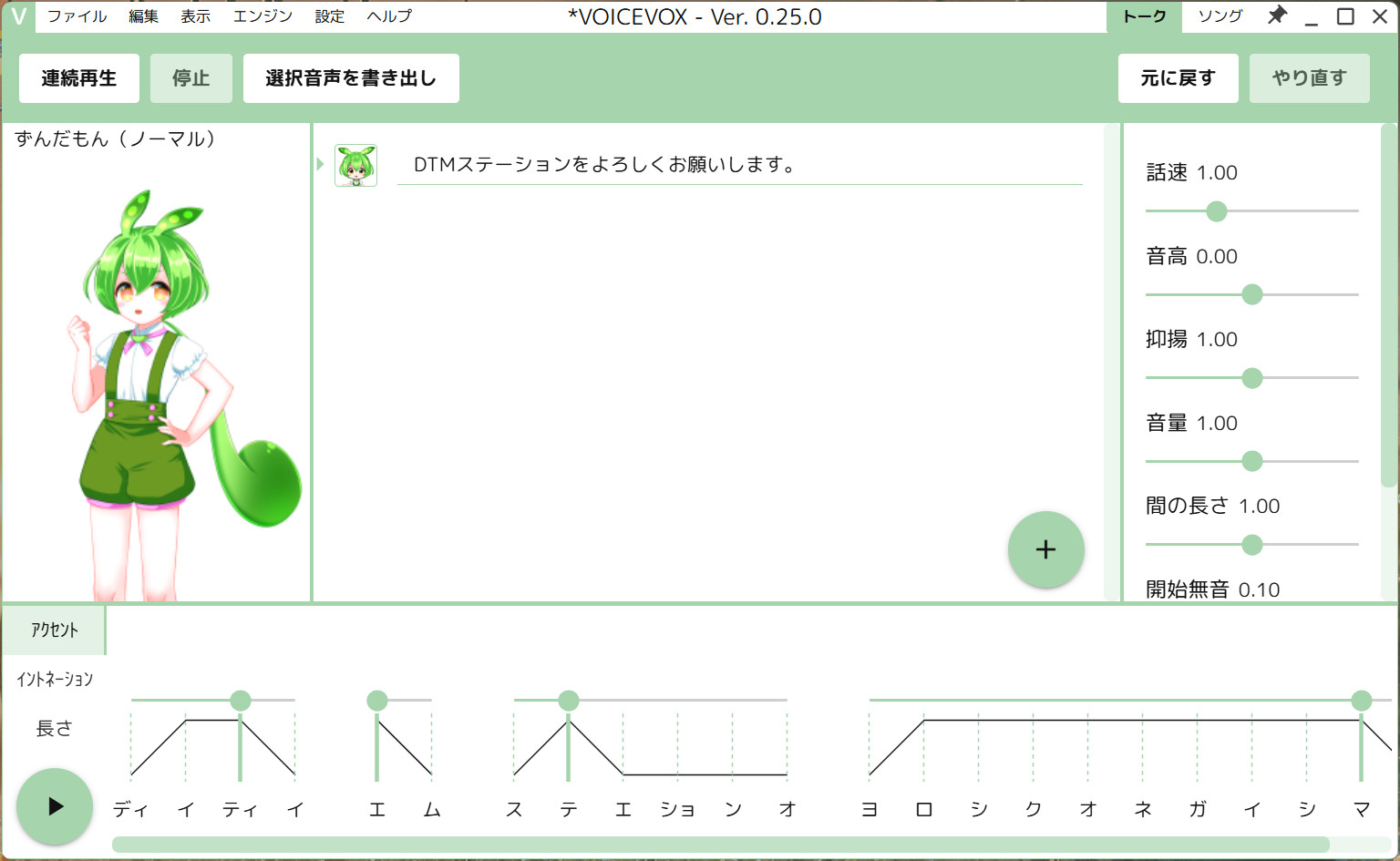
VOICEVOXはテキスト読み上げソフトとして非常に使いやすく完成度が高いツールです。VoicegerのTTS機能も同様にテキスト読み上げが可能ですが、小田さんは「VOICEVOXの方が使いやすいんで、どっちかというと多言語がなかったから多言語を補完しましょうって感じ」と説明します。つまり、VoicegerのTTSは英語、中国語、韓国語、広東語など、VOICEVOXでは対応していない言語をカバーする位置づけなのです。
声質についても違いがあります。Voicegerは元の声優の声を直接学習に使用しているため、よりナチュラルな印象になります。一方、VOICEVOXの特徴的な音質を好むファンも多いとのこと。どちらが優れているというわけではなく、用途や好みに応じて使い分けるのがよいでしょう。
利用規約と開発経緯
Voicegerで生成した音声の利用規約は非常にシンプルです。出来上がった楽曲に以下のようなクレジット表記をするだけで、商用利用も含めて自由に使用できます。
- Voiceger:Zundamon
- Voiceger:ずんだもん
この規約はVOICEVOXと同様のもので、ずんだもんの声を使った多くのツールで共通しています。クレジット表記さえ守れば、YouTubeでの収益化も、楽曲の販売も可能です。
ただし、小田さんは著作権について注意を促しています。技術的には既存曲をSTEM分解してボーカルだけ抜き出し、ずんだもんに歌わせることもできますが、それを無断で公開することは避けるべきです。個人で楽しむ分には問題ありませんが、他者の楽曲を使用する際は権利関係に十分注意しましょう。
Voicegerの開発は、2025年のクラウドファンディング「ずんだホライずん2」のストレッチゴールとして始まりました。当初は多言語TTSのオープンソース版として開発され、その後Windowsユーザーの要望に応える形でインストーラー付きの「Voiceger」としてリリースされました。TTS機能は8月5日に公開され、今回の歌声変換機能追加により、わずか3ヶ月でバージョン2.0へと進化しました。

インストーラー自体は小さなサイズですが、実際のインストール時には12GB以上のデータをダウンロードする必要があります。小田さんによれば「インストーラーに十何ギガ入れると、たぶん軽い気持ちでダウンロードした人が大変なことになる」ため、あえて分割方式を採用したとのこと。配信にはCloudflareを利用しており、「クラウドフレアだとすごい安くなるからお金取るほどじゃなくなる」という理由で無料公開が実現しています。
小田さんはユーザーコミュニティに大きな期待を寄せています。「どうしても私だと、ノーマルパターンしかチェックできていないので、Voicegerのボイスチェンジャーの得意分野・不得意分野の細かいところまで把握できていない」と語り、実際の使用例を動画などで発表してほしいとのことです。
リリース直後から、ユーザーたちはさまざまな実験を行っています。ドリルドライバーの音を変換してみたり、さまざまなジャンルの楽曲を試したり、男性ボーカルを入力してみたり。こうした多様な試みを通じて、Voicegerの得意分野や苦手分野が少しずつ明らかになっていくでしょう。
どんな歌声でもずんだもんに変換できる無料ソフト、Voiceger
Voicegerは、AI音楽生成の時代における新しいタイプのツールです。歌声合成の技術が日々進化し、次々と新しいサービスが登場する中で、「どんな歌声でもずんだもんに変換できる」というシンプルな機能は、クリエイターにとって強力な武器となります。
無料で提供され、クレジット表記だけで商用利用も可能。オープンソースなので改造も自由。使い方は極めてシンプルで、ドラッグ&ドロップするだけ。こうした敷居の低さが、音楽制作経験のない人々を含めた幅広い層に音楽制作の楽しさを伝えるきっかけになるでしょう。
小田さんの「実験してもらいたい」という言葉通り、Voicegerの真価はこれから多くのユーザーがさまざまな使い方を試していく中で明らかになっていくはずです。あなたもぜひVoicegerをダウンロードして、ずんだもんに新しい歌を歌わせてみてはいかがでしょうか。
【関連情報】
Voiceger公式サイト

コメント