ADC Japan 2026のDay 2(6月2日)、ヤマハの才野慶二郎さんと密岡稜大さんによるセッション「When DAWs Sing ─ Starting from Yamaha’s Omnivocal」が行われました。Synthesizer VやVOCALOIDといった歌声合成ソフトは専用エディターを必要とするのが当たり前でしたが、ヤマハが開発中のプラグイン「Omnivocal Beta」はその常識を覆す試みです。「ボーカルをDAWの中にある普通のインストゥルメントとして扱えるようにする」——この夢を実現するうえで立ちはだかる4つの技術的課題と、その解決に向けた業界全体への協力の呼びかけを、スライドとライブデモを交えながら丁寧に説明してくれました。
また翌Day 3(6月3日)には、Dreamtonicsのカンル・フアさんとAHSの尾形友秀さんが「日本でオーディオソフトウェア会社を立ち上げる方法」という異色のセッションで、起業の現実と日本市場の特殊性を赤裸々に語りました。2本のセッションをまとめてレポートします。

セッション「When DAWs Sing」のタイトルスライド
DAWの中でボーカルを完結させる——ヤマハが問いかけた「DAWが歌う世界」とは
ADC Japan 2026の2日目、最も技術的な熱量を帯びたセッションのひとつがヤマハによる「When DAWs Sing ─ Starting from Yamaha’s Omnivocal」でした。登壇したのは、SVS(Singing Voice Synthesis=歌声合成)の研究・開発を15年以上にわたって続けてきた才野慶二郎さん(研究開発統括部 第1研究開発部 音楽情報処理グループ)と、音楽ソフトウェアおよび歌声技術のUI/UXデザインを担当する密岡稜大さん(研究開発統括部 先進技術開発部 音楽インタラクショングループ)のふたり。Synthesizer VやVOCALOIDをはじめとする歌声合成ソフトが専用エディターを必要とするのに対し、「ボーカルをDAWの中にある一般的なインストゥルメントとして扱えるようにしたい」というアプローチで、業界全体に協力を呼びかける場となりました。

登壇した才野慶二郎さん(左)と密岡稜大さん(右)
「DAWが歌う」とはどういうことか
現在の歌声合成ソフトは、基本的に専用エディターを必要とします。Cubaseを開いてボーカルパートを作るにしても、そこからVSTプラグインを開き、さらに別のエディター画面に切り替えて歌詞を入力する、というのが通常のワークフローです。ドラムでもギターでも、インストゥルメント音源はDAWのピアノロールで音符を打ち込むだけで音が出るのに、ボーカルだけは別扱い——これが「普通」になっていました。
才野さんたちが目指したのは、その常識を覆すことです。セッションのデモパートを担当した密岡さんは、Cubaseのプロジェクトを実際に開き、ドラム、パーカッション、ギター、ベースなどが並ぶ中にボーカルトラックを置いた状態を見せました。そしてプラグイン「Omnivocal Beta」を使ってボーカルをリアルタイムに鳴らしてみせたのです。Omnivocal Betaに関しては、昨年Cubase 15が登場した際「毎年恒例のCubase新バージョン。Cubase 15には、VOCALOID開発チームによる新たなプラグイン、AIステム分離、Newシンセ&エフェクトが新搭載!」という記事でも取り上げていましたが、改めて見ていきましょう。
スライドに掲げられた4つのキーポイントが、このデモの要点を端的に表しています。専用エディターは不要、歌詞はDAWのエディター上で直接入力できる、編集結果はリアルタイムで音に反映される、パラメーターをリアルタイムにコントロールできる——の4点です。

デモのキーポイント。黄色の文字「The vocal can be treated just like an instrument that sings within a DAW」がこのセッションのテーゼ
スライドの最下段には黄色い文字でこう記されていました。「The vocal can be treated just like an instrument that sings within a DAW(ボーカルは、DAWの中で歌うインストゥルメントとして扱えるようになる)」。これがこのセッション全体を貫くテーゼです。
なぜ今まで実現できなかったのか
「見た目には当たり前のことに見える。でも、できなかったんです」——スライドの見出し「LOOKS OBVIOUS. WASN’T POSSIBLE.」が、そのジレンマを率直に表現しています。

「見た目には当然。でも実現できなかった」——歌声合成ソフト特有の2つの課題を示したスライド
才野さんは、歌声合成が通常のインストゥルメント音源と根本的に異なる点を説明しました。SVSプラグインには「DAWとの統合」において4つの技術的な壁が存在するというのです。

DAWに統合されたSVSが抱える4つの課題の概要
① Lyrics Input UI/UX(歌詞入力のUI/UX)
ピアノロールは音符を扱うために設計されており、歌詞を「第一級の機能」として扱っているDAWは多くありません。しかし歌声合成の観点では、歌詞の入力はオプションではなく必須です。「歌詞の編集は、MIDIノートの編集と同じようにネイティブで、インラインで、すばやくできるべきだ」と才野さんは述べました。SVS開発者の目線からすれば当然の要求ですが、DAW開発者にとっては既存のピアノロールGUIと衝突しないよう設計する必要があるため、実は大きな課題になっています。

歌詞入力はオプションではなく必須——ピアノロールへのインライン歌詞入力の概念図
② Phonetic Symbols Handling(発音記号の処理)
テキストを音に変換する際、単純な辞書引きでは対応しきれないケースがあります。英語の “Close” は文脈によって [k l ow s] にも [k l ow z] にもなりますし、”Wind” は [w ih n d](風)にも [w ay n d](巻く)にもなります。さらに “I Love You” という歌詞に対して [v] の音素を [f] に置き換えたい、つまり「ラヴ」ではなく「ラフ」のように発音させてウィスパーっぽい表現にしたい、といったアーティスティックな意図を持つユーザーもいます。単純な辞書変換だけでは、こうした表現の自由度を担保できません。

単純な辞書引きでは不十分——発音記号の扱いに関する2つの課題
③ Future Context / Look-ahead(先読み)
これが最も根本的なアーキテクチャ上の問題です。MIDIをはじめとする従来のプラグイン規格は「イベント駆動型(Event-Driven)」を基本としており、ノートオンが来たら音を出し、ノートオフが来たら止める、という設計です。しかし自然な歌声を合成するには、「次に何が来るか」を事前に知っておく必要があります。
スライドには “And I Will” という3つのノートのシーケンスが図示されていました。”I” の音符の音色が [a] から [y] へとなめらかに変化するためには、この音符がいつ終わるかを知っていなければなりません。また、”Will” の語頭子音 [w] は、ノートオンのタイミングより前から発音が始まっていなければ自然に聴こえません。こうした先読みの必要性が、イベント駆動型の現行アーキテクチャとは相いれないのです。
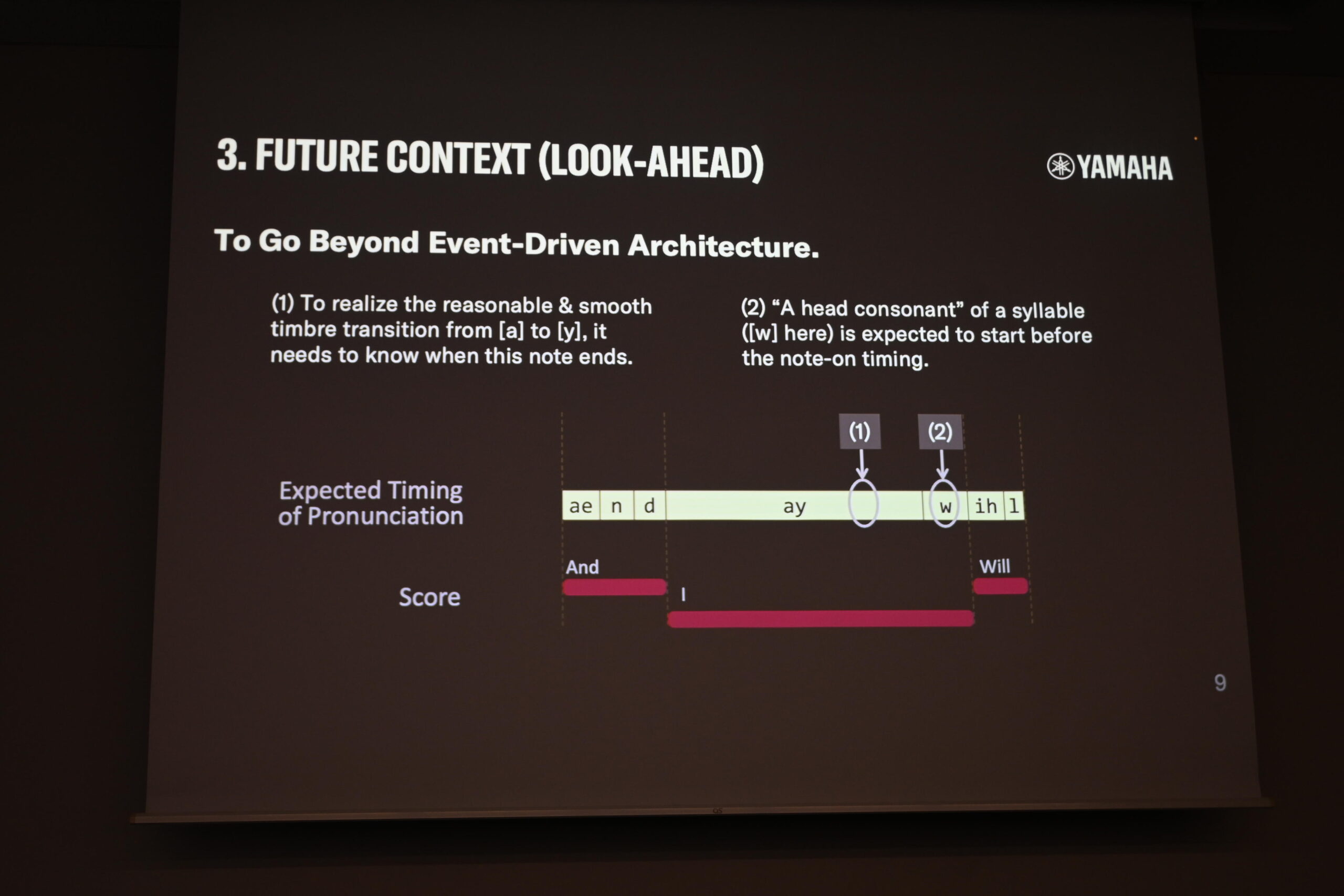
「And I Will」のシーケンスで示す先読みの必要性。ノートの終わりと次の語頭子音を事前に知ることが自然な歌声合成に不可欠
④ Background Rendering(バックグラウンドレンダリング)
SVSは通常、フレーズ全体を解析してから自然なボーカルを生成します。これは重い処理であるため、再生ボタンを押した瞬間にまとめて計算しようとすると、数十秒待たされることもあります。バックグラウンドで先行して処理しておく仕組みが欠かせませんが、通常のプラグイン規格ではこれも容易ではありません。

バックグラウンドレンダリングの仕組み。再生開始時の重い処理を事前に行うことで遅延を回避する
Cubase + プライベートAPIで突破口を開く
才野さんは「今回の発表は、自社製品を宣伝することが目的ではない。設計原理を抽出し、業界に共有することが目的だ」と明言していました。その前提のうえで、Omnivocal Betaが上記4つの課題をどのように解決したかを説明しました。
鍵となったのは、CubaseとヤマハSteinbergグループとの特別な関係から生まれたプライベートAPIです。このAPIにより、Omnivocal Betaはピアノロール上のノートオブジェクトへのランダムアクセスが可能になっています。読み取りだけでなく書き込みもできるため、変換した発音記号情報をノートのテキストフィールドに書き戻す、といった処理も実現できています。

CubaseのプライベートAPIを介してOmnivocal BetaがノートへランダムアクセスできるアーキテクチャのUnidia
歌詞入力(課題①)については、CubaseがノートオブジェクトにTextフィールドを持っていることを利用し、そこに歌詞と発音記号をともに格納する方法を採りました。”Sky” という歌詞を入力すると、プラグインがそれを発音記号 [s k ay] に変換し、ノートのTextフィールドに書き戻す形です。
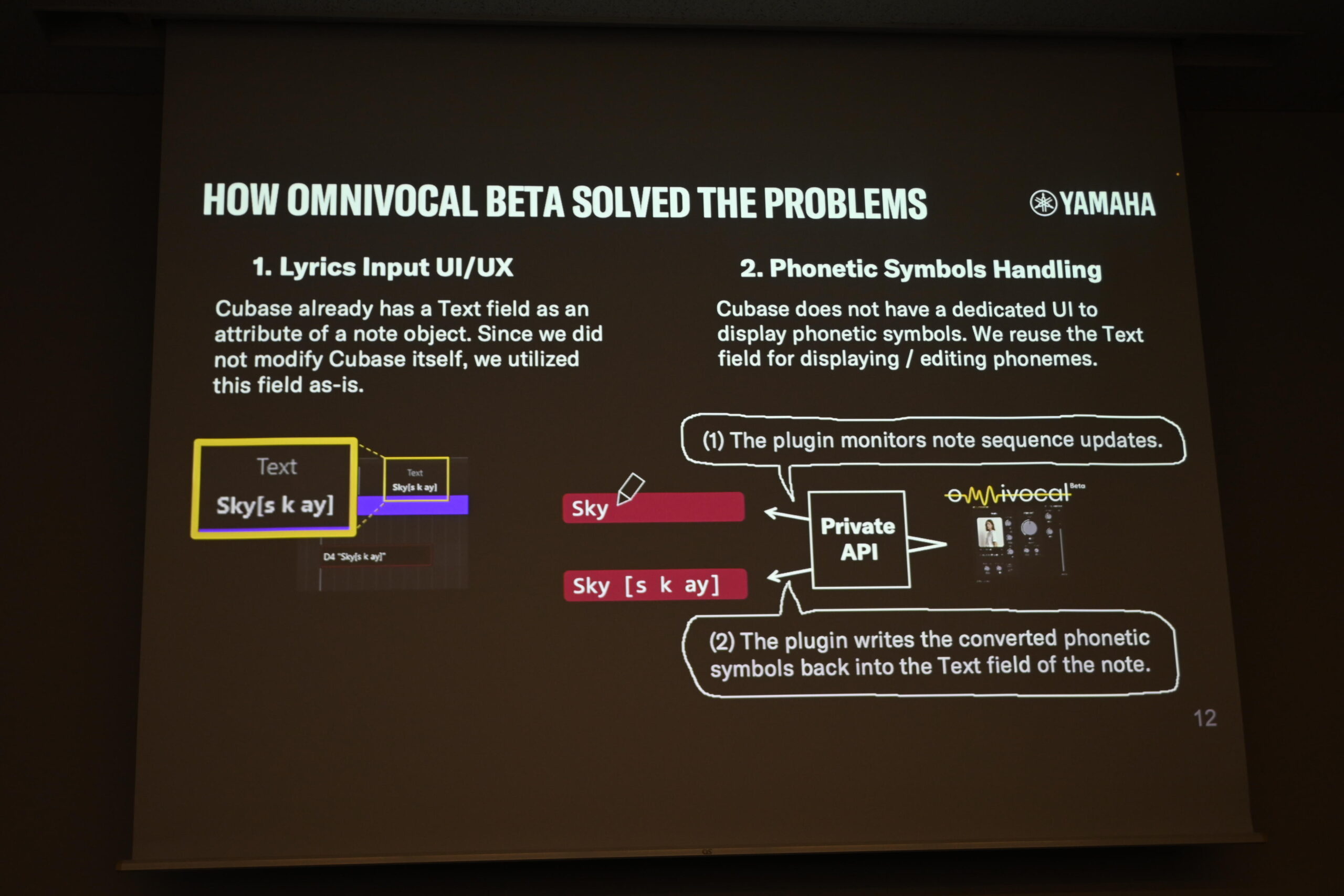
歌詞・発音記号の課題をCubaseのTextフィールド活用で解決する仕組み
バックグラウンドレンダリング(課題④)については、独自の「2ステップレンダリング」戦略で対応しています。STEP 1ではバックグラウンドでフレーズ全体を解析し、音楽的コンテキストを含む「Embedding Vectors(埋め込みベクトル)」を生成します。STEP 2では再生と同時に、このEmbedding Vectorsをもとにリアルタイムで音声を合成します。波形を直接レンダリングする方式では再生中のパラメーター変更が音に反映されませんが、2ステップ方式ならノブ操作がリアルタイムで合成に影響します。

2ステップレンダリング戦略。バックグラウンドでの埋め込みベクトル生成と再生時のリアルタイム合成に分けることで、パラメーター操作も即反映される
夢は「あらゆるSVSプラグインが、あらゆるDAWで動く」
しかしCubase + プライベートAPIという解は、ヤマハ/Steinbergというグループ内でしか成立しない特殊解です。才野さんが本当に問いかけたかったのは、「これをどうやって一般化するか」というより大きなテーマでした。
スライドには夢がこう記されていました。「Any SVS plugins work seamlessly with any DAWs in the world.(あらゆるSVSプラグインが、世界のあらゆるDAWとシームレスに動く)」。そのための汎用的なAPIやプロトコルとして、才野さんは4つの候補を挙げ、それぞれのメリット・デメリットを整理しました。

「どうやって一般化するか」——ホストとプラグイン間の理想的なAPIを問うスライド
VST3の拡張は世界で最も普及しているプラグインAPIというメリットがある一方、Logic ProやPro Toolsはサポートしていません。MIDI-CIは伝統的なMIDIフォーマットに基づきデータ形式が明確という利点がある一方、本来ハードウェアデバイス間の通信を想定した規格であり、ホストとプラグイン間の内部通信には設計思想が合わない面もあります。MIDI 2.0は歌唱に関連するメッセージが一部すでに組み込まれているものの、課題③「Future Context」の実現は単独では難しいとみられます。そしてARA3は前回のADC(ロンドン大会)でアイデアが発表されたばかりの新しい規格で、MIDIイベントへのランダムアクセスが可能になるという点でSVSの課題に最も直接的に対応できる可能性がありますが、普及率という問題があります。

VST3拡張・MIDI-CI・MIDI 2.0・ARA3、4つの候補のメリット・デメリット比較
いずれの選択肢も一長一短あり、才野さんは「まだ答えは出ていない。だからこそ今日、皆さんと一緒に考えたかった」と述べました。
業界全体への「協働の呼びかけ」
セッションの締めくくりは「Call for Collaboration(協働の呼びかけ)」と題したTakeawaysスライドでした。DAW開発者へは歌詞入力と発音記号への対応を、プラグインAPIデザイナーへはFuture Contextの実装を、SVSプラグイン開発者へは歌詞・発音記号のデータモデルの共通化を——それぞれ呼びかけています。

「DAW・SVSプラグイン・APIを作る人は、ボーカルに必要な最低限の要件をすり合わせよう」というCall for Collaborationスライド
「If you build DAWs, SVS plugins, or APIs, let’s align on a minimal set of requirements for vocals.」——ヤマハという大企業が、自社ソリューションを押し付けるのではなく、問題の構造を丁寧に解説して業界全体に議論を呼びかけるというスタンスが印象的でした。SVSがDAWに完全統合される未来はまだ先かもしれませんが、「DAWが歌う」という当たり前のように見えて誰も実現できていなかった夢に向け、確かな一歩が踏み出されています。
日本でオーディオソフトウェア会社を立ち上げる方法
ADC Japan 2026の3日目に行われたこのセッションは、タイトルからして異色でした。「How to Start an Audio Software Company in Japan」——技術の話ではなく、ビジネスの話、しかも日本市場という極めて具体的な文脈での話です。登壇したのはDreamtonicsのカンル・フア(Kanru Hua)さんと、AHS(エーエイチエス)の代表取締役である尾形友秀さんのふたり。それぞれの立場から、日本でオーディオソフトウェアビジネスを築いてきた経験を語りました。

登壇した尾形友秀さん(左)とカンル・フアさん(右)
上海からイリノイ大学を経て、東京へ——カンル・フアさんの軌跡

上海→イリノイ大学(2015-2018、途中退学)→東京(Dreamtonics・AHS)というカンル・フアさんの経歴紹介スライド
カンル・フアさんの自己紹介スライドにはシンプルな矢印が描かれていました。「Shanghai → Univ. of Illinois (2015-2018 Dropout) → Tokyo (Dreamtonics, AHS)」。歌声合成の研究からソフトウェアエンジニアリング、そしてプロダクトへ——この経歴の線を引くものは一貫して歌声への情熱です。
カンルさんが起業を意識したのは2016〜2019年頃。スタートアップブームの時代でした。「みんなスタートアップをやると言っていた。いいアイデアがあって、イベントがあって、開発チームが集まって大きな夢がある」——そんな時代の空気を率直に語りました。

「スタートアップとは何か」——多くの人がイメージする「アイデア→資金調達→開発→成長」というモデル
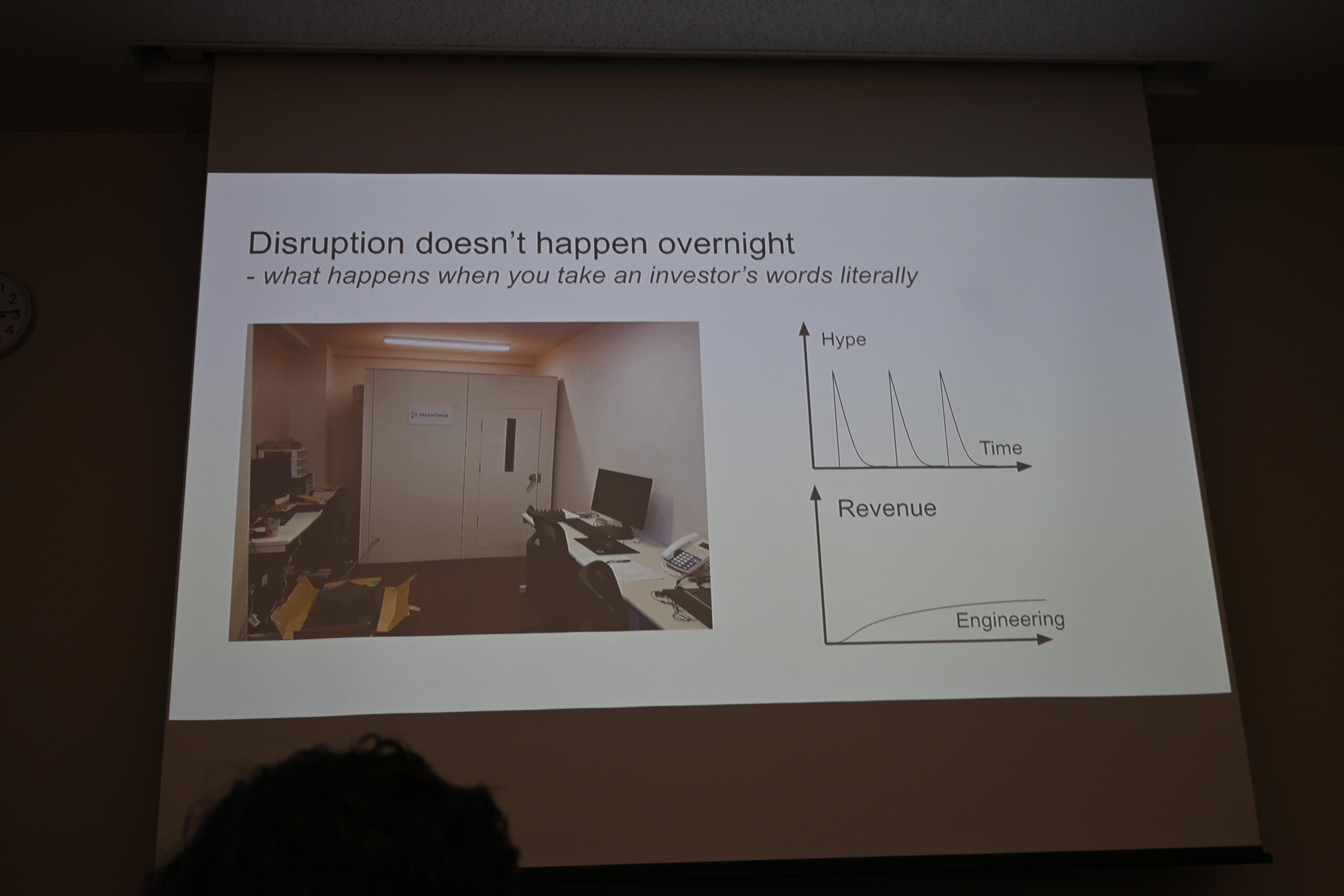
しかし自分が実際に辿り着いた場所は違いました。2019〜2020年当時のカンルさんの状況をスライドはこう記していました。「製品がある。顧客がいる。自分が食べていける程度の収益がある。でもリーチできる市場は小さく、LLMはまだ存在しなかった」。その頃、シェアオフィスの隣にいた投資家からかけられた言葉が印象的です。

「最高の歌声合成を作りたかっただけ。でも投資家には『あなたは遅すぎる』と言われた」
「最高の歌声合成を作りたかっただけなんです。でもその投資家は言った。『あなたは遅すぎる』と」。カンルさんが学んだのは「Bootstrapping(ブーツストラッピング)」という考え方です。外部から資金調達せず、小さな製品を出して収益を生み、それでビジネスを継続していく手法で、実際Dreamtonicsはその戦略を取り徐々に規模を拡大してきました。
エンジニア創業者の落とし穴
カンルさんの発表で最も説得力があったのが、「An Engineer-Founder’s Mental Model(エンジニア創業者の思考モデル)」というスライドでした。

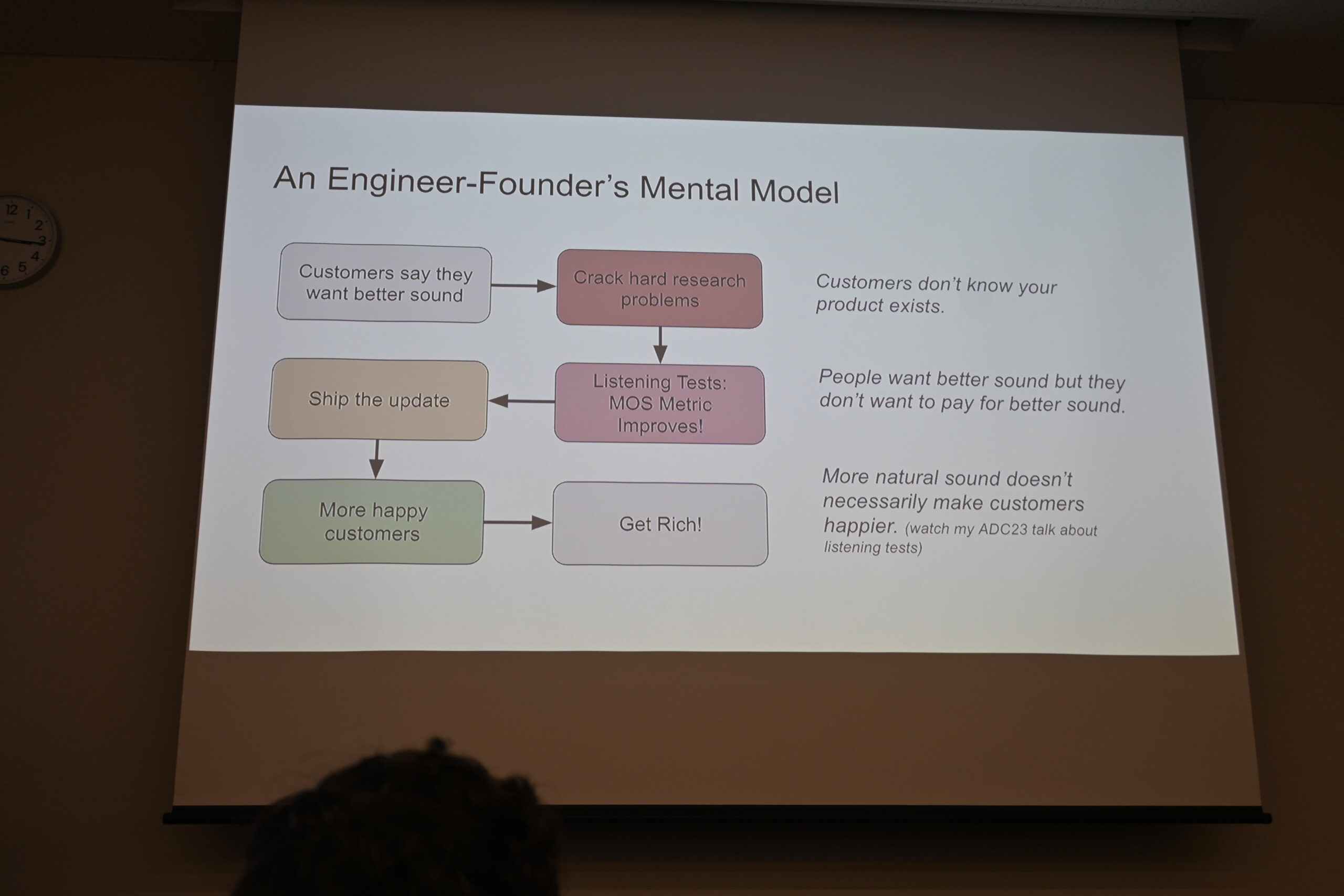
エンジニア創業者が思い描く理想のモデル——「研究課題を解く→MOS改善→リリース→顧客が喜ぶ→Get Rich!」
エンジニアが思い描く理想のビジネスはこうです。「顧客が『もっといい音を』と言う→難しい研究課題を解く→MOS(Mean Opinion Score)が改善→アップデートをリリース→顧客が喜ぶ→Get Rich!」——しかし現実はそうではありませんでした。
現実には「顧客は製品の存在を知らない」「いい音にお金を払いたくない」「音が自然になっても顧客は必ずしも幸せにならない」という壁がある
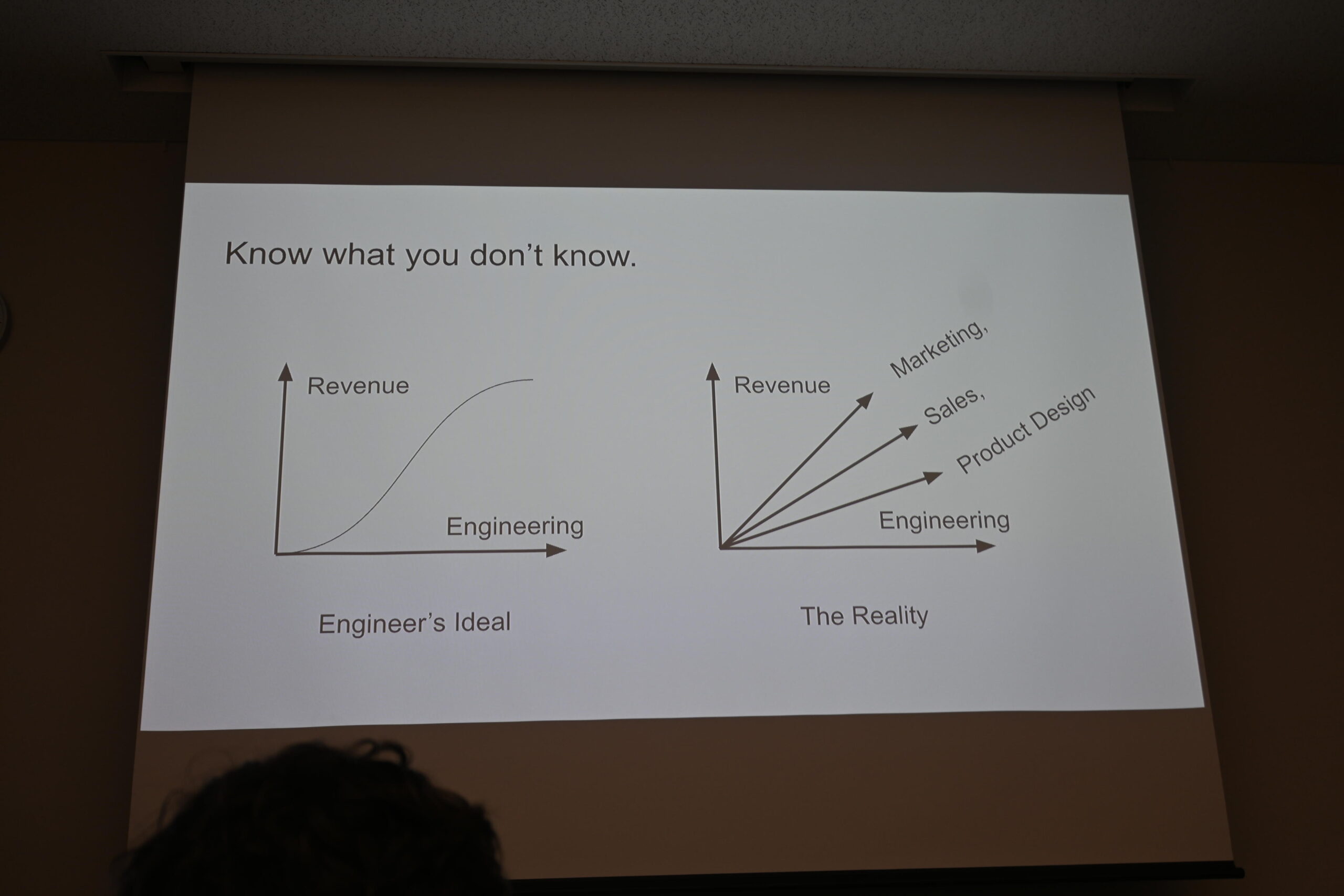
エンジニアの理想(Engineeringだけ)と現実(Marketing・Sales・Product Designも必要)の対比——「自分が知らないことを知っている必要がある」
採用についても具体的な数字を出しました。日本の主要な求人プラットフォームで採用活動を行うのに約50万円(3000ドル)かかり、オンボーディングには数ヶ月間、自分の時間の20%が取られます。そして重要なアドバイスとして「エンジニア創業者なら、2人目のエンジニアではなくエンジニア以外を最初の社員にすること」を挙げました。
最初の社員採用の現実——採用広告に約50万円、オンボーディングに数ヶ月間・時間の20%が必要
日本市場は「外から見える天守閣と、中に入った城全体」

日本のオーディオ市場を姫路城にたとえる——外から見える天守閣(赤丸)と実際の城全体のギャップ
日本のオーディオ市場についての説明に、カンルさんは姫路城の写真を使いました。遠くから見える白い天守閣を赤い丸で囲み、「これが外から見える日本市場のイメージ」と。実際に城の中に入ってみると複雑な堀や曲輪(くるわ)が広がっていることにたとえ、「見た目と実態が違う市場」と表現しました。

「あなたの役割は価値を届けること。顧客は安心感と信頼感を求めている」——日本市場攻略の心構え
BCNランキング連続No.1——尾形友秀さんが語る日本市場の現実

尾形友秀さんのセッション「A music software company, in Japan.」タイトルスライド
後半は尾形友秀さんの番です。尾形さんはDreamtonics Inc.とAHS Co.Ltd.の両社に関わる立場から、日本市場での経験をたっぷりと語りました。

尾形友秀さんの自己紹介——音楽とプログラミングを幼少期から学び、コンピューター関連事業約30年、AHSは国内シェアNo.1
AHSはBCNランキングにおいて、音楽部門で3年連続、ユーティリティ部門では9年連続でNo.1を獲得しています。その主力製品はSynthesizer V(歌声合成)、VOICEPEAK(テキスト読み上げ)、Vocoflex(声質変換・新しい声の作成)の3本です。

BCN AWARD 2026でサウンド関連ソフト部門3年連続、ユーティリティソフト部門9年連続受賞
ローカライズについて尾形さんが提示した5つのポイントは、長年の現場経験から来るものとして非常に具体的でした。①文化を理解する、②UIの導入は省略しない、③万人向けUIは存在しない、④大事なのは思想、⑤発信し続ける——の5点で、「届くものは、作り手の考えを渡すもの。だからこそ自分の考え方をきちんと込めておく」という哲学で締めくくられていました。

ローカライズの5つのポイントと「What reaches people carries its maker’s thinking(届くものは、作り手の考えを渡すもの)」
「日本人はなぜパッケージを買うのか」——秘密の数字
尾形さんが「あまり人に言ったことない数字を持ってきた」と前置きして公開したのが、パッケージ版の販売比率の推移でした。
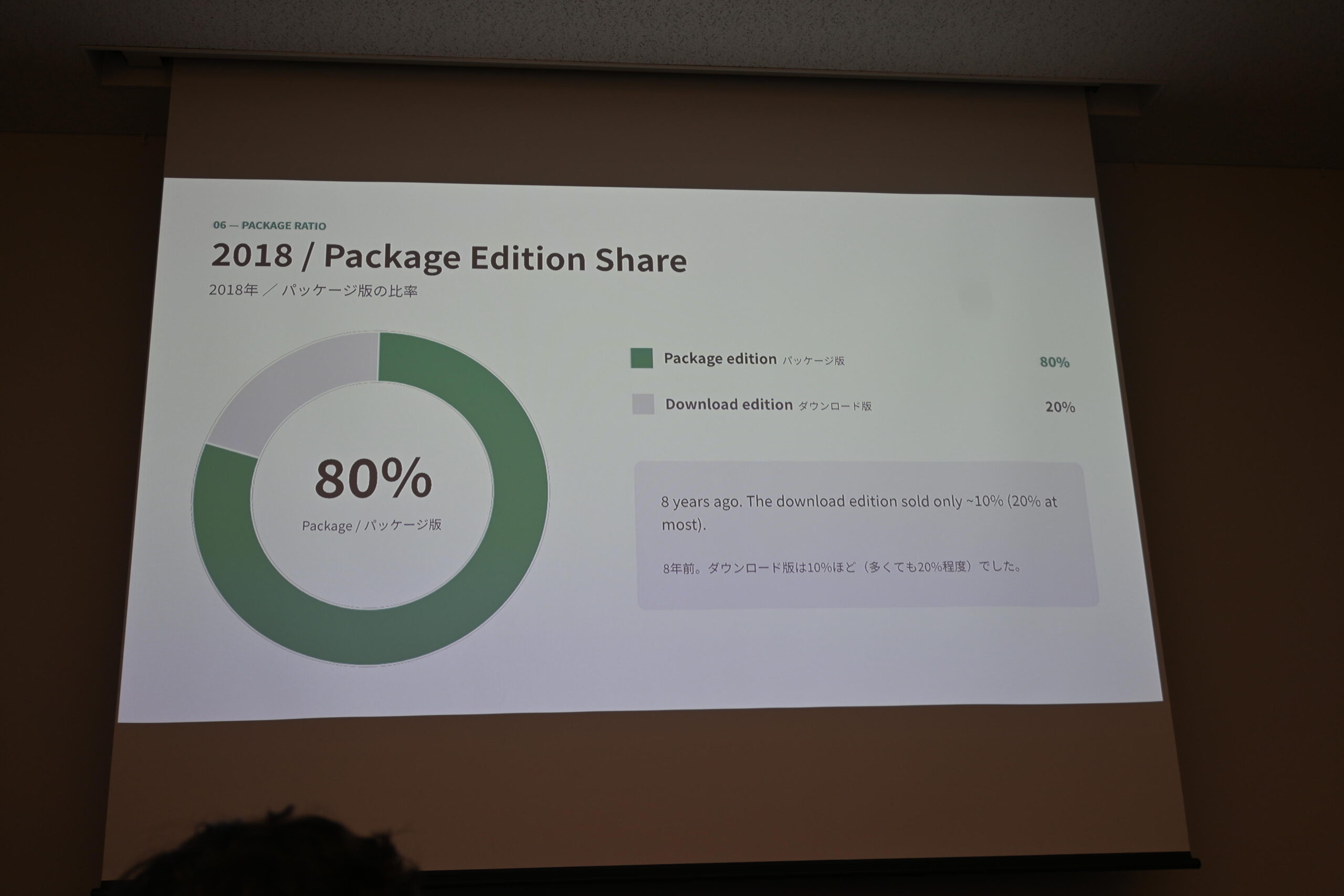
2018年のパッケージ版比率——80%がパッケージ、ダウンロードはわずか20%
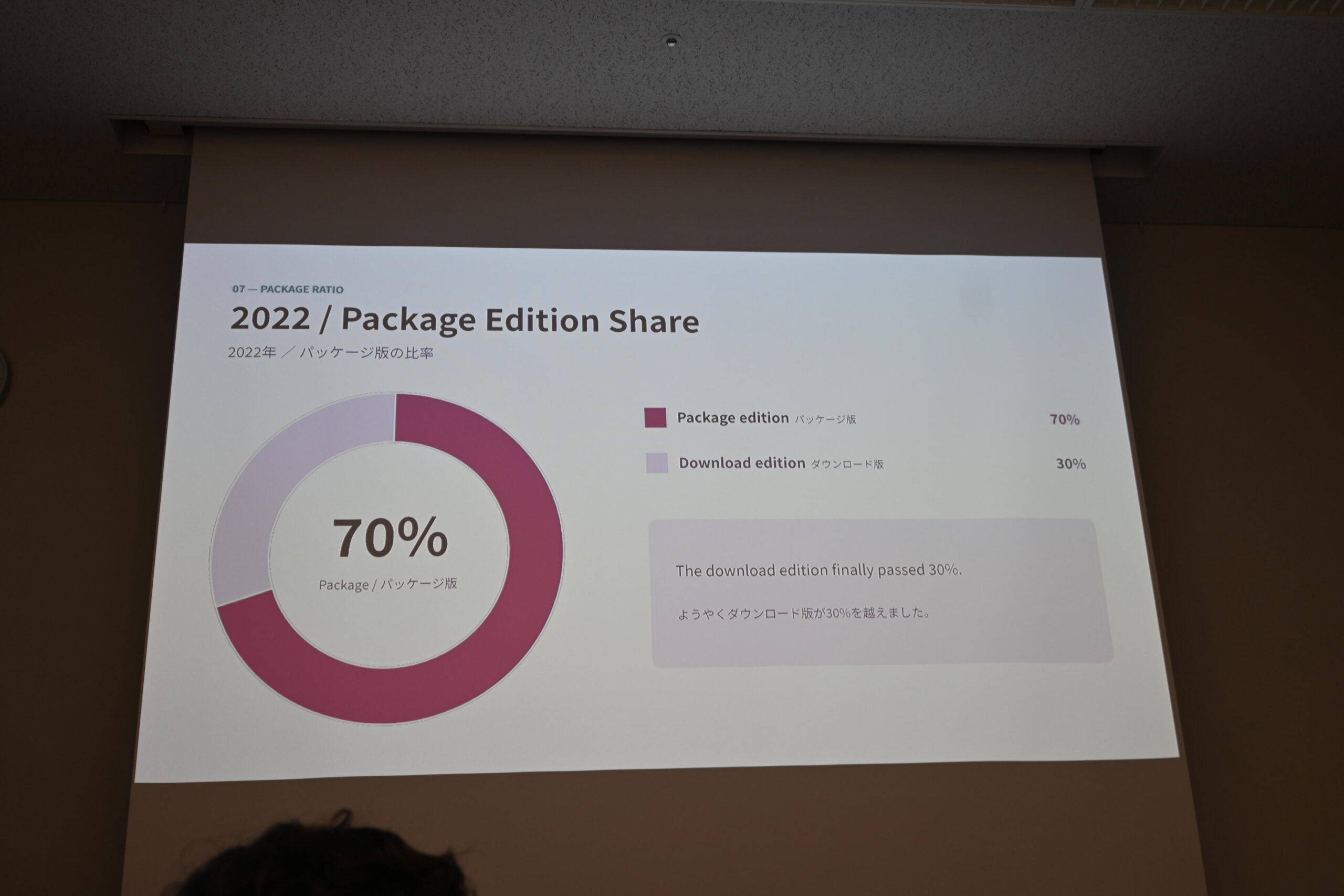
2022年でもパッケージ70%。ようやくダウンロードが30%を超えた
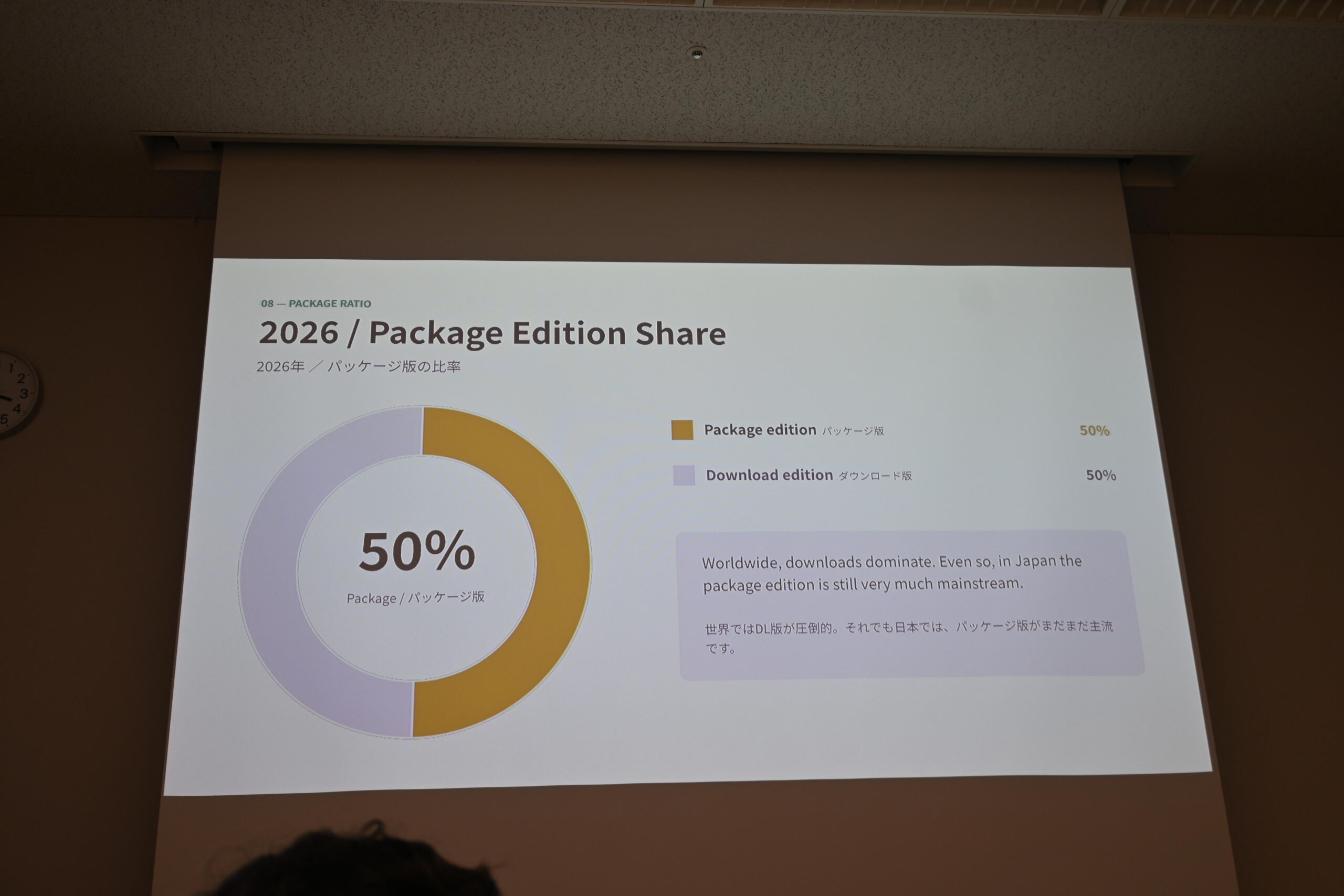
2026年現在でもパッケージ50%——「世界ではDL版が圧倒的。それでも日本ではパッケージ版がまだまだ主流」
なぜ日本はパッケージが売れ続けるのか。会場近くのビックカメラ2階に実際に足を運んで撮影してきた写真も見せてくれました。VOCALOID、VOICEROID、Synthesizer Vのキャラクターが並ぶ「AKIBA A.I.VOICE ARENA Virtual Voice」というコーナーの写真です。

秋葉原ビックカメラ2階の「AKIBA A.I.VOICE ARENA Virtual Voice」コーナー——ボーカロイド・Synthesizer Vのパッケージが壁一面に並ぶ
Synthesizer Vのキャラクターを模したぬいぐるみ2体も会場に持ち込み、「どこにも出したことがない、まだ売っていない」とこのセッションで初公開するというサプライズも演出しました。

登壇者席の尾形友秀さんと、初公開のSynthesizer Vキャラクターぬいぐるみおよび製品パッケージ群
「声」という楽器への情熱
セッションの最後、尾形さんは自分がなぜ音声合成の世界に入ったかを語りました。
「声は表現の楽器だと思っています。30年ほど前からパソコンでドラムもギターもピアノも再現できるようになった。でも声だけはできなかった。自分も曲を作る側として、パソコンの中だけで全部完結させたかった」「素敵な声の方は世の中にたくさんいる。でも、亡くなったら声がなくなってしまう。そういう声を残しておきたいとずっと思っていた」——そして笑いを交えた告白として「アニメを作りたかったけど友達がいなくて声をつけてもらえなかった。だから音声合成を始めた」。
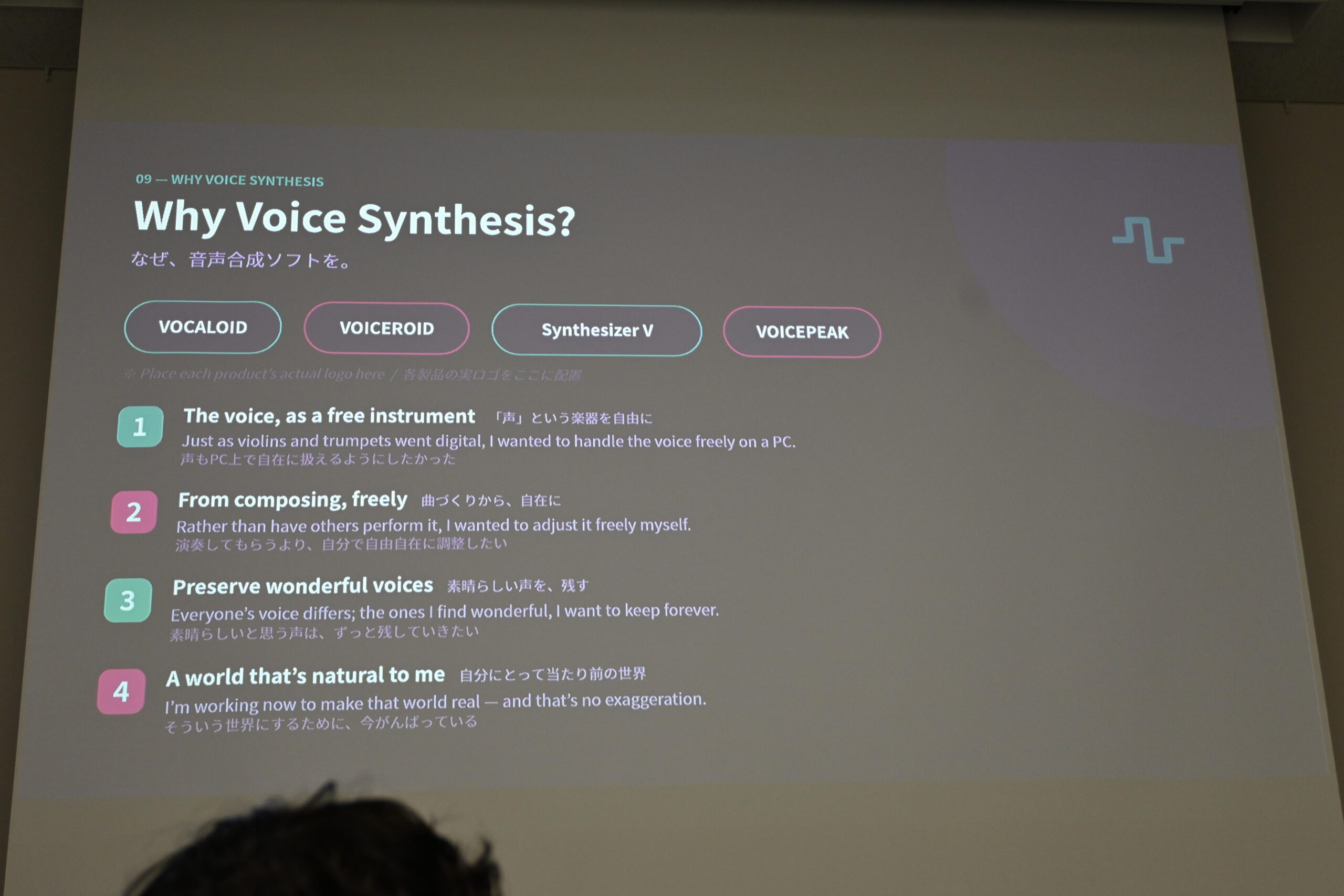
「なぜ音声合成ソフトを」——声という楽器を自由に、曲づくりから自在に、素晴らしい声を残す、自分にとって当たり前の世界の4つの動機
最後に尾形さんは言いました。「声はまだ足りない。最低200は必要。MIDIのプログラムチェンジが128+打楽器で約200だから、それが音楽制作に使える最低ラインだと思っている。そこまでいって初めて、音声合成が音楽の作り手たちにもっと浸透していけるのかなと思っている」。
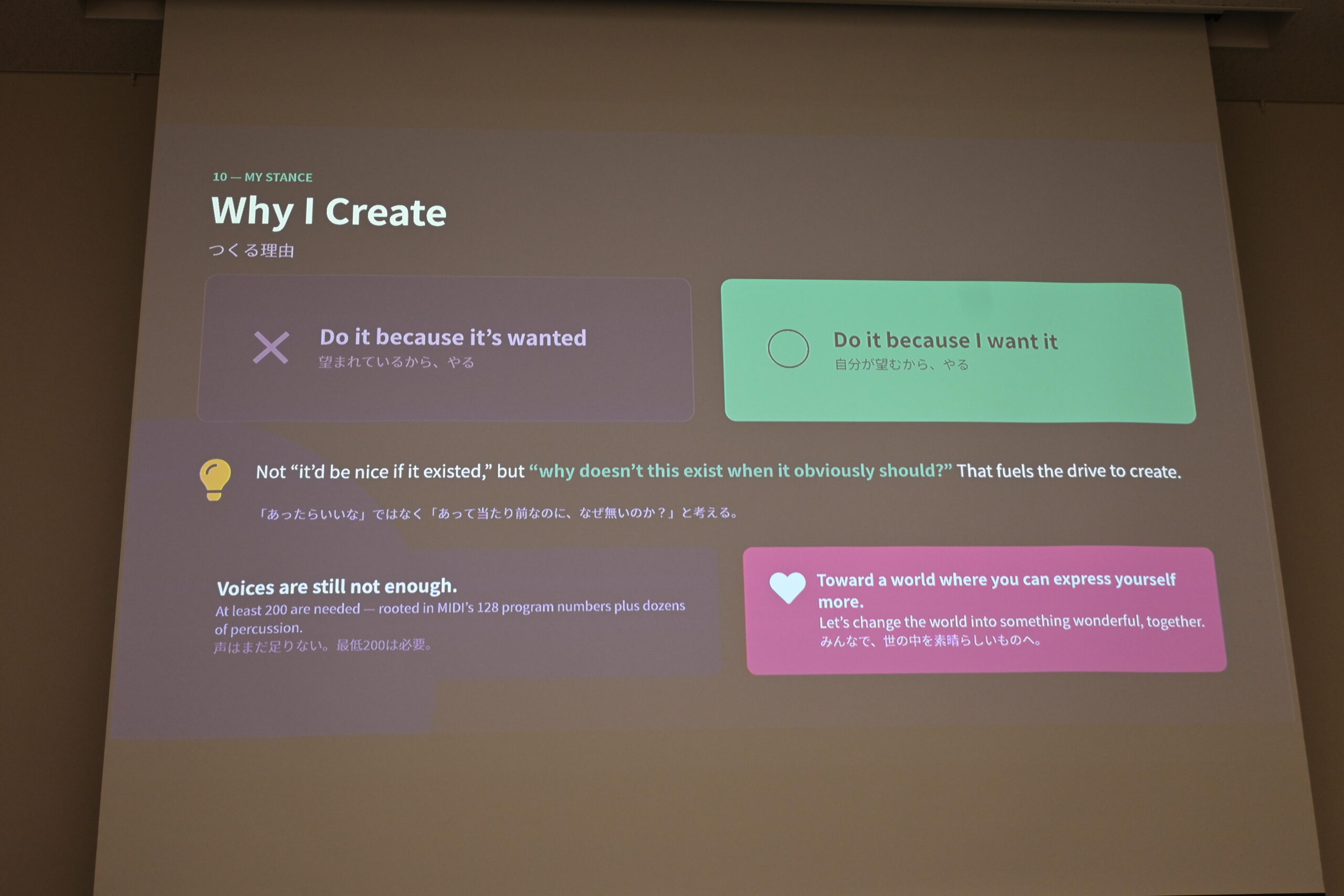
「望まれているからやるのではなく、自分が望むからやる」——「あって当たり前なのに、なぜ無いのか?」という動機が創作の原動力
「言われたから作るのではなく、こういう世界にしたいから作っていく——それが大事だと思っています」。尾形さんのこの言葉が、このセッション全体を貫くメッセージでした。
【関連記事】
秋葉原UDXで開催された第1回ADC Japan 2026。オーディオ開発者のための国際カンファレンスがついに日本上陸
【関連情報】
ADC Japan 2026サイト


コメント