オープンソース・ソフトウェアとして公開されているAI音声合成ソフトであるVOICEVOXに、9月30日、また新たなキャラクタが誕生します。今回、3つのキャラクが同時に誕生するのですが、その一つが声優の小岩井ことり(@koiwai_kotori)さんCVによるNo.7です。昨年、AI歌声合成ソフトとしてフリーウェアのNEUTRINO用にNo.7がリリースされていましたが、今度はしゃべるソフトとしての誕生となります。普通のしゃべり声である「ノーマル」と、アナウンサーが読み上げるようにしゃべる「アナウンス」、そして絵本を読み聞かせるように読む「読み聞かせ」の3種類となっています。
このNo.7のプロジェクトは明治大学の専任准教授、森勢将雅(@m_morise)先生を中心に研究・開発されているもので、小岩井ことりさんもここに積極的に参加しつつ、私・藤本健も関わる形で進めてきました。ここで作られたデータベースを元に、VOICEVOXの中心人物であるヒロシバ(@hiho_karuta)さんがライブラリとして仕上げ、この度リリースされることになったのです。が、実は今回のVOICEVOXとしてのリリースは、No.7プロジェクトの序章に過ぎず、今後さらに驚くような展開になっていく予定なのです。実際、音声合成の世界で何が起きようとしているのか、森勢先生と小岩井ことりさんにお話しを伺ってみました。
 No.7のプロジェクトを進めている森勢将雅先生、小岩井ことりさんにインタビューした
No.7のプロジェクトを進めている森勢将雅先生、小岩井ことりさんにインタビューした
No.7については昨年、「小岩井ことりさん作詞・作曲・歌唱のDB公開で、AI歌声合成の民主化へ躍進。NEUTRINOの新キャラクタ『No.7』がリリースへ」や「小岩井ことりさんの歌声を人工知能で完全に実現!? 本人も自分そのものと認めるソフト完成への裏舞台」という記事でも紹介していましたが、その後、No.7をしゃべらせるための収録が続けられ、2022年2月にようやく収録が終わったところです。それから、データベース化の作業が進められ、今回VOICEVOXとしてリリースされたわけです。そのVOICEVOX版No.7の紹介ビデオができたので、こちらをご覧になると、そのクオリティーが分かると思います。
小岩井さんの声を知っている人ならわかると思いますが、これ、本人そのものですよね。というわけで、さっそくお二人にインタビューしていきました。
--今回の収録、かなり大変だったようですが、どんなことをしていたのですか?
森勢:小岩井さんには、かなりの苦行を強いた形になりましたが、その収録を行った元のコーパス文は4,600文におよびます。このうち3,600は私が自作していますが、僕自身の語彙に偏るのもよくないので、残り1,000を5人に分担してもらい、200文ずつ作ってもらいました。このコーパス文についてはパブリックドメインとして公開している(https://github.com/mmorise/rohan4600)ので、興味のある方はぜひご覧いただければと思います。
 No.7プロジェクトの中心人物である明治大学 専任准教授の森勢将雅先生
No.7プロジェクトの中心人物である明治大学 専任准教授の森勢将雅先生
--少し読んでみましたが、読むのが難しいというか、よく意味が分からない文が結構あるというか……。
森勢:そうですね。最初の文は「0001:流し斬りが完全に入れば、デバフの効果が付与される」となっていたり、「4401:溥儀によって 治められましたが、 実態は 傀儡政権だったとされています。」とか最後は「4600:ミュートになっていたことに気づかず、恥ずかしい思いをした。」といった感じで、まったくの呪文にはならないように、文は作っています。このコーパス、22のサブセットで構築されるものですが、各文について「常用漢字を必ず一つ入れる」とか「ヴァとかツァを1個入れる」などの条件を作っており、私自身でプログラムを書いて自動生成した上で調整しているんです。そのため、必ずしもしっかりした意味をもった文章になっているわけではないのです。
 今回の収録に用いた4,600あるコーパス文の冒頭
今回の収録に用いた4,600あるコーパス文の冒頭
--小岩井さんは、これを読んでいったわけですね。実際、いつごろから収録していたのですか?
小岩井:なかなか収録に入れず、実際にレコーディングを始めたのは昨年12月からでした。とにかく2月には納品しなくてはいけないという指示を森勢先生からいただいていたので、頑張りました! 4,600文とはいえ、ノーマル(当初デフォルトと呼んでました)、アナウンス、読み聞かせ(これはポエムとかポエティックと呼んでました!)の3感情で読んでいかなくてはならないので、4,600x3=13,800あり、かなり膨大な作業でしたね。

約3か月間で膨大なコーパス文のレコーディングをしていったという小岩井ことりさん
--当然、何日にもかけて作業していったと思いますが、どのくらいの時間がかかったのですか?
小岩井:200文を収録するのに3つの声で収録するから、2時間程度はかかってしまいます。1文1文区切ってレコーディングするのではなく、まとめて読んでいって、あとで森勢先生に渡す前に、1文1文切り取る作業をしていました。その際、音も聴きながら間違いがないか、チェックをしているのですが、そこそこミスは出てしまうので、次のタイミングで再収録をしています。
森勢:1つの文に平均28モーラ(文字)入っているので、どうしてもそれなりの時間がかかってしまいますね。
--人って、日によって、声のトーンが違ったりしますが、それを均一化できる声優さんって仕事はやっぱりすごいな、と。
小岩井:最初に声のトーンを決める際に、森勢先生に立ち会っていただいて、収録したリファレンスがあるんです。2ページ読むごとに必ず1度リファレンスを聴いて、声を合わせるようにしています。1ページに20文くらいあるので、40文置きに聴く形ですね。コーパスの原稿がPDFファイルとして用意されていますが、基本的には10ページ分=200文ごとに1個のファイルになっているので、このファイル単位で、ポエティック(読み聞かせ)、デフォルト(ノーマル)、アナウンサー(アナウンス)の順番に収録していきました。というのもポエティックが一番ゆっくりなので、ここから始め、一番難易度の高いアナウンサーを最後にする……という録り方ですね。
レコーディングは小岩井さんのスタジオでCubaseを使って行った。2ページごとにリファレンスを聴くのもポイント
--それをどうやって録音していたのですか?
小岩井:まずマイクは、私のU 87 Aiを使っていますが、できる限り同じ音にするように、必ず位置を測ってセッティングします。その上で、Cubaseに録っていくんです。いまはCubase Pro 12を使っていますが、ちょうどレコーディングした当初は、まだシステムの入れ替えができていなかったので、Cubase Pro 11を使って最後までレコーディングしていきました。フォーマット的には96kHz/32bit Floatで録音していたので、トータルで30GB弱になりましたよ。作業的には何段階かあって、まず録ったものをプロジェクトごとに1本化した上で、iZotopeのRXを軽くかけてノイズ除去していきます。聴いてみて、どうしてもノイズが気になる部分だけは個別にかけるか、最悪次回に再収録という方法をとりました。その後、サイクルマーカーを使って、手動で文と文の切れ目を指定した上で、マクロを使って書き出していくんです。レコーディングや、こうした編集、切り出しは、ウチのスタッフさんたちと一緒にやっていくのですが、量が多いだけに、かなり大変でした。

毎回、マイクの位置を正確に測り、調整した上でレコーディングに挑んだ
--そんな作業を続けていたんですね。
小岩井:収録は当初、夜中にやっていました。私の仕事の合間だったり、仕事が終わった後とかに…。「みんな起きて、起きて!」って夜中に作業してたら、さすがにみんなバテちゃって……。途中から、ちゃんとスケジュールを組んで収録していきましたが、やはり3か月弱はかかってしまいましたね。
--さて、ここからはこの収録の目的について、いろいろお伺いしてきたいと思います。ヒロシバさんのお陰もあって、今回VOICEVOX版No.7がリリースされることになりました、これが最終目的というわけではないんですよね?
森勢:昨年は歌声を中心にやっていましたが、今回の音声合成においては「スタイル」というものをテーマに研究を進めています。つまり人間の声をデザインすることのサポートであり、「こういう風にしゃべってほしい」を実現させるものです。たとえば「アナウンサーのようにしゃべってほしい」とか「本を読み聞かせるように」などシチュエーションを指定することで、そうしたしゃべり方をさせるのです。
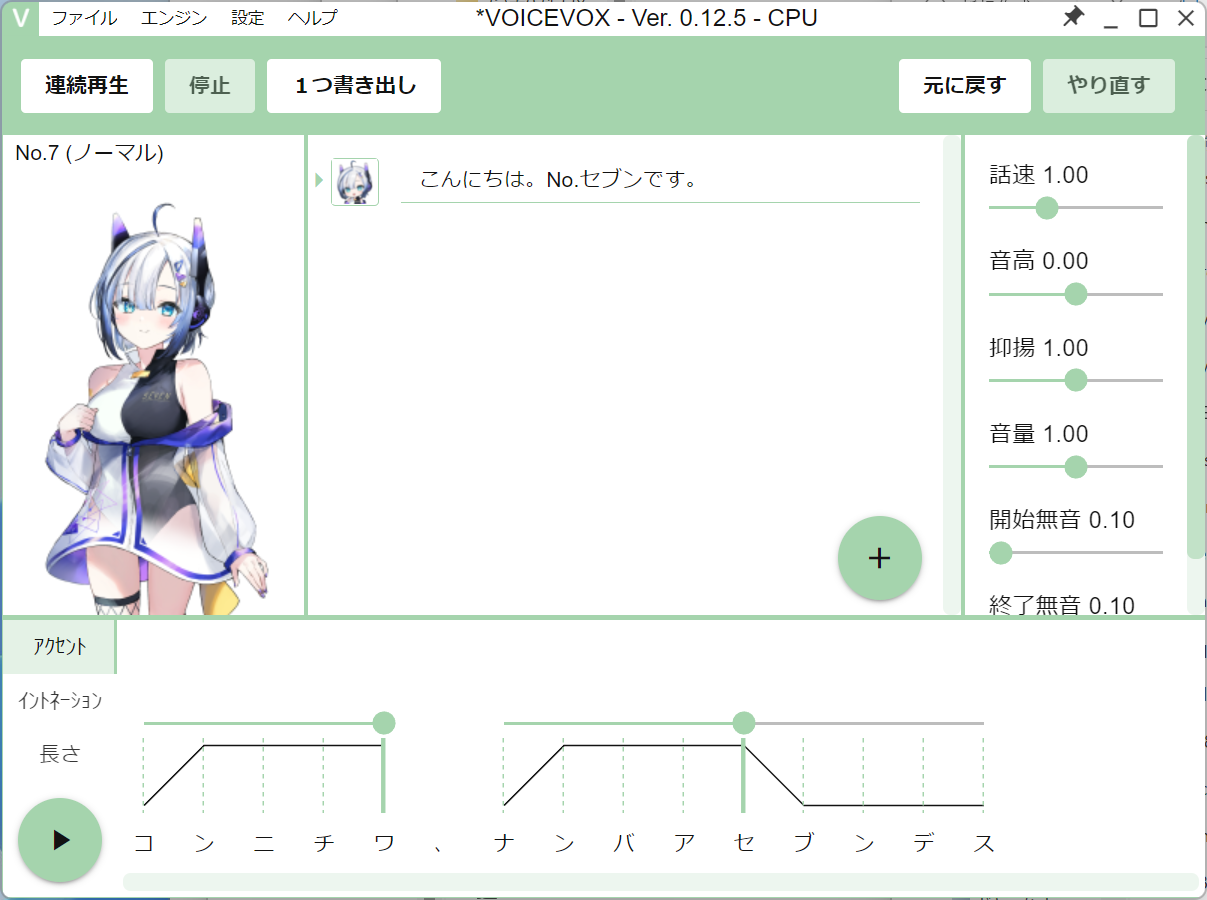
9月30日にNo.7が搭載される形でリリースされるVOICEVOX。まさに小岩井さんの声で喋ってくれる
--VOICEVOXではこれまでも「ノーマル」、「まあまあ」、「ツンツン」といったバリエーションを選択できるようになっていましたし、市販の音声合成ソフトの場合、「喜び」、「元気」、「悲しみ」などの感情パラメーターがあって、それらで調整できるようになっていましたが、こうしたものとは違うのですか?
森勢:基本的な考えは同じです。より表現の幅を広げるために、新たなスタイルを選択することにしました。ノーマルに対して感情やスタイルがどのように変化するかを見出し、「〇〇風にしゃべってほしい」のような指示の出し方の実現、および人間がピッチなどを微修正した後で、その修正結果を汲んで可能な限り自然な発話を作る支援技術を実現したいと思っています。これをプロジェクトでは「ビスポーク音声デザイン」と命名しています。このプロジェクトの一貫として、発話スタイルの変化がノーマルと比べてどう違うかを調べる必要があります。
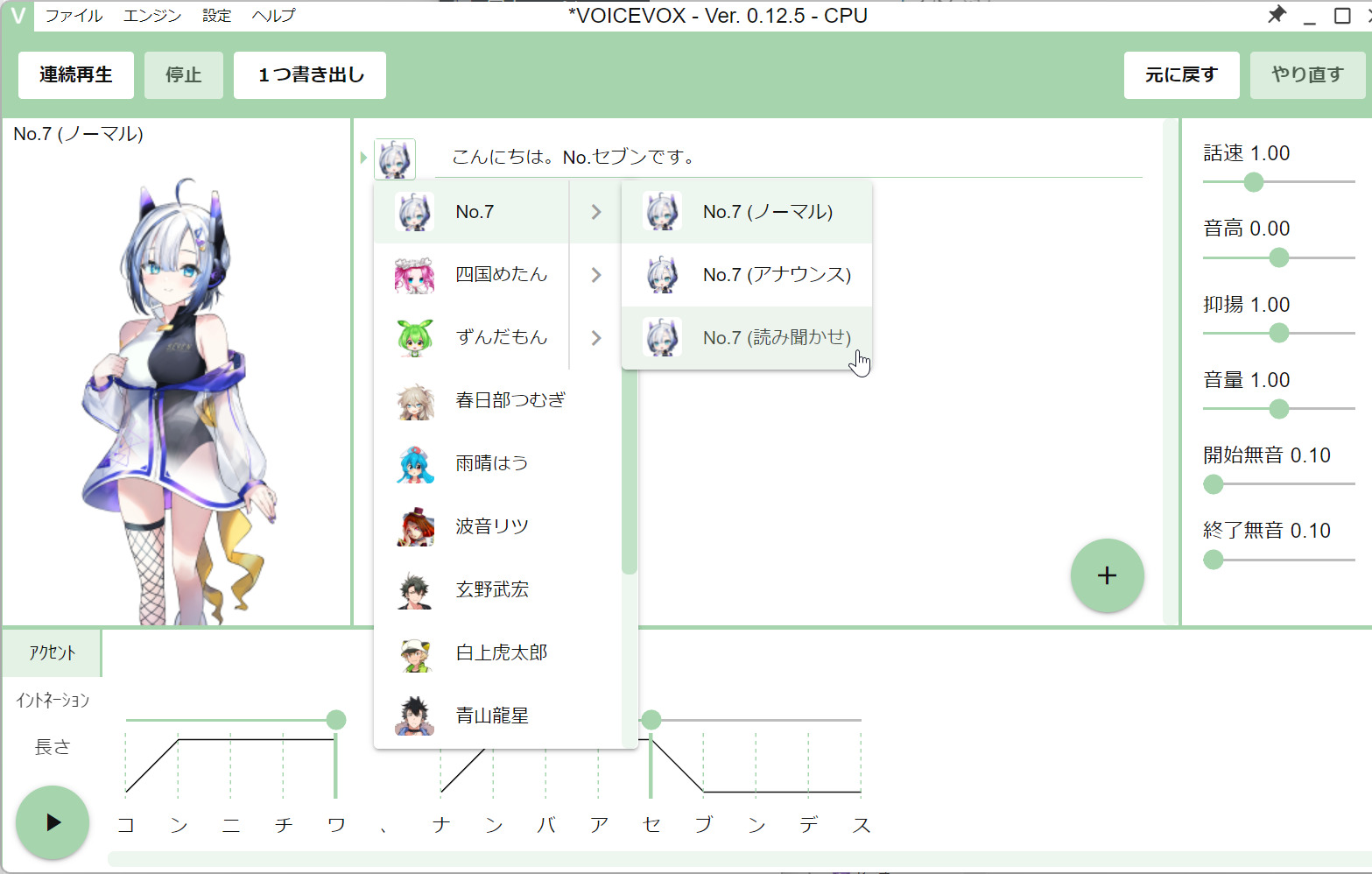
ノーマル、アナウンス、読み聞かせの3種類のバリエーションが用意されている
--なかなか分かりにくいですが、それは他の人の声に対しても効くということですか?
森勢:すでスタイル転写の技術は出来上がっているのですが、実際今回の収録結果を統計的に解析して、スタイルによってピッチ変化がどのようになるのか、抑揚の付け方がどう変化するなど、いろいろ試しているところです。これがうまくいけば、さらに「子供っぽいしゃべり方」とか「活舌悪いしゃべり方」……などなど、さまざまなスタイルを試していければと思っています。
小岩井:そうなると、また4,600文の苦行がやってくるということですね(苦笑)。

小岩井さんのNo.7の声の収録はまだまだ続くかも!?
--こうしたスタイルの研究は森勢先生が初めてなのでしょうか?
森勢:まったく同じスタイルを扱っているわけではありませんが、近い研究事例はあります。ただ、データ量が少ないので統計的に扱うには厳しいのではないかとみています。もっともこの4,600文でどこまでできるのかのポテンシャルを見ているところでもあります。
--でも4,600という数はどこから出てきたのですか?
森勢:常用漢字の種類とその音読み、訓読みを組み合わせて行って4,500ちょっとあるんです。そこでそれを網羅する4,600という数にしてみました。
--かなり膨大な数ですが、これは文の数であって、実際にはそれを音素ごとにラベリングしていくわけだから、途方もない量ですよね?それをもしかして手動で行っている?
森勢:さすがに、手動で作業していたらキリがないので、うちの大学院生が自動ラベリングしていて、実際、かなりいい精度でのラベリング付けができています。それを研究者向けとして公開するので、研究用途として興味のある方はぜひチェックしていただければと思います。
--4,600の文も、実際収録したデータやラベリング結果もすべて公開しているのはどういう理由なんですか?
森勢:私たちは研究用途で使っておりますが、さまざまな研究に使えるものを研究室で閉じて使うのはもったいないとの判断からです。それよりは、データベースを使った研究を進める研究者や製品の開発をするエンジニアを増やすことが重要と考えています。将来の研究開発者を増やすためにも、ソフトウェアを使うことで音声合成に興味を持つユーザの人口を増やしたいと思っています。先ほどのスタイルを増やすという点では、いろいろな人を巻き込んでいく必要があります。そのため、こうした情報を公開することで手順を示していければ、と。

No.7プロジェクトのメンバーでもある私も入れて最後に記念撮影!
--最後に、このVOICEVOXのNo.7、しゃべらせてみると、まさに小岩井さんそのもので、本人との違いが分からないほどですが、小岩井さん自身が使ってみていかがですか?
小岩井:VOICEVOXのセブンちゃん、まさに私の声でしゃべってくれますね。NEUTRINOのセブンちゃんも、うまく調声している作品だとホントに人間で、私よりうまい歌い方になっていますからね。歌を覚えて歌うのって、結構大変ですが、セブンちゃんは指示すればバッチリ覚えて、その上、絶妙なニュアンスで歌ってくれるから自分のコピーとしてはとっても優秀。本当に合成された歌声なの?と思うレベルですから。今回のVOICEVOXも、みなさんがどう使ってくれるのかとっても楽しみです。今後、先生の研究するスタイル学習ができるようになるとますます面白くなりそうなので、期待しているところです。
--今日はありがとうございました。
このインタビュー後、別途VOICEVOXの開発者であるヒロシバさんからもコメントをいただきました。
ヒロシバさんからのコメント
セブンさんは個人的に好きなキャラクターだったので、VOICEVOX作成をお声掛けいただいたときはとても嬉しかったです。
開発に関して、苦労した点がほとんどなかったのが印象的でした。強いて言うならキャラクター設定の折り合わせが少し大変でした。セブンさんは設定がほとんどないキャラクターだと思うのですが、VOICEVOXはキャラクター性も重視するため、無理を言って良い感じのプロフィール情報を作っていただきました。
それと、でき上がった音声を聞いてとても驚きました。特に調整しなくてもとても自然に発話してくれます。
ぜひいろんな方に活用の機会を届けられると嬉しいです。
VOICEVOXにおいてNo.7は7番目ならぬ13番目となるキャラクターとして登場した
【関連情報】
コメント
早速ダウンロードしましたが、№7がありません。まだ公開されていないのでしょうか。最新版は8月で12種類のキャラクターとなっています。ご教示お願いします。
澤田さん
ぜひ、記事も読んでみてくださいね。冒頭にもインタビュー中にもいっぱい書いていますが、9月30日にリリースです。
申し訳ありませんでした。9月30日となっています。早とちりしてリリース済みと勘違いしていました。謹んでお詫び申し上げます。9月30日楽しみにしております。