だいぶ以前からテクニカルプレビュー版という形で公開されていたので、一部の方はご存知だったと思いますが、上海出身の中国人天才少年、Kanru Huaさんが開発した歌声合成ソフト、Synthesizer Vが12月25日、正式にリリースされました。これはVOCALOIDとも近い考え方のソフトで、メロディーと歌詞の情報を与えれば、歌わせることができる、というもの。
価格は79ドル(約9,000円)となっていますが、すぐに支払わなくても、ダウンロードすれば誰でもフル機能を使うことができます。またUIを日本語、英語、中国語に設定できるほか、標準で日本語、英語、中国語の歌声ライブラリが用意されているので、すぐに日本語で歌わせることも可能です。現在このSynthesizer Vが動くのはWindowsとLinux(Ubuntu)の2プラットフォーム。ただKanru HuaさんのTwitter(@khuasw)を見ると、すでにmacOS上でも動作しているようなので、近いうちにMac対応も公表されるものと思われます。実際どんなソフトなのか使ってみたので、簡単に紹介してみたいと思います。
VOCALOIDのように歌を歌わせることができる歌声合成ソフト、Synthesizer V
彗星のように登場したSynthesizer Vですが、世界の歌声合成ソフト事情をウォッチしている方なら、前身のソフトであるMoresamplerを、ご存知の方も少なくないと思います。私個人的には、Kanru Huaさんとは2年前に東京で行われたハッカソンで会ったことがあり、それ以来、何度かFacebookなどを通じてやりとりしていました。

2年前のハッカソンで会ったKanru Huaさん(右)、左から小南千明さん、渡部高士さん、江夏正晃さん
そのKanru Huaさんは、VOCALOIDの大ファンでもあり、中学生時代から理想の歌声合成を目指して開発を進めており、Moresamplerという名前でリリースしたソフトは、歌声合成の世界にも衝撃を与えたものでした。それが前身となり、まったく新たに設計し直した5世代目となるのがSynthesizer V。これまでβ運用していましたが、ようやく正式リリースとなったんですね。実際の機能はともかく、このSynthesizer Vで歌わせたデモがあるので、まずはそちらをご覧ください。
このニコニコ動画のご覧いただくとわかるとおり、このデモソングは英語で歌わせたもので、制作したのはアメリカ人ユーザーであるcilliaさん。かなりリアルな歌声であるのを実感しますよね。
前述の通り、日本語でも歌わせることができるわけですが、木村カエラの「Butterfly」を歌わせたデモもあるので、こちらも参考になると思います。
いかがですか?こちらは、アマノケイさん制作のもので、しっかり日本語になっているのは分かりますが、日本語の場合はVOCALOIDと比較して、やや不自然さもあるかな…という印象を持ちました。これは今回リリースされた歌声ライブラリではなく、JA-F1というβ版でのライブラリだったためかもしれませんね。
さて、このSynthesizer V、Synthesizer Vのウェブサイトからインストーラーをダウンロードして起動すれば、日本語でインストールでき、もちろん日本語のメニュー環境で使うことができるようになっています。
インストーラも日本語で動作する
またSynthesizer V本体とは別に歌声ライブラリーもインストールする必要があるのですが、フリーで使える歌声ライブラリとして
闇音レンリ(日本語)
ゲンブ(日本語)
AiKO(中国語)
の4つが用意されています(12月25日現在、AiKOは準備中)。このうち闇音レンリはもともと、歌声合成ソフトのUTAU用に作られたライブラリ。これをベースにSynthesizer V用に作り直したライブラリのようですね。
歌声ライブラリー、Elenor Forteのインストーラー
さっそく起動すると、以下のような画面が表示されます。開発者のKanru Huaさんによれば、Reaperの考え方を参考にしたとのことで、誰でも無料で使えるけれど、気に入った方には買ってもらえるよう、起動時にアラートが出るとともに一定時間待つと消え、評価版という位置づけで製品版と同様の全機能が使える仕組みになっているんですね。
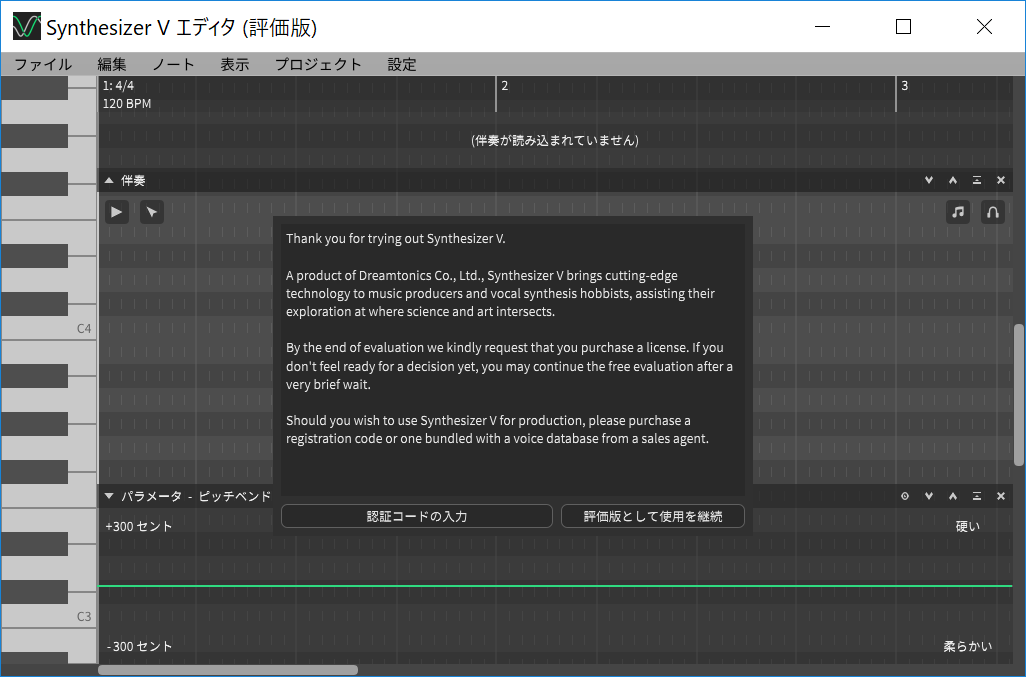
起動時に、一定時間待てば評価版として全機能を無料で使うことが可能
そのSynthesizer V、使い方は大きく2種類。一つはスタンドアロンで使っていく方法で、音符と歌詞を入力すれば、すぐに歌わせることが可能です。この際、BGMも読み込むことが可能なので、先ほどのニコニコ動画のように、伴奏つきで歌わせることができるわけです。
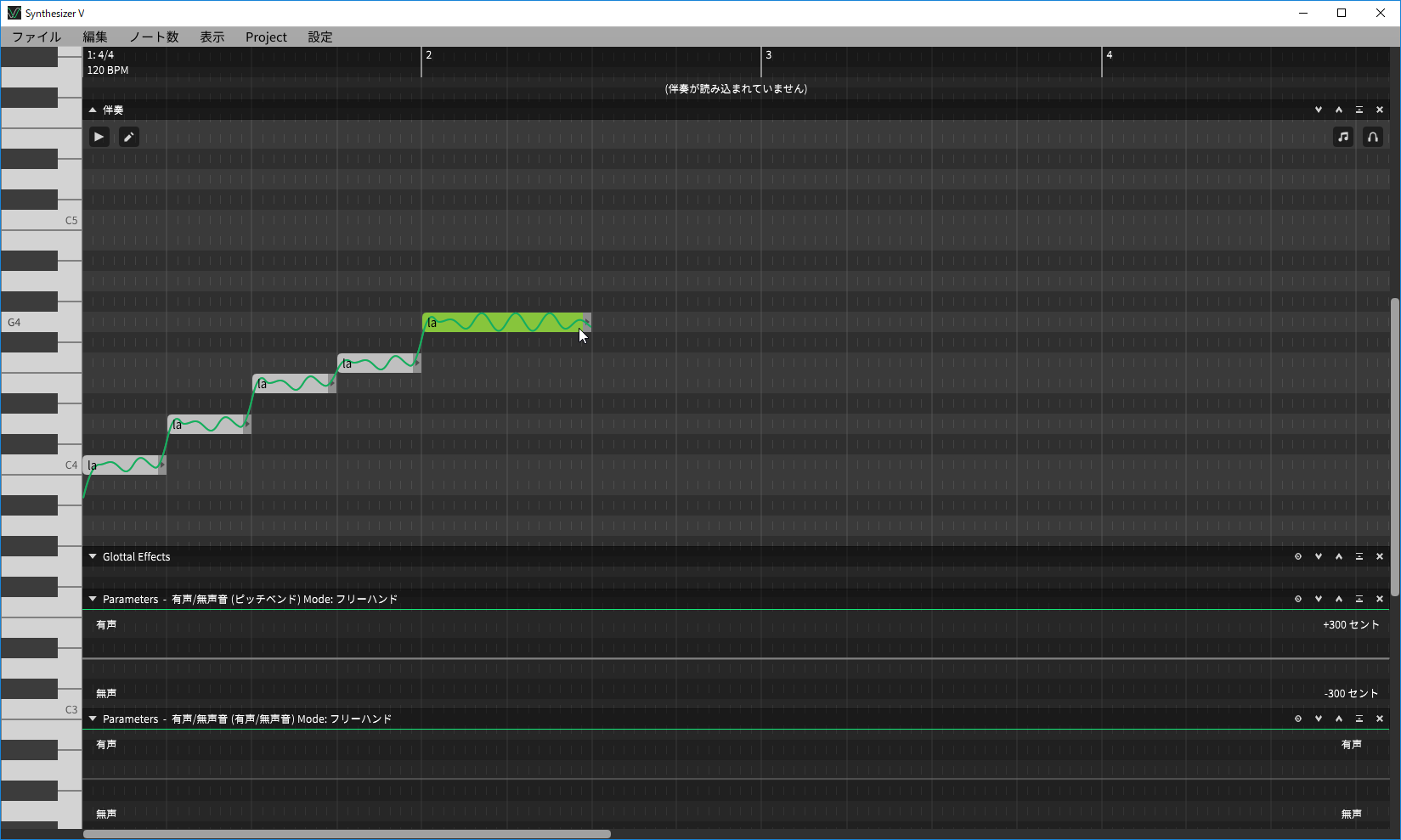
WindowsおよびUbuntuのスタンドアロンとして使うことができる
もう一つの使い方はDAWのVSTインストゥルメントのプラグインとして使う方法です。こちらはやや特殊な方式となっているので、簡単に使い方を説明しておきましょう。Synthesizer Vをインストールする際、自動的にProgram Files\Steinberg\VSTPluginsフォルダに32bit版、64bit版のDLLファイルがインストールされるようになっています。必要に応じてこのファイルを移動させたり、DAW側でフォルダを指定することで、各種DAWから利用できるようになるのです。実際にVSTインストゥルメントとしてDAW内で起動させると、Synthesizer V Pluginという小さな画面が立ち上がります。
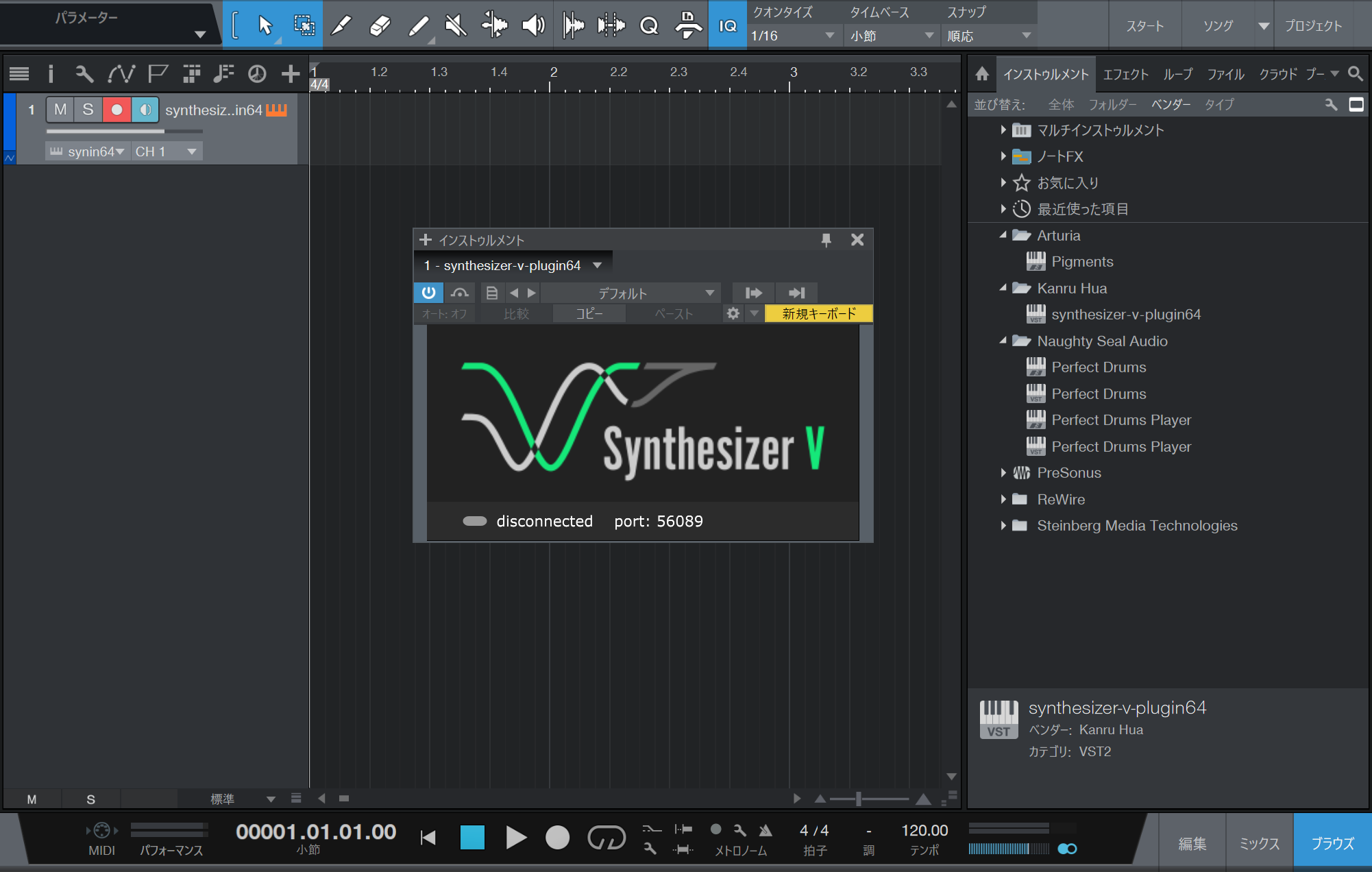
VSTインストゥルメントとして起動させると、こんな小さなウィンドウが開く
ただ、これはSynthesizer V本体ではないので、別途スタンドアロンと同様にSynthesizer Vを起動させます。
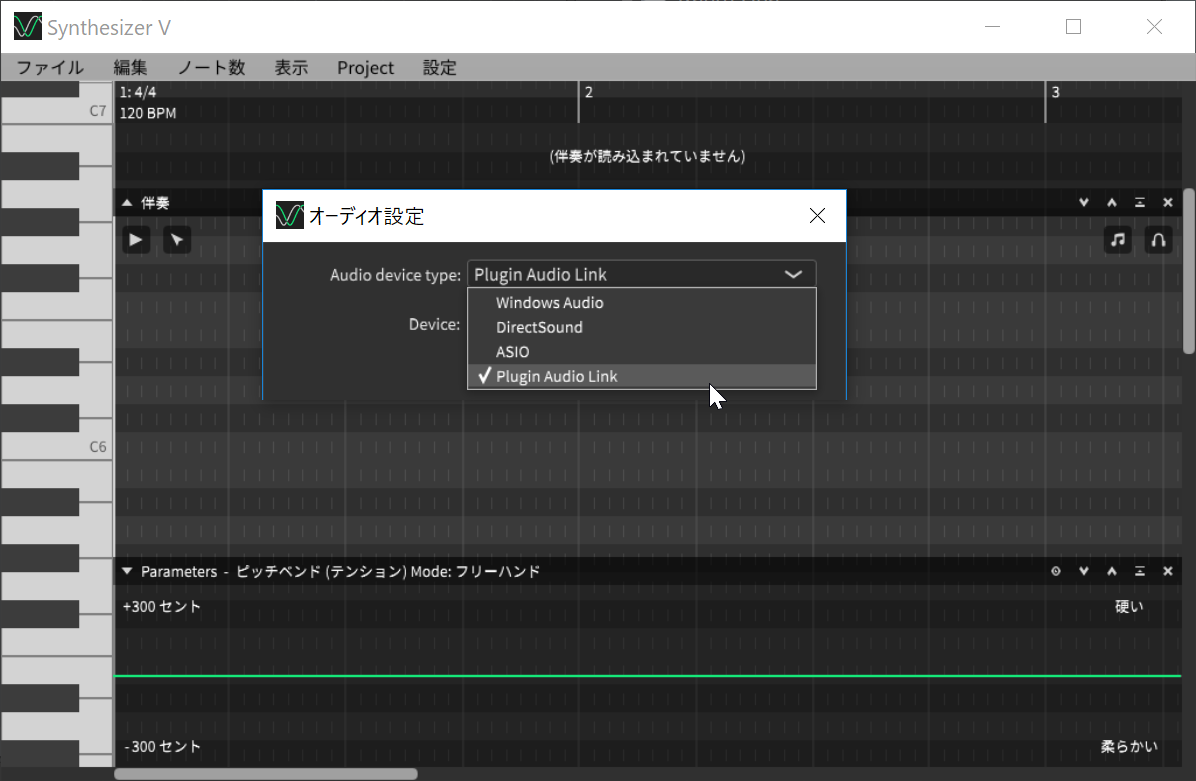
オーディオ設定をASIOなどでなく「Plugin Audio Link」にする
ここで、あらかじめオーディオデバイスの設定を「Plugin Audio Link」に設定するとともに、先ほどの小さな画面に記載されていたPort番号を、「設定」メニューの「Connect to Plugin Host」に入力すると、連携する形になっているんですね。
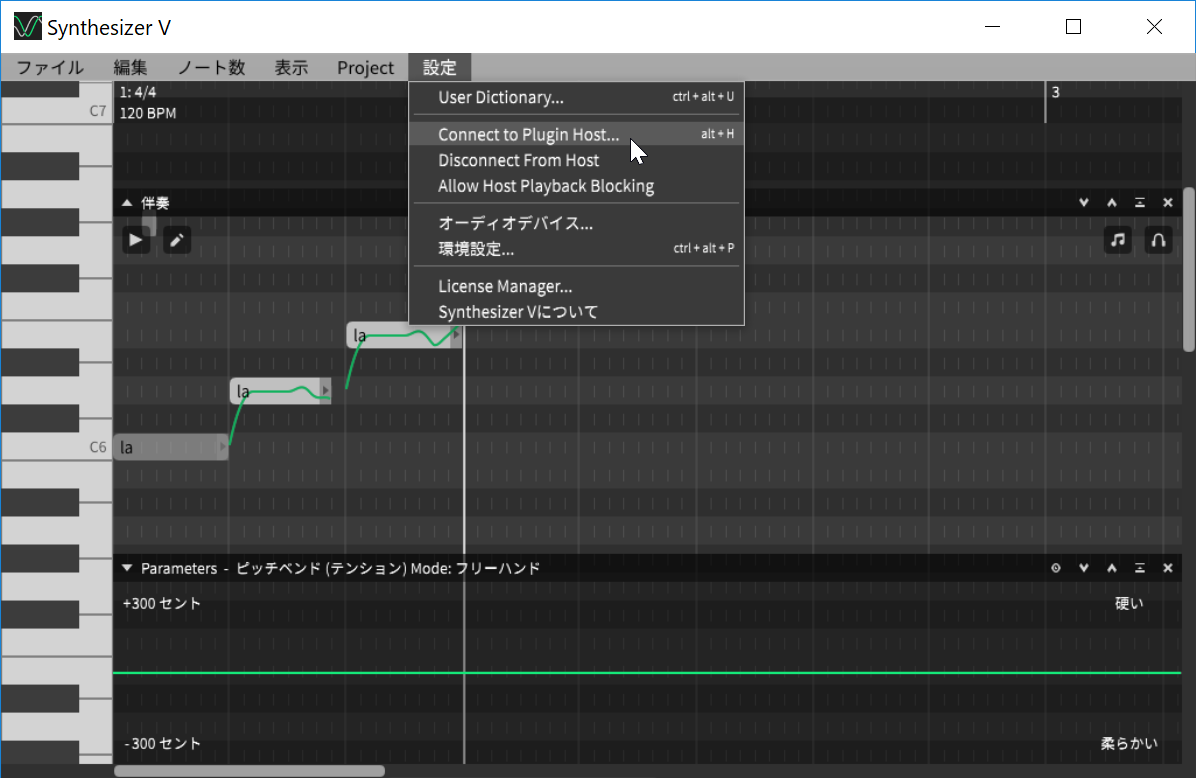
別途Synthesizer Vを起動し、Settings-PreferencesからConnect to Plugin Hostを選択
この辺の設定がやや面倒にも思いますが、あとはDAWとSynthesizer Vが同期し、Synthesizer Vの音がDAW側のトラックに流れてくるので、エフェクト処理をかけることもできれば、いったんバウンスしてオーディオファイルとして取り込むことなども可能となります。
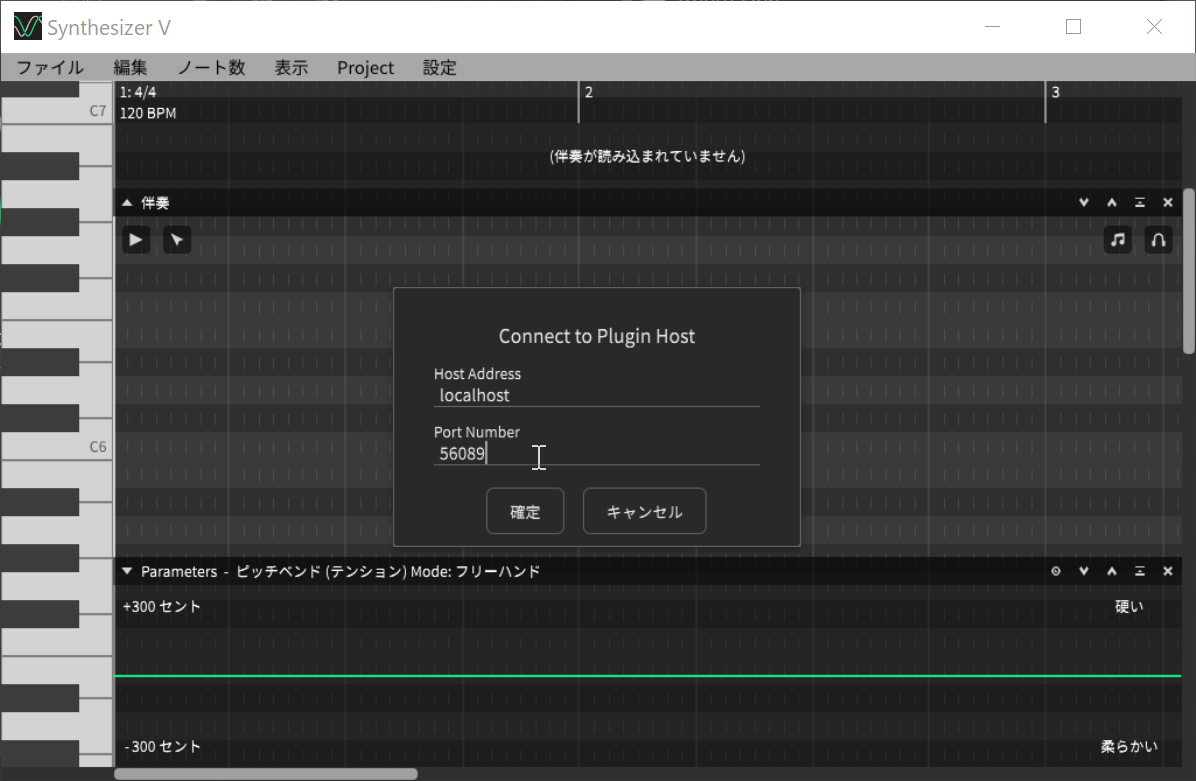
Port NumberにDAW側の小さなウィンドウに表示されていたポート番号を入力すれば連携完了
では、実際にどのように使うのか。基本的にはVOCALOID EditorやPiapro Studio、CeVIO Creative Studioなどを使ったことのある方なら、マニュアルなど見なくてもすぐに使うことができると思います。つまり、基本的な使い方は同じであって、ピアノロール画面に音符情報をマウスで入力し、そこにローマ字または平仮名を入力すれば、それですぐに歌わせることが可能です。
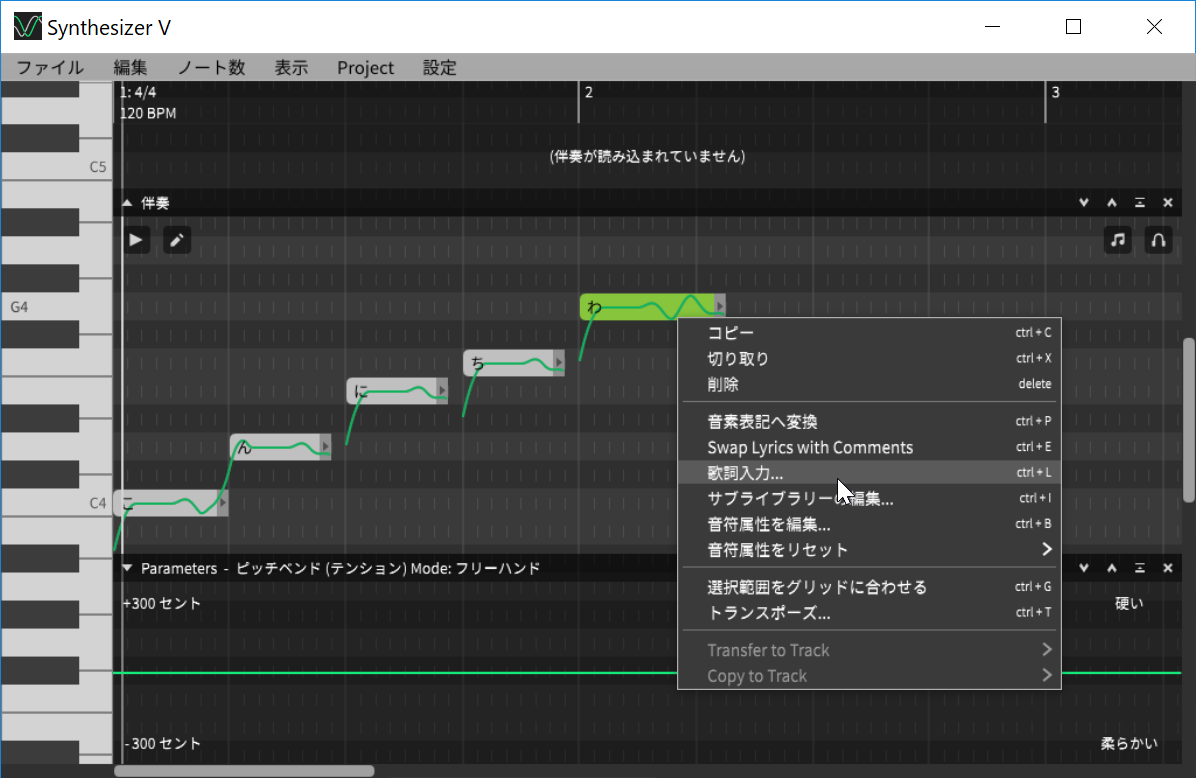
VOCALOIDなどと同様に音符を入力し、歌詞を入力すれば歌わせることができる
ただし、歌わせる前に一つだけ設定が必要となります。そう、歌声ライブラリーを指定する必要があるのです。先ほどお伝えした通り、無料の歌声ライブラリーとして、Elenor Forte(英語)と闇音レンリ(日本語)、ゲンブ(日本語)、AiKO(中国語)があるわけですが、日本語で歌わせる場合は闇音レンリまたはゲンブを「歌声ライブラリー設定」画面で指定します。
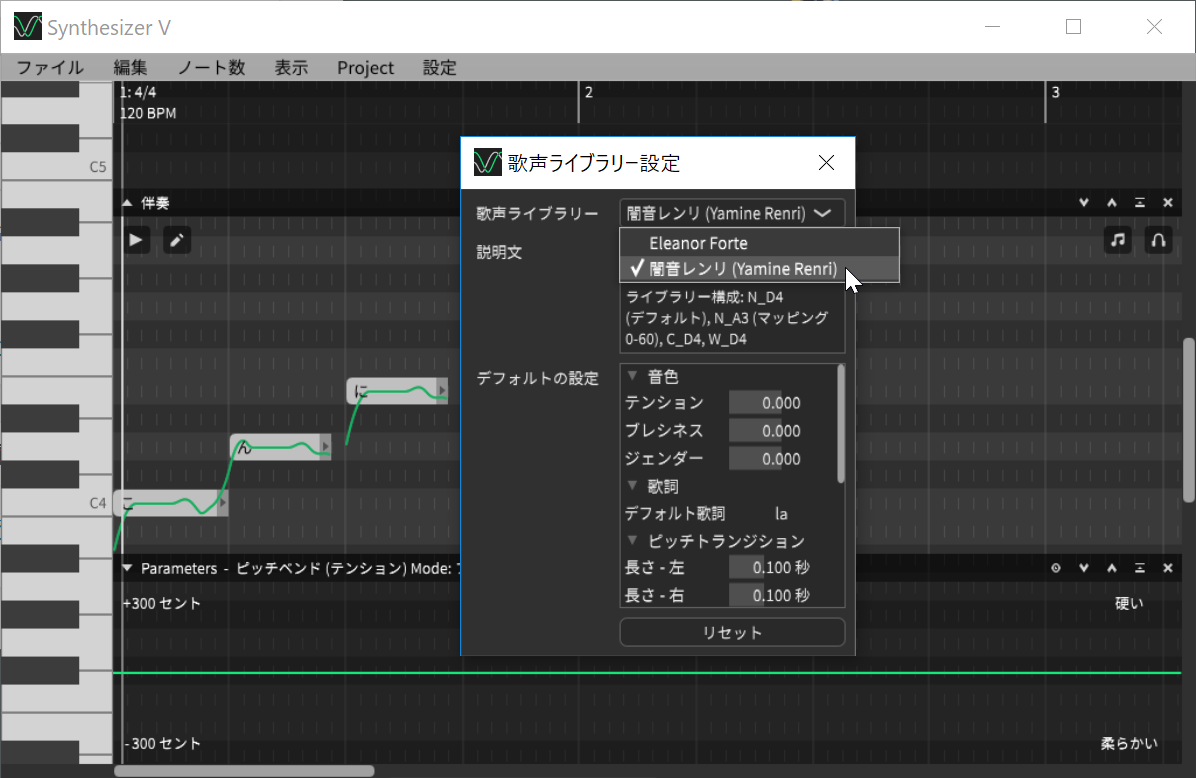 闇音レンリが日本語の歌声ライブラリーなので、これを選択する
闇音レンリが日本語の歌声ライブラリーなので、これを選択する
歌った感じは、先ほどの「Butterfly」と少し近い感じで、やや鼻声っぽい感じ。この歌声は先ほどの歌声ライブラリー設定の画面で調整することが可能です。
・テンション(声の調子)
・ブレシネス(息の量)
・ジェンダー(フォルマント)
という3つのパラメータがあり、テンションを上げると張り詰めた声になり、下げるとカスれた感じになります。ブレシネスの調整ではどのくらい息が混じっているかを変えることができ、ジェンダーは上げると男性っぽい声、下げると女性っぽい声になります。
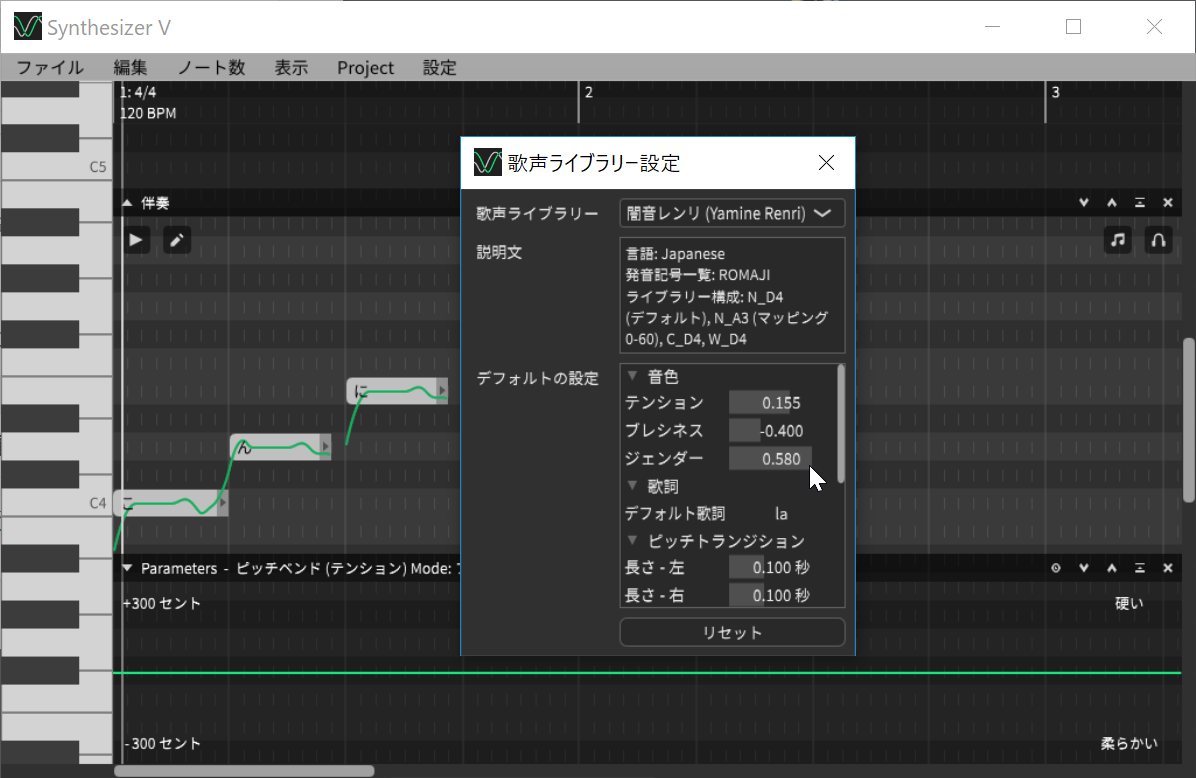
テンション、ブレシネス、ジェンダーの3つのパラメーターで声色を変化させる
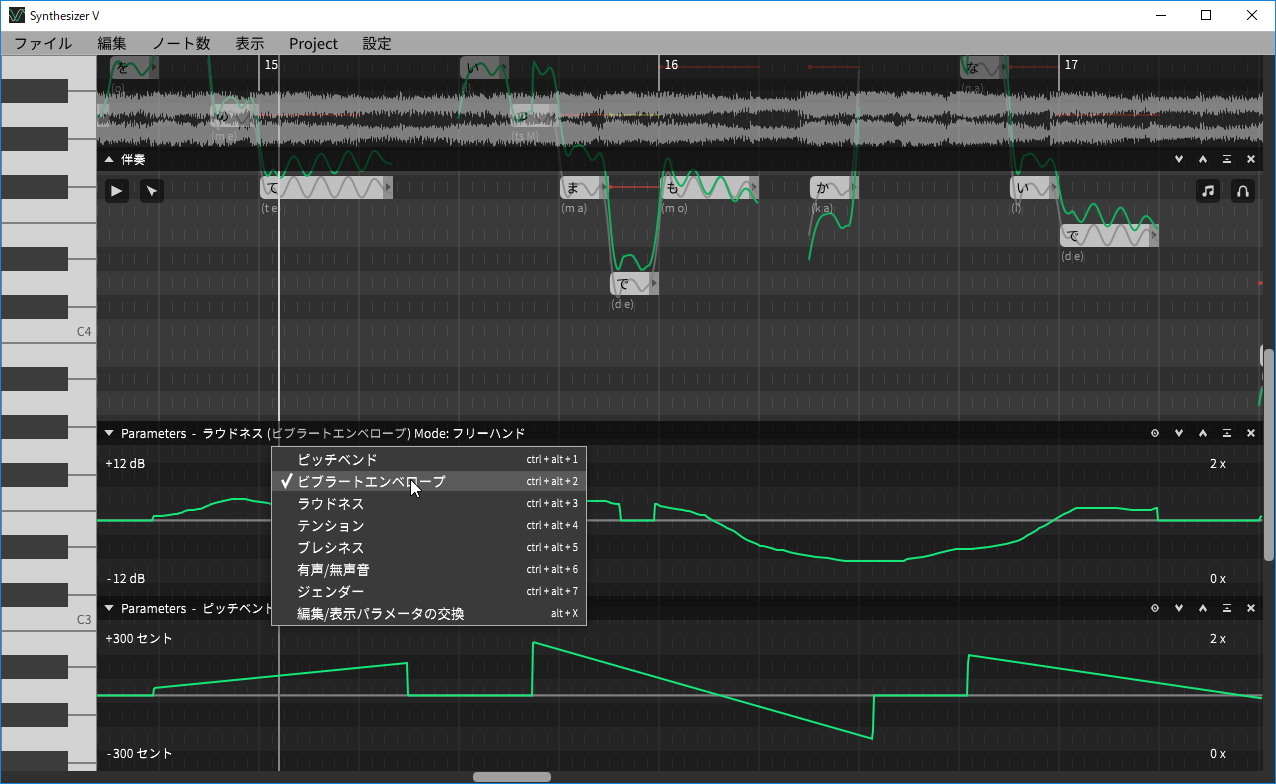
また、この歌声は固定で設定するだけでなくパラメータとして変化させることができ、その変換をグラフィカルに書き込んで設定することも可能です。この場合は上記の3つのパラメータだけでなく、ピッチ、ビブラートとエンベロープ、有声/無声といった設定も可能。無声にすると、こそこそ声になるわけですね。
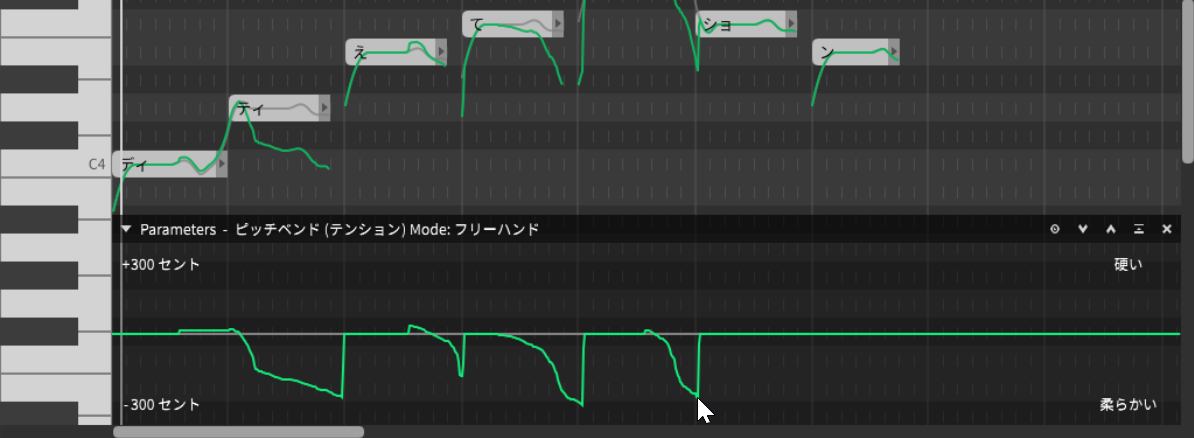
ピッチなどを書き込んで調声することもできる
いずれにせよ、使ってみればすぐに分かると思います。また、グラフィカルに描けるのは上記3つのパラメータ以外に、ピッチ、ビブラートエンベロープ、ラウドネス、有声/無声音があり、やりようによっては、かなりの調整も可能になっています。
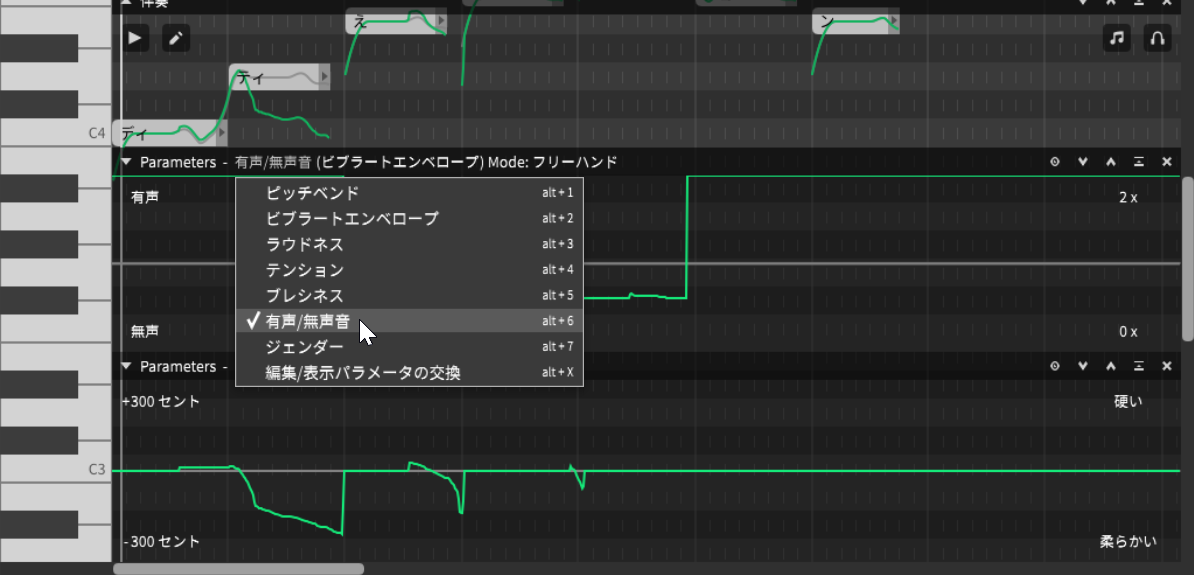
ビブラートエンベロープやラウドネス、有声/無声音といったパラメータも利用できる
また、実はこのSynthesizer Vは、VOCALOIDのVSQXファイルも読み込み可能となっているので、すでに作ったデータがあれば、それをインポートして歌わせてみるというのもありですね。もちろんMIDIファイルを読み込んで、そこに歌詞を流し込んでいくことも可能です。
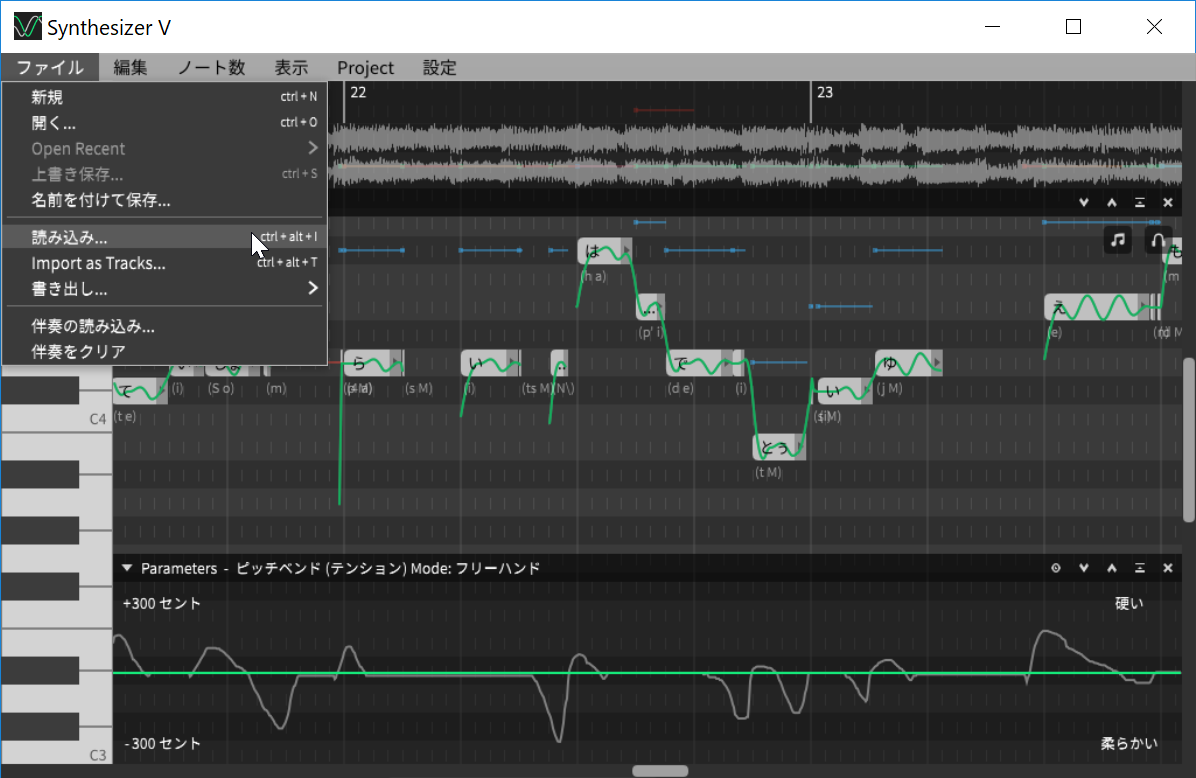
MIDIファイルや、VSQXファイルのインポートも可能
とにかくダウンロードしてインストールすればすぐに使えるというのは嬉しいところ。
そのKanru Huaさんにメールで少しインタビューしてみました。

道場破り的に参加した2年前のハッカソンで発表するKanruさん。その後、最優秀賞を受賞した
--このソフトを作ったキッカケや、開発した理由を教えてください
Kanru:中学生時代に趣味として歌声合成ソフトの開発を始めたのですが、歌声合成についてもっと深く研究しだしてからは、これが自分の使命のように感じるようになっていきました。その後は「最強の歌声合成ソフトを作りたい」という思いで開発を進め、Synthesizer Vをリリースしました。
--VOCALOIDと比較した場合、その仕組みの違いを簡単に教えてもらえますか?
Kanru:Synthesizer Vの設計思想は小さなデータ量で性能の最大化を図ることです。そのために、私はディープラーニングを利用する手法を編み出しました。ディープラーニングを使って素片接続をすることで、使うデータを減らせる、ハイブリッドアルゴリズムを開発したのです。一方分析合成アルゴリズムを工夫し、録音ごとに広い範囲をカバーできるようしたのです。データ量を減らした分、時間を節約して改良に回せるようにしたのです。業界全体がビッグデータに向かっている昨今ですが、新しいアイディアを「スモールデータ」に向けることが優位性になるのではないか、と考えています。
--今後、歌声ライブラリの追加の予定はありますか?また追加がある場合、ユーザーはどのように入手すればいいのでしょうか?
Kanru:私自身は、歌声合成のためのエンジンを改善していくことに力を入れていきたいので、ライブラリーやキャラクターを増やすためには、パートナーの協力が必要になります。まずは協力してくれるパートナーの参加するをお待ちしているところです。そのうえで、エンジンとライブラリの開発は分業していくことで、より高品質な製品が作れるはずだと考えています。そのため、配布している歌声ライブラリ以外は、パートナー側から流通することになると思います。
--ユーザーがライブラリを自分で作るということは可能ですか?
Kanru:その点は非常によく質問を受けています。これについては技術的な点よりも、ビジネス的な展開によって変わってくると思います。パートナーが開発する商業用のライブラリーと個人のライブラリーを共存させることが可能なエコシステムをどう作っていけるのか、探っていきたいと思っています。
こんなSynthesizer Vという、まったく新しい歌声合成ソフト、とりあえず無料で使うことができるので、試してみてはいかがでしょうか?
【関連情報】

コメント
すごく失礼ですが、「中国人か。またコピーじぇねぇのか?」と思ったのですが、これ、すごいですね。
インタビューの回答も芯があって、見直しました。
近年の中国はとても好きにはなれないけど、彼は応援したい!
Kanru Huaさんの可能性や情熱に水を差す意図は全くないのですが、いくつか
思うところがあって書かせて頂きます。
長文を避けるために箇条書きにて失礼します。
・VOCALOID5になってエディター単体での販売が無くなった(今後の予定は知りえません・・・)。
・ヴォカロ人気の発端、広がりは「歌声ライブラリのヴァリエーション」に大きな要因があったから
では、という(あくまで僕個人の)考え。
・いまだにピアプロスタジオのスタンドアロンは初音ミク中国語ライブラリのみ、という現状。
・Synthesizer Vはすでに「中学生のKanru Huaさんが情熱と好奇心で、自宅で頑張って作ってる」という
無垢な推進力で進むものではなくなっているよなあ・・・という(ごめんなさい)邪推。
・記事中のKanru Huaさんの「パートナーの協力」「ビジネス的な展開」などの発言(当然ですよね)。
・無料でフル機能をすぐに使える、という事実。
「VOCALOID5のエディターとライブラリの ”実質” 抱き合わせ販売」(エディターのみとは価格が
三倍くらい違いますよね)と「商業用のライブラリーと個人のライブラリーを共存させることが
可能なエコシステム」というKanru Huaさんの考え、このふたつを並べてみた時にいろいろ
「うーん」となります。
結局長文&なんだか嫌な感じのコメントになってましたすいません。
「みんな大好き!♪」(空気感のフォロー)・・・それでは失礼します・・・
中国製というと粗悪とかコピーとかネガティブイメージが付き物ですが最近の製造業とか見ても真面目に開発し今までにない製品を作り上げる力がかなり上がって来てると感じます。
もちろん粗悪品やコピー商品も未だ多数存在していますがw
中学生から始めてここまで仕上げてくるとなるとやはり天才でしょうね。
将来が楽しみです。
使っている音声合成技術は公開されているあるいは既知のものなのでしょうか?
murakamiさん
HMMをベースにしたものかな…と思ってはいましたが、その方式についてオープンにはなっていなかったかと思います。
出音を聞くと、ボカロとはアプローチがかなり違う感じがしますね。
UTAUとも違う感じがします。たまたまなのかわかりませんが…
ボカロは初音ミクというスター音源が出たことでメジャー化したわけで、
そういうのが出てくるかどうかって感じがしますね。
UIシンプルで扱いやすいしいい音出るし
俺はかなり好きかも