ここ数年で、声を変換する技術が急速に進んでいます。いわゆるボイスチャンジャーの技術が進化していますし、DTMステーションでも何度も取り上げているクリムゾンテクノロジーのVoidol/リアチェンvoiceなども、画期的技術だと思います。ただ、従来の声の変換だと、どうしても元の声、イントネーションなどに引っ張られるため、なかなか思い通りの声にならないという問題点がありました。
そうした中、いまにわかに脚光を浴びる形になったのが、コンピュータによる読唇術(どくしんじゅつ:機械読唇ともいわれています)です。声を発せずに、口の動きだけで何を言っているかを認識した上で、それに音声合成を組み合わせれば、究極のボイスチャンジを実現できるのでは……、という発想なのですが、その技術研究のためのクラウドファンディングがスタートしたのです。これは先日「AIきりたんに次ぐ第2のAIシンガー、東北イタコの歌唱データベース制作プロジェクトのクラウドファンディングスタート」で取り上げた歌唱データベースのクラウドファインディングが成功したため、次のステップとして発表されたストレッチゴール。やや唐突ともいえる内容だっただけに、状況を理解できない人も少なくなかったと思います。そこで、このクラウドファンディングの主旨を整理するとともに、この読唇術の研究を行っている九州工業大学の大学院情報工学研究院 准教授の齊藤剛史先生にお話しを伺ってみました。
 コンピュータによる読唇術を実現するためのクラウドファンディング実施中
コンピュータによる読唇術を実現するためのクラウドファンディング実施中
どんどんDTMから、それていくDTMステーションではありますが、今回取り上げる読唇術は、さらに未来の世界へ導いてくれる技術のようです。
先日達成したAI歌声合成DB作成のためのクラウドファンディングのストレッチゴールとして読唇術用DB作成が発表に
「東北イタコは歌いたい!しゃべりたい!東北イタコ音声合成データベース制作プロジェクト」のクラウドファンディングを展開している、SSS合同会社のCEO小田恭央さんに聞いたところ「おじさんが女の子の声になりきる究極のボイスチェンジャーはどうやったらできるのだろう……といろいろ調べていた中、口の動きを元にテキスト変換するという齊藤先生の研究に行きついたのです。1年ほど前、 独立行政法人科学技術振興機構の展示会で、先生が東京にいらしたタイミングがあったので、『ファンなんです!』と言ってお声がけさえていただいたのが、今回のプロジェクトのキッカケでした」と説明してくれました。
 九州工業大学の齊藤先生(左)、SSSの小田さん(右)と私(中)でZOOM取材を実施
九州工業大学の齊藤先生(左)、SSSの小田さん(右)と私(中)でZOOM取材を実施
その小田さんに仲介していただく形で、先日、齊藤先生、小田さんと3人でオンラインミーティングの形でインタビューしてみました。
ーー読唇の研究者がいるということを全く知らなかったのですが、もともとどんな目的で研究をはじめられたのでしょうか?
齊藤:読唇技術は、音声情報を利用しないで言葉を読み取る技術なのので、声を出せない方を支援すること、医療従事者へのコミュニケーション支援のための研究というのが大きな目的です。でも、それだけでなく騒音環境でも使えるし、静かにしておく必要がある場所での利用にも役立ちます。使用機器はカメラだけでいいので、カーナビで音楽を流しながら指示するのにも使える可能性があるし、バイオメトリックス認証との組み合わせなどの応用も考えられるだろうと、進めてきた経緯があります。

--そこに、今回、ボイスチェンジャー的な目的が追加された、と。
齊藤:小田さんからコラボ企画を持ちかけていただいたのですが、自分のしゃべる言葉を、ほかの声優さんの声に変換するという発想はまったくなかったので、最初は驚きました。もちろん、それが簡単に実現できる段階にはないのですが、とても面白い応用例だと思いました。
ーー改めてその読唇技術とはどういうものなのか基本的なことを教えていただけますか?
齊藤:読唇技術のルーツは電話を発明したグラハム・ベルの父である聾唖教育家のメルビル・ベルが18世紀に発明したとされています。日本に紹介されたのは昭和初期と言われていますが、読唇自体は、きっと大昔から何等かの形であったとは思います。ただ読唇は非常に難しく、人による読唇精度は30~40%と言われています。というのも口の形は母音によってほぼ決まるため、たとえばア段=(あ、か、さ、た、な、は、ま、や、ら、わ)の口の形はほとんど変わらないのが大きな要因です。また音声認識と共通の問題もあり、同音異義語を見分けるのが非常に難しい。「橋」と「箸」、「端」の違いは口の動きからはまったく分かりません。それに加え読唇技術固有の問題もあるのです。同口形異音語といいますが、「タバコ」、「卵」、「なまこ」の口の動きはそっくりで見分けが付かないし、類似口形語といいますが「売る」、「浮く」、「来る」、「付く」もほぼ同じに見えます。また口形変化の少ない言葉として「一日中」とか「イチジク」、「救急車」といったものもあり、見た目からは判別しにくいのです。

ーー確かにそうですね。そんなことまったく考えたこともなかったですが、簡単なことではなさそうです。
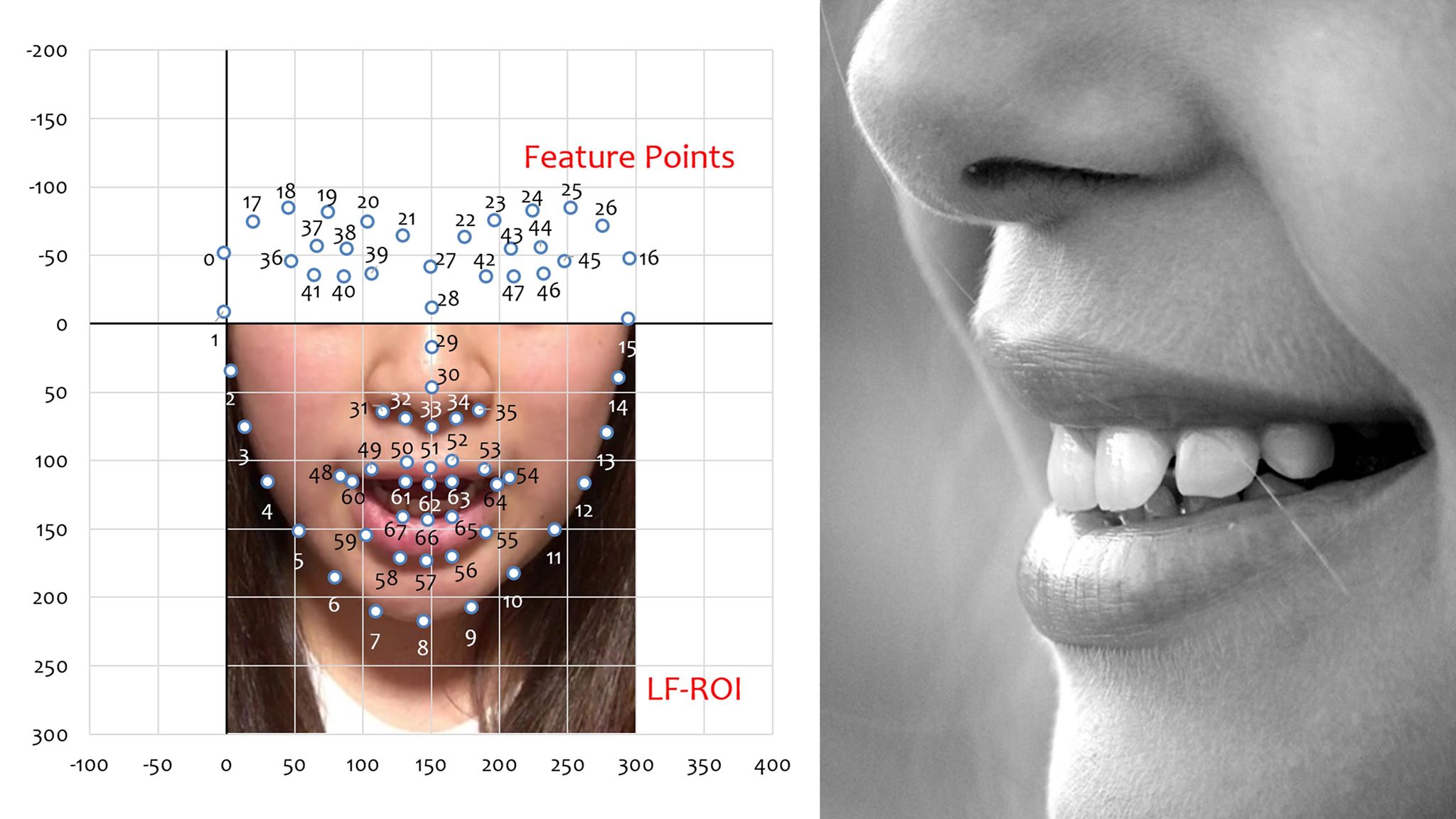
齊藤:ほかにも課題は山積みなんです。研究に利用できる発話シーンというのが少ないのが大きな問題でもあります。英国Oxford大学の研究グループがBBCの映像を利用して研究したケースはあるものの、顔が映る映像であるため研究用とはいえ、利用できる映像の収集がしにくいし、人によって口形や唇の動きが異なるのも問題。また日本語の公開データが少ないのも難しいところです。さらに実際に研究用に使うには事前に顔画像処理をしておく必要もあり、顔の特徴点の検出など読唇以外の関連技術も必要となってきます。そして研究者が少ないこと。研究者を増やさないことには、なかなか進まないですからね。
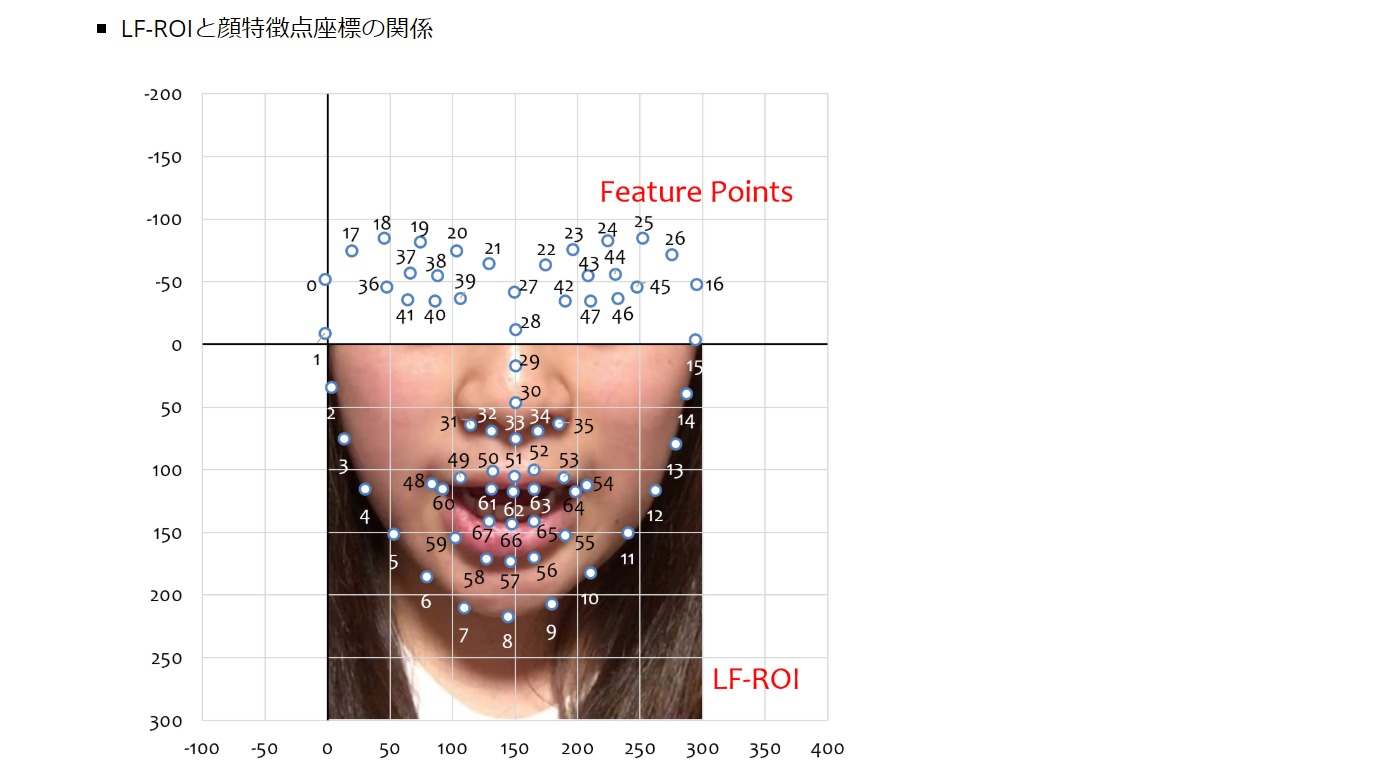 研究用のデータベースにするためには事前に顔画像処理をしておく必要がある
研究用のデータベースにするためには事前に顔画像処理をしておく必要がある
ーーそうした中、先生のところで、デモンストレーションを行うWebアプリを公開していると先日、小田さんに伺いました。
齊藤:はい。ユーザー登録が必要ではありますが、口の動きがあるビデオを撮影し、それをここにアップロードすると、何と言ったかを推定するWebアプリケーションです。ただし、ここで認識できるのは日本語の25の言葉に限られます。具体的には「ぜろ」~「きゅう」までの数字と、「おはよう」、「こんにちは」などの挨拶です。これは主に学生、72名の人たちの25単語の発話シーンを15回ずつ記録したビデオ、全27,000サンプルをディープラーニングして開発した世界初の読唇Webアプリです。
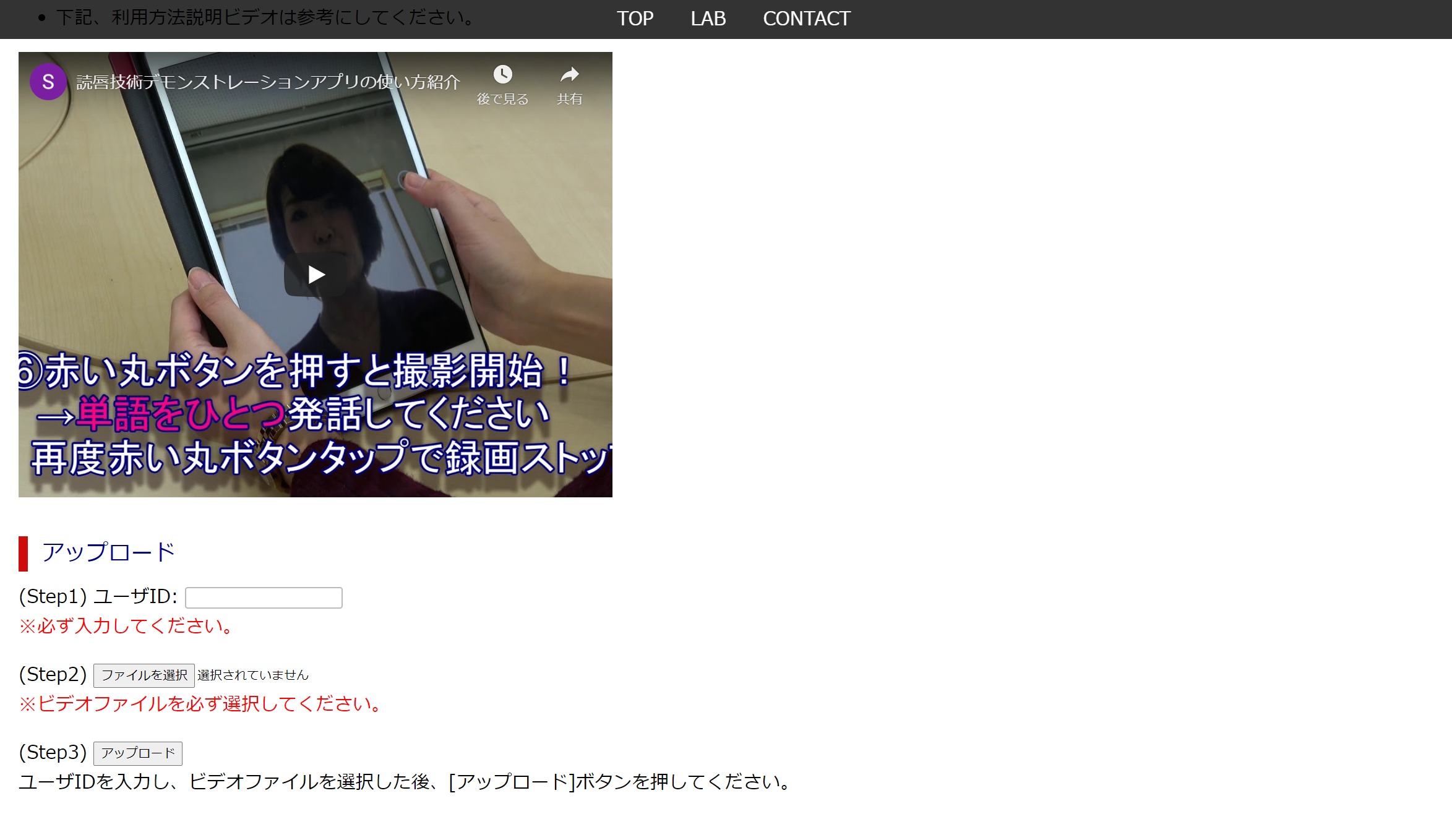 ユーザー登録すれば誰でも使える世界初の読唇Webアプリが公開されている
ユーザー登録すれば誰でも使える世界初の読唇Webアプリが公開されている
ーー限られた言葉で、しかも単語であるので、まだ実験段階という印象ではありますが、試してみるとすごく面白いですね。
齊藤:これが実現できたのは、72名のしゃべったビデオのデータベースがあったからこそで、私たちの研究において難しいのは、そうしたデータベースがほとんどないということなのです。この72名の発話シーンを元にしたデータベースは研究者用に公開していますが、そうしたものが増えてくれば、読唇技術の研究も進んでくるはずです。
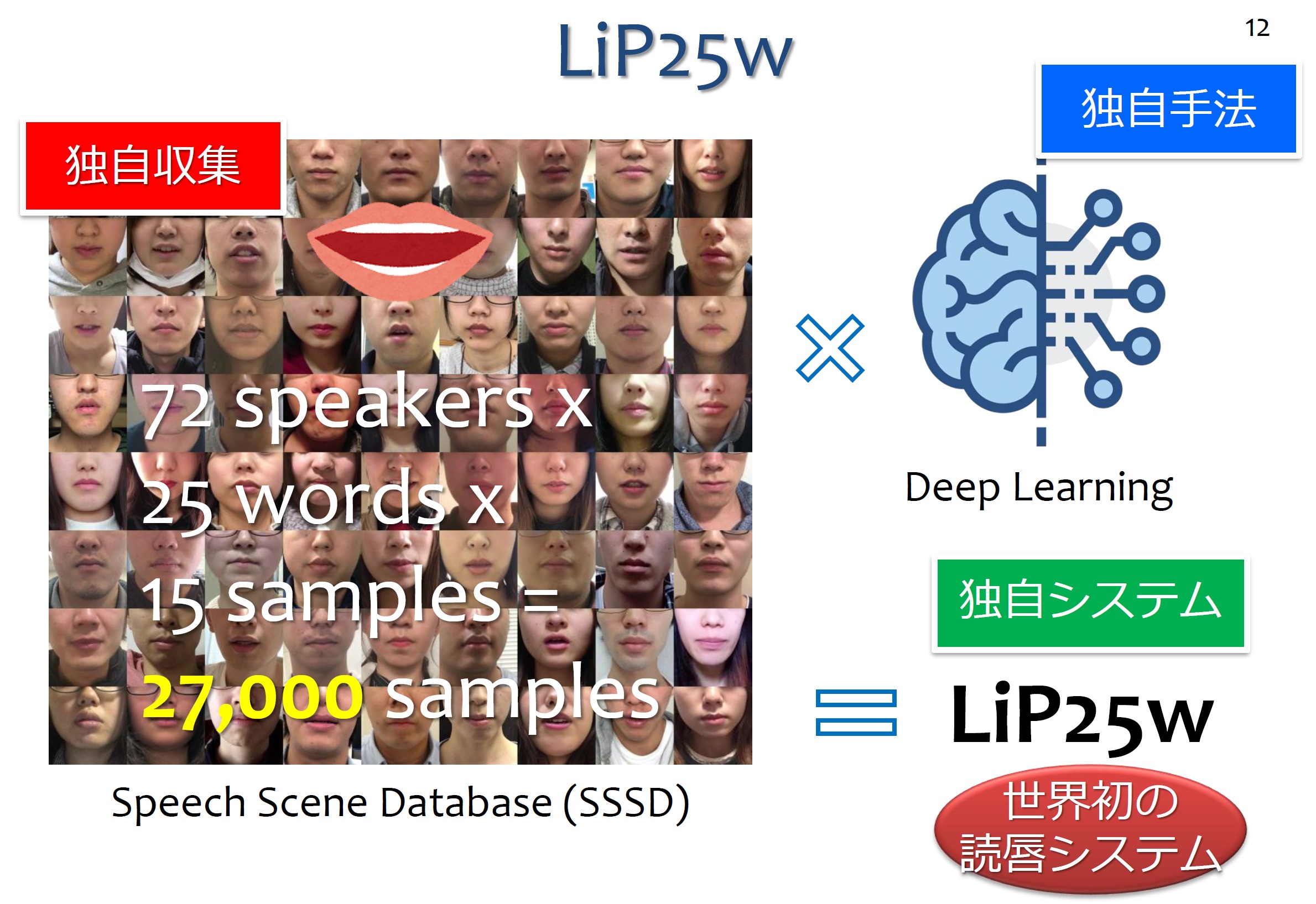 読唇Webアプリの実現には72人による計27,000もの発話シーンのDBが使われている
読唇Webアプリの実現には72人による計27,000もの発話シーンのDBが使われている
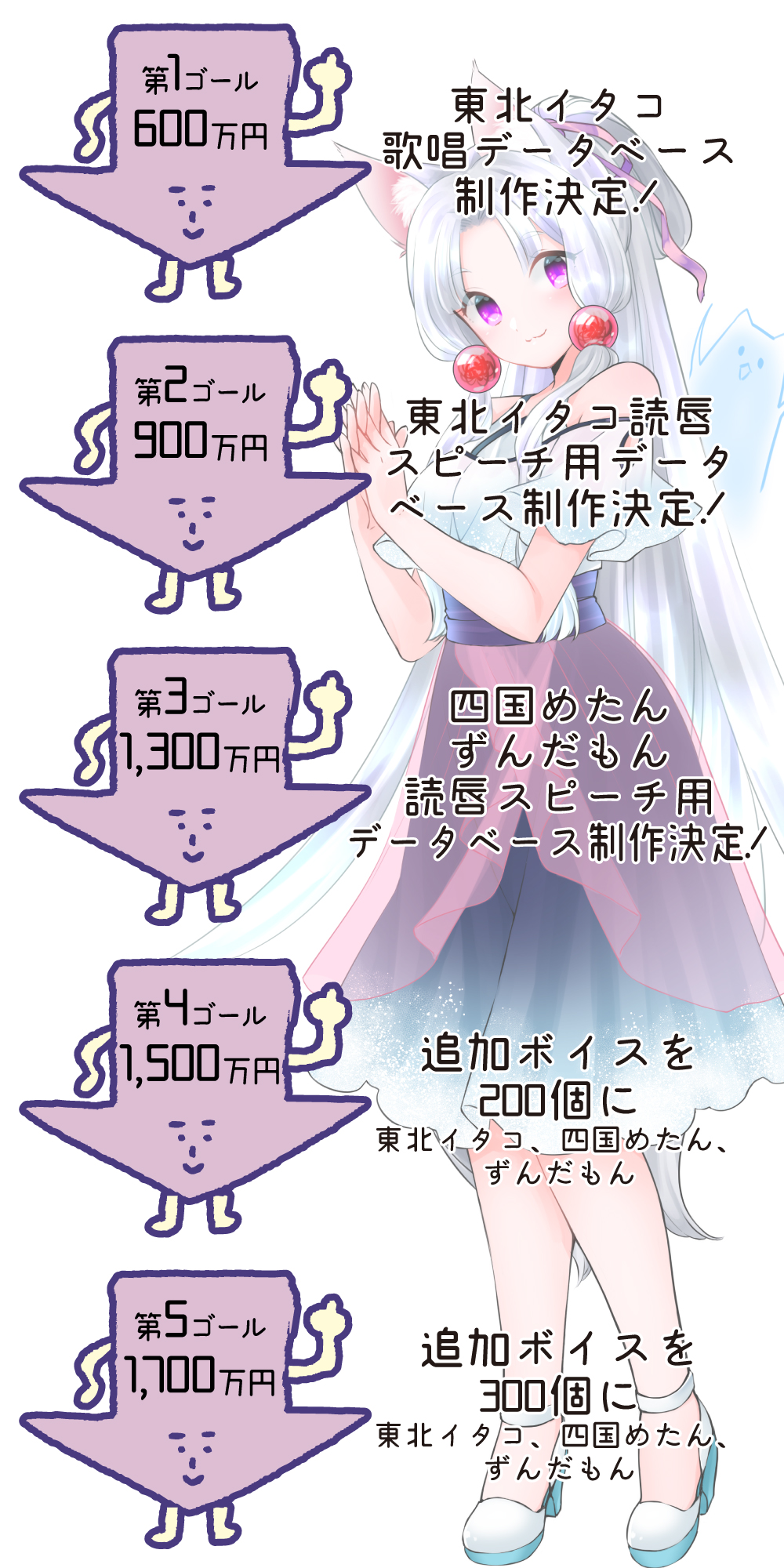
ーーなるほど、それがそれが今回のクラウドファンディングに合致するところなのですね。実際、ストレッチゴールを見てみるといくつかあるようですが、具体的にはどんなことが行われるのですか?
小田:150%達成の第2ゴールに到達したら、イタコ姉さまの声優、木戸衣吹さんの発話シーンを収録してデータベース化していきます。ここでは500の文章を木戸さんに読み上げてもらい、その口の動きをビデオで収録。それを映像処理、音声処理をして整理した上でデータベース化していくのです。その映像処理は齊藤先生にお願いし、音声処理のほうは明治大学の森勢将雅先生にお願いする予定です。
 コンピュータによる読唇について、優しく解説してくれた九州工業大学の大学院情報工学研究院の齊藤剛史先生
コンピュータによる読唇について、優しく解説してくれた九州工業大学の大学院情報工学研究院の齊藤剛史先生
齊藤:データベース化するためには、ビデオを元に口がどこにあり、鼻がどこにあるかなど、顔特徴点を抽出する前処理が必要になるので、そうした処理を行っていきます。ほぼ自動化できるようになっているので、その作業自体は数日でできるのではないかと思っています。
 150%達成の第2ゴールで木戸衣吹さんによる東北イタコの読唇データベースを作成
150%達成の第2ゴールで木戸衣吹さんによる東北イタコの読唇データベースを作成
小田:森勢先生側の音素ラベル付け作業のほうが、より多くの作業が発生しそうではありますが、そうした作業を並行して行っていきます。さらに217%達成の第3ゴールにきたら、四国めたんちゃん(CV:田中小雪さん)、ずんだもん(CV:伊藤ゆいなさん)にも参加してもらい、同じく500の文章を読み上げるデータベースを作っていく予定です。

217%達成の第3ゴールで田中小雪さんによる四国めたんちゃんDB作成
ーーその作られたデータベースは、誰でも見ることができるものなのですか?
小田:これは、すでに制作することが確定となった、イタコ姉さんの歌唱データベースと同様で、あくまでも研究者向けの公開となります。そのため一般の方々は、それによって出てくる研究成果を待つしかないのですが、さまざまな研究者に参加いただくことで、新しいものが生まれるのでは……と期待しているところです。読唇技術の研究者は国内に数えるほどしかいませんが、たとえばディープラーニングの研究者や画像処理の研究者に参加してもらうことで、これまでは見出すことができなかった、新たな成果が得られるのではないか、と。
 第3ゴールでは四国めたんちゃんに加え、伊藤ゆいなさんによるずんだもんDBも作成
第3ゴールでは四国めたんちゃんに加え、伊藤ゆいなさんによるずんだもんDBも作成
ーーストレッチゴールに達成したから、すぐに読唇術が完成するというわけではなく、その研究に貢献していこうというのが趣旨なわけですね。未来に向けた、とても意義のあるクラウドファンディングといえそうですね。ぜひ、ストレッチゴールが達成し、読唇技術の研究が大きく進んでくれることを楽しみに待っています。
改めて、お伝えすると、この「東北イタコは歌いたい!しゃべりたい!東北イタコ音声合成データベース制作プロジェクト」のクラウドファンディングが行われているのは、7月31日まで。コースによって、さまざまな返礼品も用意されているので、ぜひ、この研究の進展を願って支援してみてはいかがでしょうか?
※2020.07.15追記
2020.07.14に放送した「DTMステーションPlus!」から、第155回「Synthesizer Vで歌声合成の新時代を先取りしよう!」のプレトーク部分です。「読唇術を実現するためのデータベース作成!? 口の動きだけで言葉を認識し、違う声にする究極のバ美肉技術のための研究資金をクラウドファンディング中」から再生されます。ぜひご覧ください!
【関連情報】
東北イタコは歌いたい!東北イタコ歌唱音声合成データベース制作プロジェクト(クラウドファンディングページ)

コメント