DTMステーションでも紹介してきたSoundID Voice AIやVocoflexのように、ボーカルをまったく別の歌声に差し替えるAI技術が大きな注目を集める中、また一つ画期的なプラグインIK MultimediaのReSingが先日9月25日に発表され、10月23日に発売が予定されています。新世代のAIボイスモデルプラグインであるReSingでは、製品のタイトルのように、まるでほかの人が歌い直したかのように、まったく別の歌声を作り出すことが可能。歌声の感情表現を自在に操るCHARACTER機能、AとBの2つの異なるモデルを掛け合わせて未知の歌声を生み出すFusion機能、さらにはプロクオリティの各種エフェクトまで搭載しており、まさに歌声の創造性を無限に押し広げるツールとなっています。
また、すべての処理がユーザーのコンピュータ内で完結するローカル動作を実現しているほか、ユーザー自身が自分の歌声を学習させ、オリジナルのAIボイスモデルを作成できるという革新的な機能も搭載。一方いで、倫理的な側面にも配慮が行き届いており、すべての歌声モデルはアーティストとの正式な契約のもとで制作されているという透明性も確保されているのも大きな特徴となっています。9月25日の発表後、SNSなどでも大きな話題になっていましたが、日本語を歌わせるデモがなかったので、どうなっているのか気になっていた人も多いと思います。そんなReSingを発売前ですが、ベータ版を入手することができたので、実際に日本語の歌を変換することを試してみました。生の歌声、Synthesizer V 2による歌声それぞれで実験してみたところ、非常に面白い結果が得られたので、紹介してみましょう。
※2025.11.13追記
先日、IK Multimediaから発売延期が発表されていたReSingですが、11月12日にPublic Betaがリリースされ、購入ユーザーはとりあえず使えるようになっています。正式版は後日ということです。なお30%オフのセールは11月20日いっぱいまでとなっています。
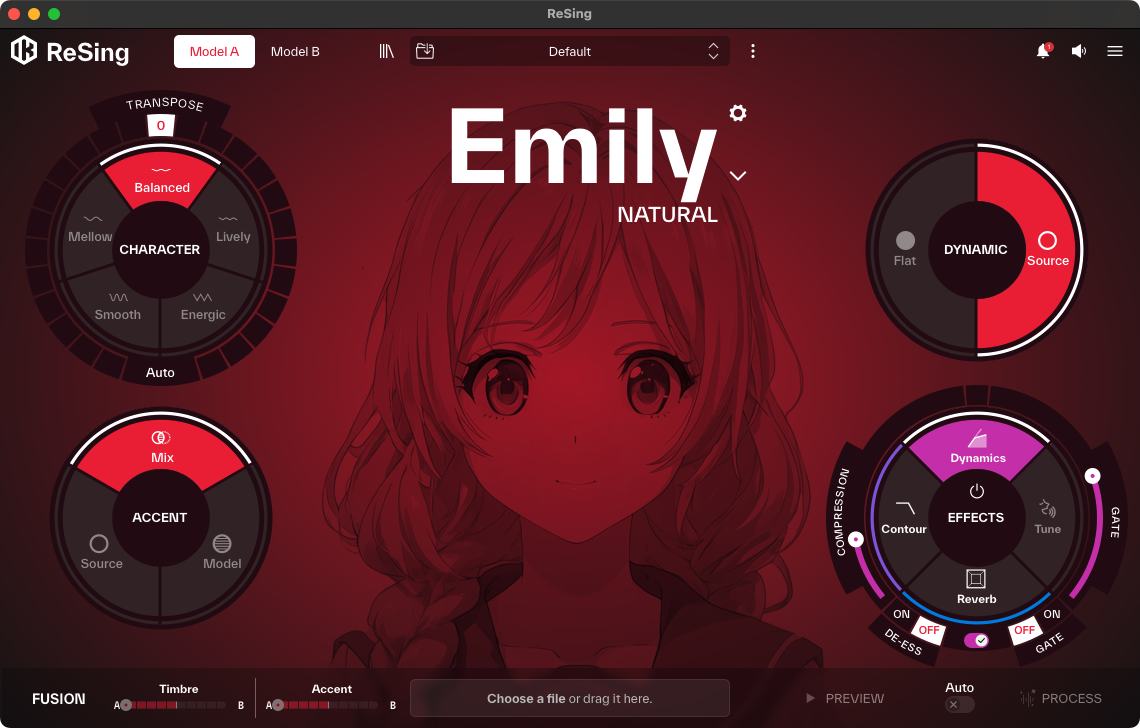
自分の歌を別人に差し替えたり、楽器に変換できるAIツールIK MultimediaのReSingが10月16日に発売開始
ReSingを使って、まったく別人の歌声に変えてみた
さっそくですが、今回このReSingを試すにあたり、実際に2つのデモ動画を制作してみました。ReSingがどれほどのポテンシャルを秘めているのか、まずこのサウンドを聴いていただくのが一番分かりやすいと思います。このデモ動画は、ReSingのスタンドアロン版でボーカル音声を変換し、その結果をDAWのトラックに並べています。ReSingでは、さまざまなカスタム設定ができますが、とりあえずモデルの切り替えのみで、設定はデフォルトのままにしています。
どのAIモデルで変換したのかが視覚的にも分かるよう、モデルの画像を表示しながら順番にサウンドが再生されようにしているので、まったく異なるタイプのボーカルが、ReSingによってどのように生まれ変わるのか、ぜひ聴き比べてみてください。
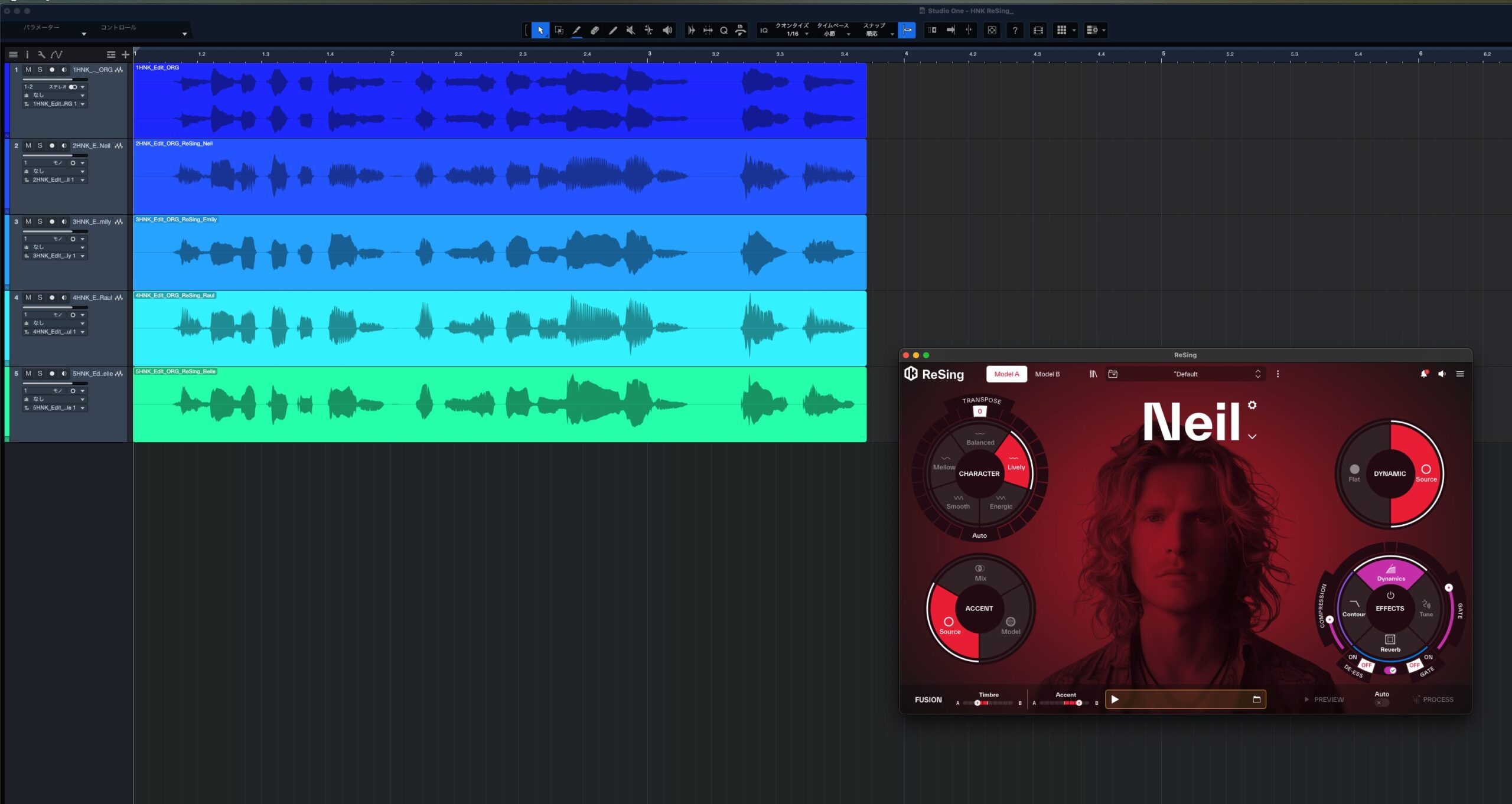
ReSingによってどんな歌声に変わるのか試してみた
まず1曲目の素材として選んだのは、DTMステーションのオリジナルレーベルである「DTMステーションCreative」からリリースした第6弾作品、小岩井ことり(@koiwai_kotori)さんが歌う「ハレのち☆ことり」です。まだベータ版でのテストなので、正式版が登場した時点で画面や音が少し変わる可能性はありますが、ぜひそのサウンドを聴いてみてください。
いかがでしたでしょうか?ハレのち☆ことりでは、小岩井ことりさんの可愛らしい歌声が、Neilというモデルになった瞬間、キャラクタの異なる、完全に男性ボーカルの歌声へと置き換わっていましたよね。元の歌唱が持つビブラートの繊細な揺れ方、しゃくり上げるような細かいピッチの動き、息継ぎのタイミングといった、基本的な情報を受け継ぎつつ、本当に別の人が歌っているかのようになっていますね。
続いてもう1曲は、歌声合成ソフトSynthesizer V Studio 2 Proの歌声データベース「Mai2」が歌う、DTMステーションPlus!のエンディング曲、多田さん作曲の「心をこめて」です。こちらは、人間ではなくAIが歌ったものを、さらに別のAIボイスモデルに変換するという動画となっています。
こちらも非常に自然に変換されていましたね。現在のSynthesizer V 2の歌声は、もはや本物の人間の歌声とほとんど区別がつかないレベルに達しているため、ReSingもこれを人間のボーカルトラックとほぼ同じ感覚で扱うことができ、自然な変換が可能でした。ただ、非常に細かい点を指摘すると、動画での歌いだし部分、「君のために」という歌詞が、変換後には少し「ちみのために」と聴こえてしまう箇所がありました。
もっとも、これはReSingの限界というよりは、試したボイス・モデルが英語でトレーニングされていることによるのでしょう。外国人が日本語の歌詞を歌ったときの訛りのようですが、ReSingのパラメータ設定を追い込むことで、さらに明瞭に発音させることが可能です。オリジナルの発音にするか、モデルの発音にするか、BALANCEセレクターで調整できるので、後述しますね。
数ステップで完了するReSingの基本的な操作フロー
では、実際にReSingをどのように使っていくのか、その基本的な操作フローを紹介しつつ、どんな機能があるのか見ていきましょう。ReSingにはDAW上で動作するプラグイン版と、単体で起動するスタンドアロン版がありますが、ここではDAWを立ち上げずに素早くファイルを処理できるスタンドアロン版を中心に、オーディオファイルを直接読み込んでボーカルを変換する手順を紹介していきます。
ステップ1:スタンドアロン版へのオーディオファイルの読み込み
まずはReSingのスタンドアロン版を起動します。画面にはオーディオファイルをドラッグ&ドロップするか、ファイルブラウザから選択するためのエリアが表示されます。ここに変換したいボーカルのオーディオファイルを読み込ませるだけで、解析が自動的に開始されます。DAWを立ち上げる必要がないため、特定のファイルだけを素早く処理したい場合に非常に便利。
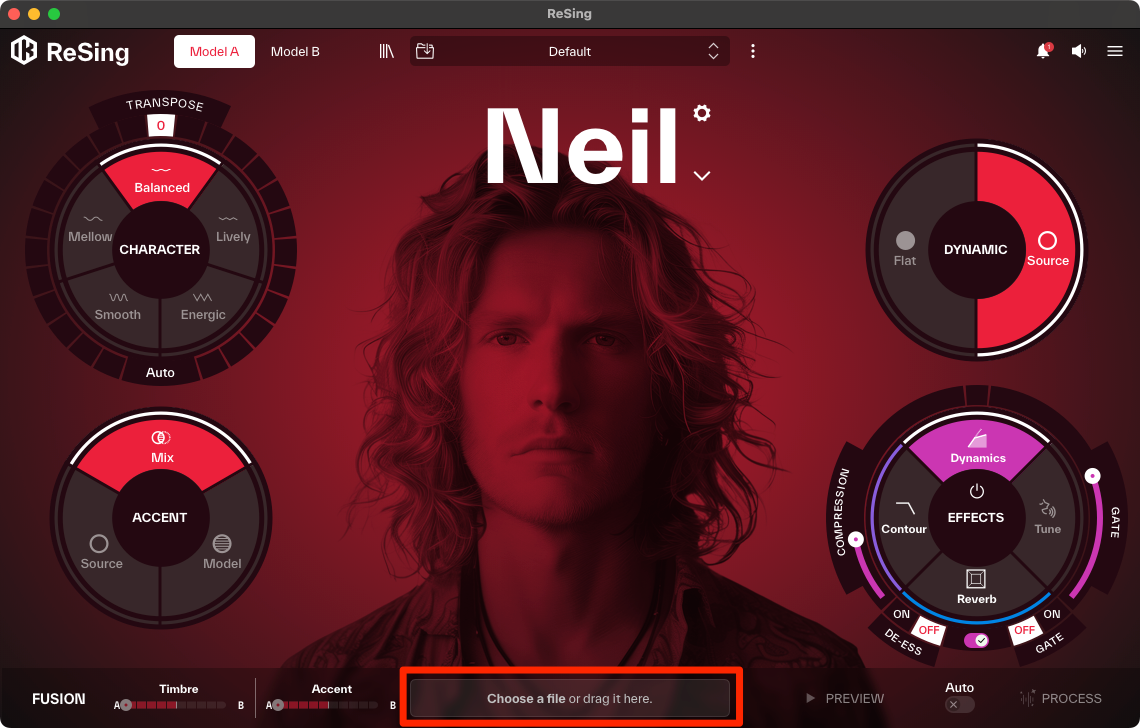
ReSingスタンドアロン版の起動画面。ここにオーディオファイルをドラッグ&ドロップするだけで解析が始まる
もちろん、プラグイン版も用意されており、製品版がリリースされればDAW上でシームレスに動作させることも可能です。Cubase ProやStudio Oneなど対応するDAWでは、より連携を深めるARAにも対応しているとのことです。
ステップ2:ボイスモデルの選択
オーディオファイルを読み込んだら、心臓部であるボイスモデルを選びます。モデルブラウザでは、プリセットのボイスモデルがリスト表示され、各モデルには声の音域(ソプラノ、テナーなど)や音楽ジャンル(ポップ、ロック、ジャズなど)、音色の特徴(ウォーム、ブライト、ハスキーなど)といったタグが付与されているので、これらをフィルターにして目的のサウンドを効率的に探し出すことも可能。
気になるモデルが見つかったら、試聴ボタンでキャラクタを確認してから読み込みます。またReSingには歌声だけでなく、ボーカルを楽器の音色に変換するインストゥルメントモデルも用意されているので、実験的なサウンドメイクも可能となっています。
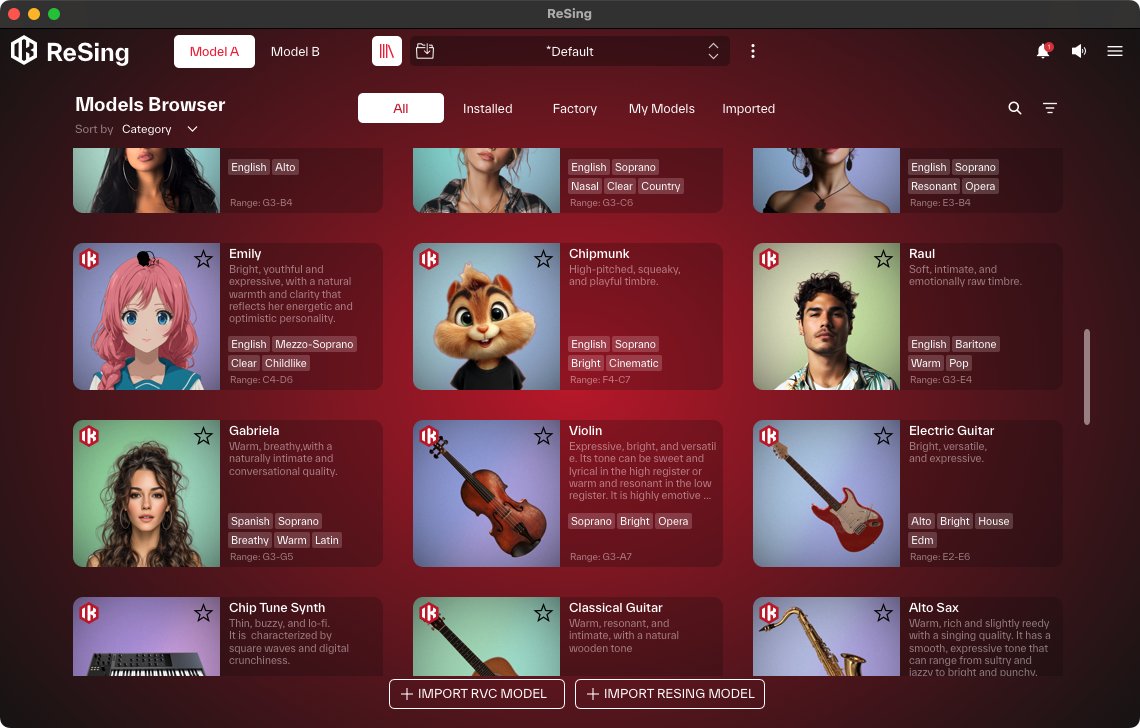
ジャンルやタグで絞り込みも可能なモデルブラウザー。歌声だけでなく楽器のモデルも用意されている
ステップ3:声質のキャラクタを調整する
モデルを選択したら、いよいよReSingの真骨頂である声のキャラクタ調整です。左上の「CHARACTER」セレクターが、AIモデルの歌唱表現をコントロールする鍵となります。これは単なるフィルタやエフェクトではなく、AIに対して「どのような感情やスタイルで歌うか」を指示するパラメータとなっています。
5つの選択肢はそれぞれ「Balanced」「Lively」「Energetic」「Smooth」「Mellow」となっており、これらをクリックで切り替えることで、歌声の表現を瞬時に変化させることができます。たとえば、楽曲のAメロ部分のオーディオファイルを読み込ませて「Mellow」や「Smooth」を選択し、落ち着いた繊細な表現のボーカルとして書き出す。次にサビ部分のファイルを読み込ませて「Energetic」や「Lively」を選択し、力強いボーカルとして書き出す。といったセクションごとに最適なキャラクタを選んで個別に処理することもできますね。
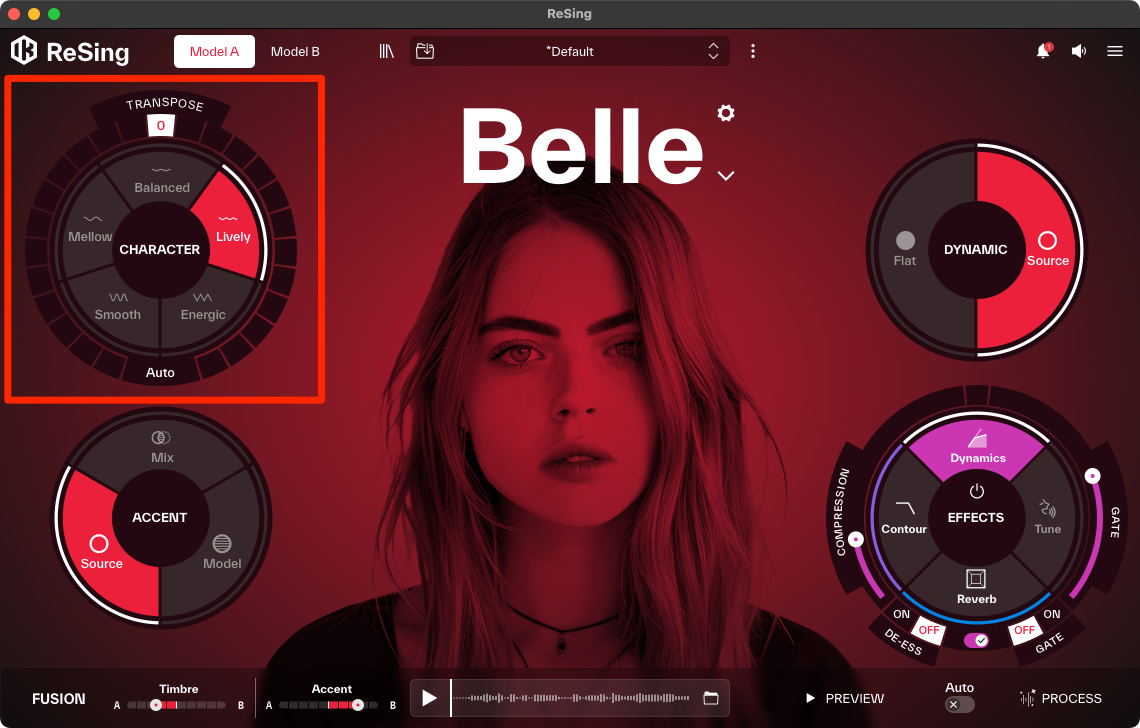
歌声の感情表現をコントロールするCHARACTERセレクター。5つのスタイルから選択可能
続いて、左下には発音をコントロールするためのBALANCEセレクターが用意されています。
Model: AIモデルが持つ本来の発音スタイルを適用
Source: 元のボーカルが持つ発音のスタイル、つまり元々のアクセントやアーティキュレーションを維持したまま、AIモデルの音色を適用
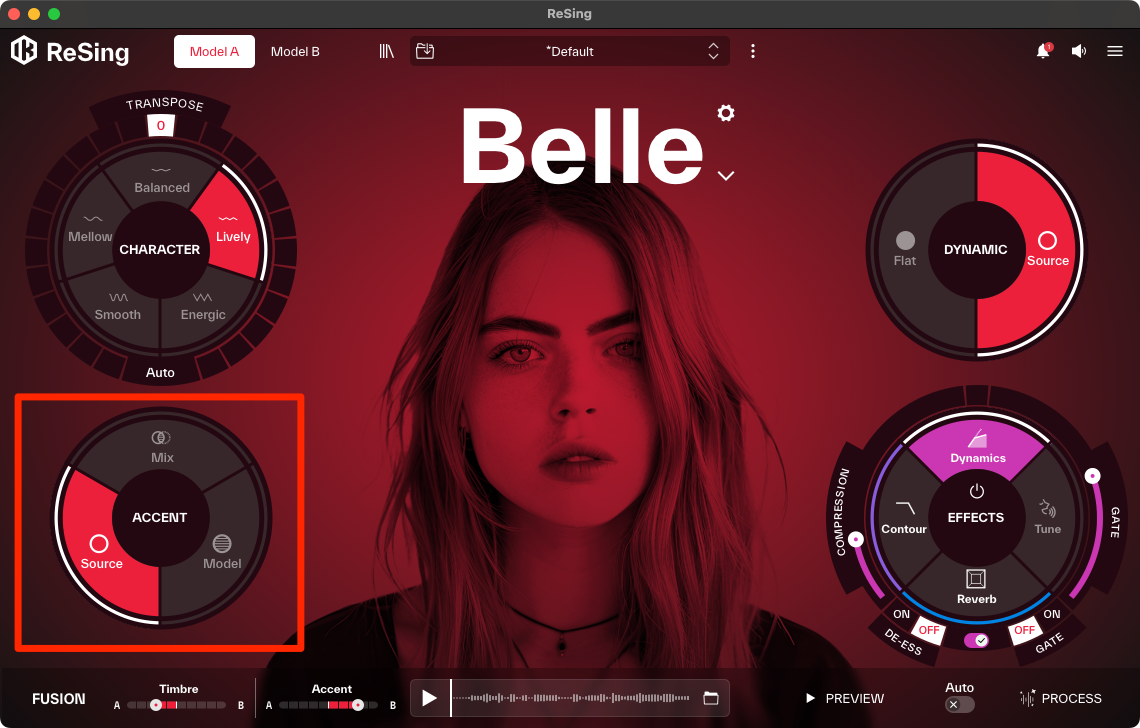
発音のニュアンスを決めるBALANCEセレクター。元の歌い方を活かすか、モデルに寄せるかを選べる
そして右上のDYNAMICセレクターには、音量変化や表現の強弱、つまりダイナミクスをどのように扱うかを決定する2つのモードが用意されています。
Source: 元のボーカルが持つ自然なダイナミクスをそのまま維持。オリジナルの歌唱が持つ表現の強弱を、変換後の歌声にも忠実に反映させたい場合に選択します。
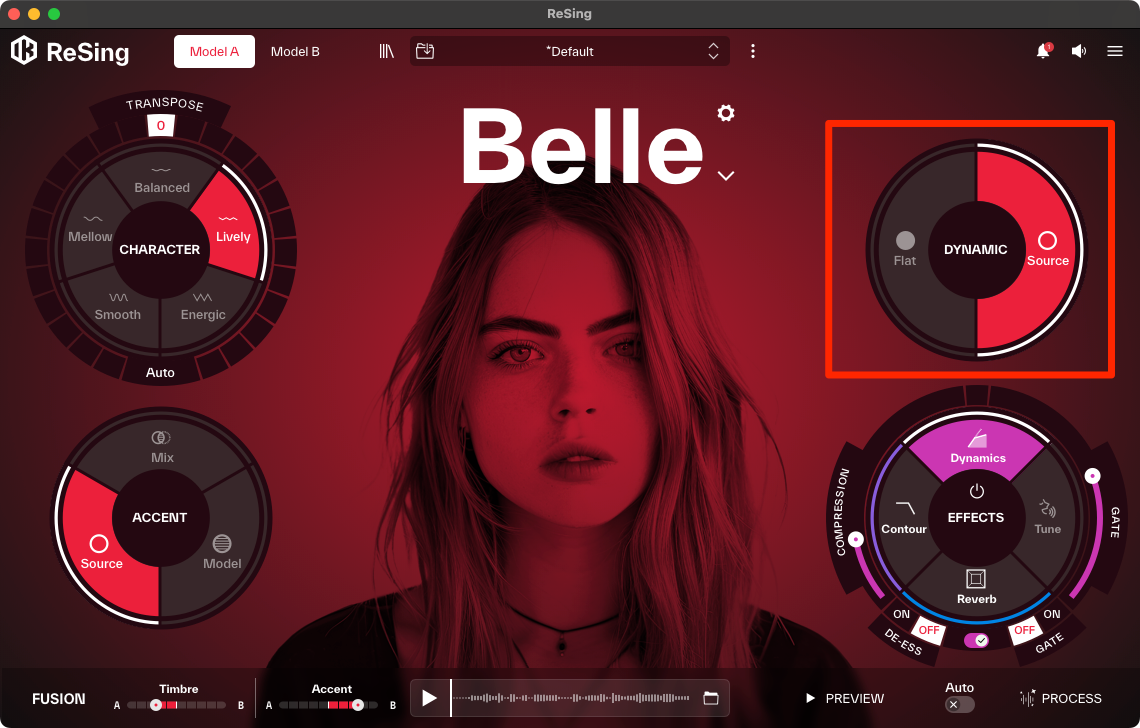
発音のニュアンスを決めるBALANCEセレクター。元の歌い方を活かすか、モデルに寄せるかを選べる
ステップ4:2つの声を混ぜ合わせ、未知の歌声を生む「Fusion」機能
ReSingの最も独創的な機能が、2つの異なるボイスモデルを掛け合わせてハイブリッドな声を作り出す「Fusion」機能です。画面上部にある「Model A」と「Model B」のスロットに、それぞれ好みのモデルをロードします。たとえばModel Aにハスキーな男性ロックボーカル、Model Bにクリアな女性ポップボーカルを設定し、画面下のFUSIONセクションにあるTimbreのスライダーを中間点に動かしていくと、両者の特徴が滑らかに混ざり合い、これまでにないユニークな質感のボーカルが生まれるのです。芯の強さとエアリーな質感を両立させたり、人間と楽器のモデルをしても面白いと思いますよ。
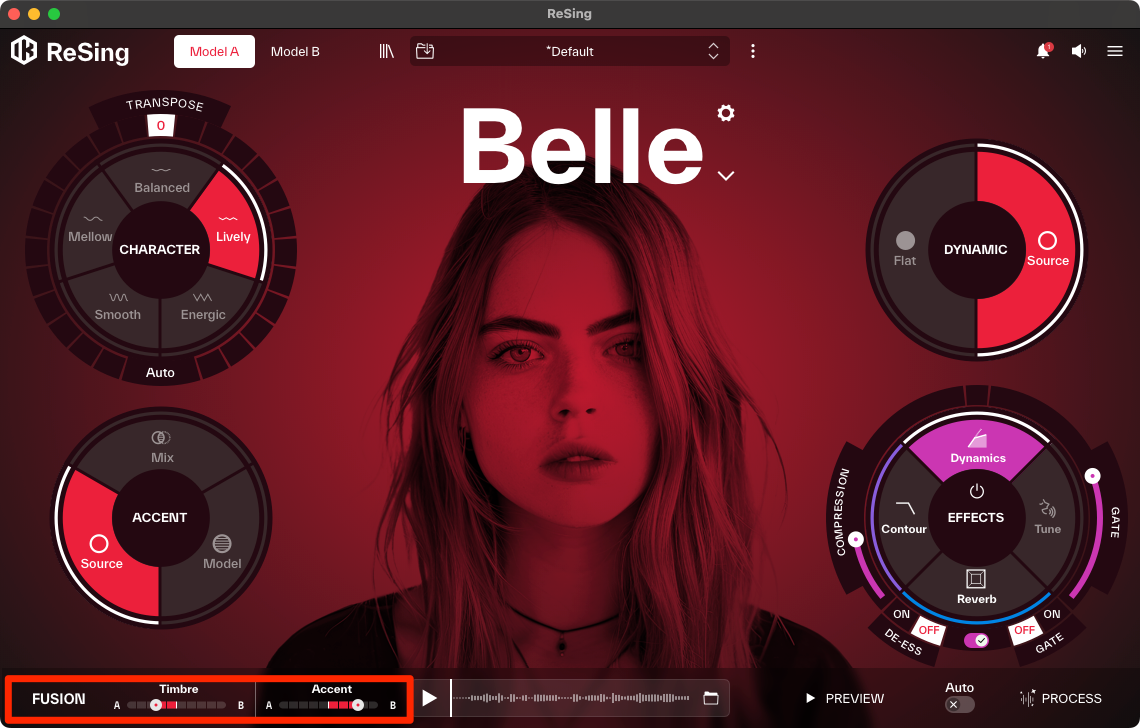
2つのモデルを掛け合わせるFusion機能。Timbreスライダーで音色を混ぜることができる
ステップ5:EFFECTSでサウンドを最終調整
ReSingはボイス変換だけでなく、IK Multimediaの製品だけあって最終的なサウンドメイクを施すためのプログレードなエフェクトも一通り内蔵。画面右下のエフェクトセクションには、Dynamics、Tune、Reverb、Contourという4つのプロセッサが用意されています。
変換後の歌声の表現力と明瞭さを高めるための統合プロセッサ。コンプレッション量を調整する「Compression」、歯擦音を抑える「De-Ess」、ノイズやブレスを減衰させる「Gate」という、ボーカル処理に不可欠な3つの機能を搭載。
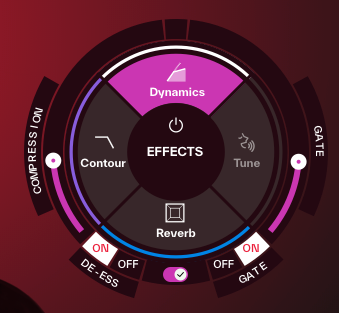
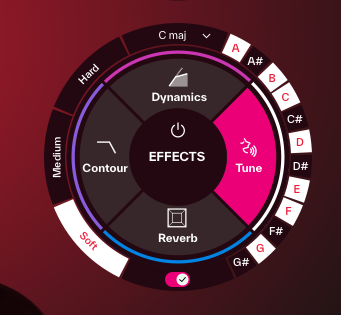
変換後の歌声のピッチをリアルタイムに補正や意図的に加工するための機能。
Mode: 補正の強さを「Soft」「Medium」「Hard」の3段階から選択でき、「Hard」を選択すれば、いわゆるケロケロボイスのようなサウンドメイクも可能。
Scale/Key: 補正する音階を「Chromatic」のほか、メジャー、マイナーといった各種スケール、キーも設定できるため、楽曲に合わせた正確なピッチ補正が行える。
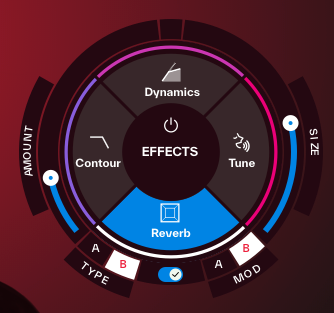
歌声に空間的な響きと奥行きを与える高品質なリバーブ。Type: 残響のキャラクターを「Plate」や「Chamber」といった定番のタイプから選択可能。
Modulation: リバーブ音に「Doubler」や「Chorus」といった揺らぎの効果を加え、より豊かな響きを作り出すことできる。
Amount/Size: リバーブの全体量や空間の大きさ(ディケイタイム)も細かく調整可能。
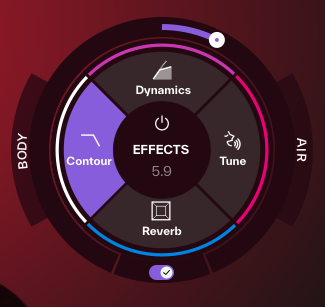
素早く音色を整えるためのトーンシェイピング機能。低域の量感を調整する「Body」と、高域の空気感を調整する「Air」という2つのノブだけで、歌声の太さや明るさを直感的にコントロールできるようになっている。
これらの設定を行い、最後「PROCESS」ボタンを押すことで、変換後の歌声を書き出すことができます。また、「PREVIEW」ボタンを押せば、書き出しすることなく、どんな変化があったのか試聴できるようにもなっていますよ。
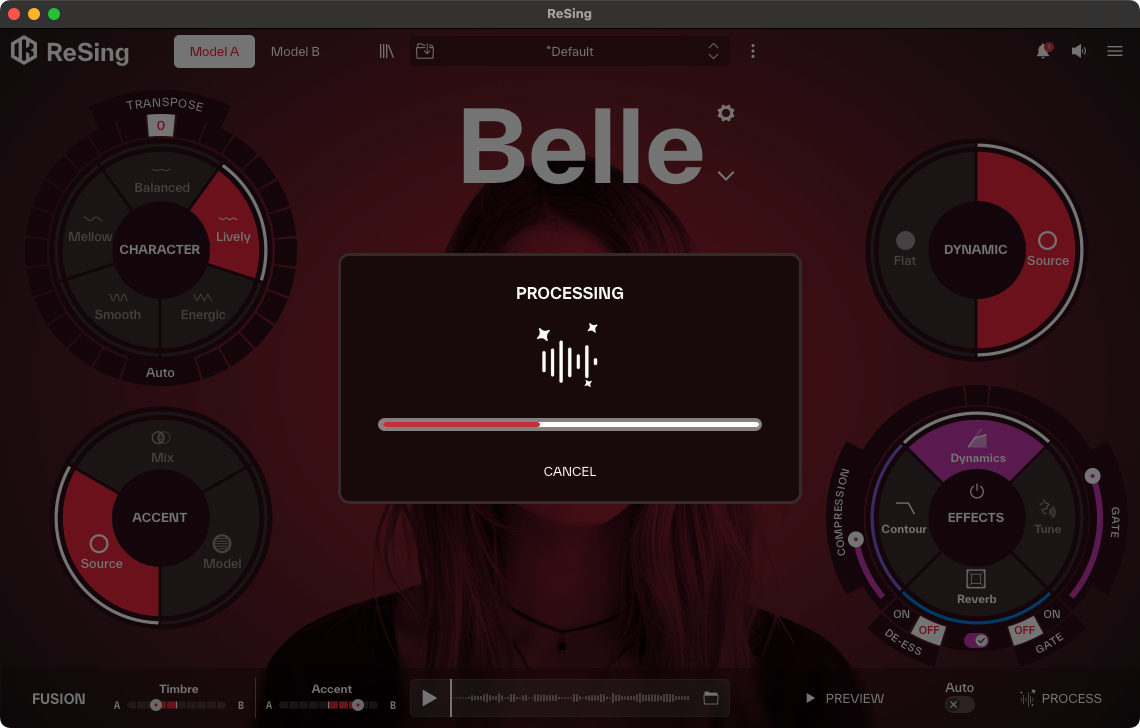
PREVIEWで試聴後、PROCESSボタンで変換結果をオーディオファイルとして書き出す
自分の歌声もAIモデル化できる
ReSingがほかのAIボイス製品と一線を画す最大の機能が、ユーザー自身でオリジナルのボイスモデルを作成できる専用ツール「ReSing Modeler」の存在。今回試用したベータ版にはModelerが含まれていなかったため、まだ開発途上の機能だと思いますが、マニュアルによれば、非常に簡単なステップで自分の歌声をAI化できる画期的なものになるようです。
マニュアルによると、合計で約15分以上の長さの、クリーンなアカペラ音源が必要となり、BGMやほかの楽器、ハーモニーなどが入っていてはいけないとのこと。学習の精度を高めるためには、できるだけノイズや部屋の反響音が入らないよう、音響的に処理された環境で録音することが推奨されています。この学習データのクオリティが、最終的なAIボイスモデルの質を大きく左右する、最も重要なポイントとなるようです。
そして準備した、オーディオファイルをReSing Modelerに読み込ませ、ここで作成するモデルに名前を付けたり、「Pop」「Ballad」「Bright」「Husky」といった特徴を表すタグを設定。そして学習プロセスを開始すると、あとはReSing Modelerが歌声の音色や歌い方の癖などを自動的に分析・学習し、オリジナルAIボイスモデルを生成してくれる、という形になっています。
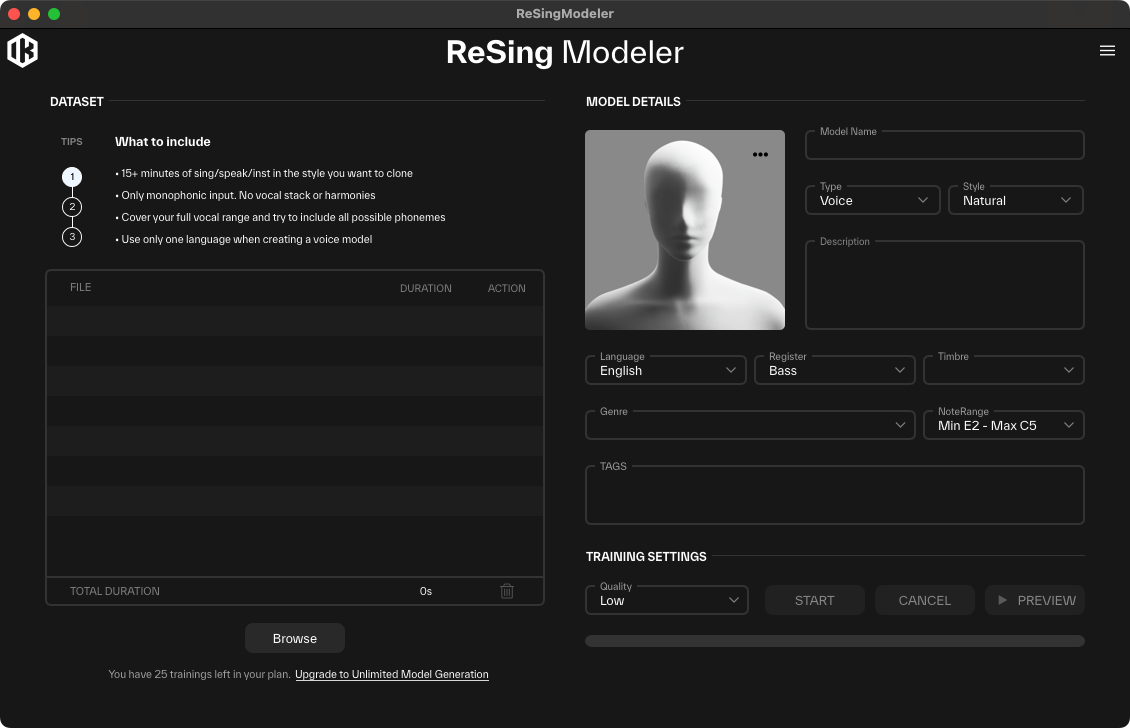
ユーザーが自身の歌声モデルを作成できるReSing Modeler
また、自分で作ったモデルは、個人的な仮歌制作に使うことはもちろん、ReSingが今後展開を予定している「ReSing Marketplace」を通じて、ほかのユーザーにライセンス提供することも可能になる構想のようです。つまり、自分の歌声が新たな収入源になる可能性も秘めているということですね。音楽制作の変革だけでなく、クリエイタのビジネスモデルにも影響を与えるかもしれませんね。
DTMステーションでも、これまで「もはや仮歌は自分の歌でOK?AIでボーカルを自在に差し替えるSoundID VoiceAI。声を楽器に差し替えることも」という記事で、「SoundID VoiceAI」についてや「10秒の歌声を学習し、リアルタイムにその声になれるAIシステム、VocoflexをSynthesizer VのDreamtonicsが発表」という記事で、Synthesizer Vでお馴染みのDreamtonicsが開発した「Vocoflex」といったAIボイス変換ツールを紹介してきましたが、ReSingはまた違った進化を遂げそうですね。
3つのグレードから選べる価格体系
さて最後に、価格を見ていきましょう。本日9月25日に正式発表されたReSingですが、リリースは10月23日予定なので、現時点での情報ですが、ユーザーのニーズに合わせて選択できる3つの製品グレードが用意されています。まず、基本的な機能を試せる無料版の「ReSing Free」では、1つのボイスモデルと1つのインストゥルメントモデルが利用でき、RVCモデルのインポートも1つまで可能。
次に、スタンダード版となる「ReSing」は、10種類のモデルを収録し、RVCモデルのインポートは無制限。さらに、前述のReSing Modelerを使って、自分のボイスモデルを1つ作成することができるようです。こちらの価格は99ドル。そして最上位グレードの「ReSing Max」では、20種類のモデルが利用できるほか、RVCモデルのインポートやModelerでのモデル作成数も無制限とのこと。
そして、これらのグレードに加えて、ReSingはユニークな販売形態も計画しており、前述した今後展開される「ReSing Marketplace」では、追加のボイスモデルを「セッション」という単位で購入できるようになるようです。これは、あるモデルを1ヶ月間、無制限に使用できる権利を購入する、というサブスクリプションに近い考え方で、セッション期間が終了するとそのモデルは使えなくなりますが、再度セッションを購入することで、また利用可能になるとのこと。これにより、必要な時に必要な歌声だけを、柔軟に手に入れることができる設計となっています。
以上、本日発表された新世代のAIボイスプラグイン、ReSingについて紹介しました。ボーカルトラックを自然に差し替える高い基本性能に加え、ローカル環境で処理が完結する快適なワークフロー、そして何より自分の歌声をAIモデル化できるという革新的な機能を備えていましたね。仮歌の差し替え、コーラスパートの生成、まったく新しいボーカルサウンドの創造など、その活用法はアイデア次第で無限に広がる可能性を秘めていますね。
【関連情報】
ReSing製品情報
ReSing MAX製品情報
【価格チェック&購入】
◎beatcloud ⇒ ReSing , ReSing MAX


コメント
すごいですね! でも男性ボーカルを女性ボーカルに変換する場合はどうですか?
公式デモでも、original voice は女性ばかりなので、そこがちょっと(というか、かなり)気になっております。
率直な印象・感想などいただければありがたいです!
通りがかりで気になっている人さん
問題なく使えますが、事前に1オクターブ上げてから使うと、よりいい感じになりますよ。