IK Multimediaが開発したAIボーカル変換ソフト「ReSing」に、ついに日本語ボイスモデルが追加されました。本日5月19日にリリースされた「ReSing Voices Japanese Pack」では、男女あわせて8人のシンガーと2人のナレーターという計10種類のボイスモデルが収録されており、既存のReSingユーザーであれば追加購入することでこれらすべてを利用できるようになります。
筆者は昨年10月にReSingの記事を公開しており、そのときは英語モデルを中心に試していました。今回の日本語パックは、そのアップデートとして非常に注目度の高い新展開です。実際に手元で動かしてみたところ、歌わせたときのイントネーションや活舌が英語モデルとは段違いで自然であり、これは日本語コンテンツ制作者にとって見逃せないアップデートだと感じました。今回は人間の歌声での変換、歌声合成ソフトの出力を元にした変換、さらにはしゃべり声の変換という3つの実験を行い、各モデルの実力を確かめています。あわせて、オリジナルのボイスモデルを作成できる「ReSing Modeler」の概要、そしてDAWプラグインとして使う際のポイントも紹介します。ReSing Voices Japanese Packのメーカー希望小売価格は€99.99(税別)、国内ではbeatcloudにて¥16,990(税込)での販売となっています。さらに、2026年6月1日までに限り、発売記念セールとして20%オフの13,591円(税込)となるほか、ReSingや、RieSingに25種類のボイスモデルをセットにしたReSing MAXもセール価格となっています。
※2026.5.25追記
ReSing Voice Japanese PackはReSing/ReSingMAXを持っていなくても、無料のReSing Freeで使用することが可能です。
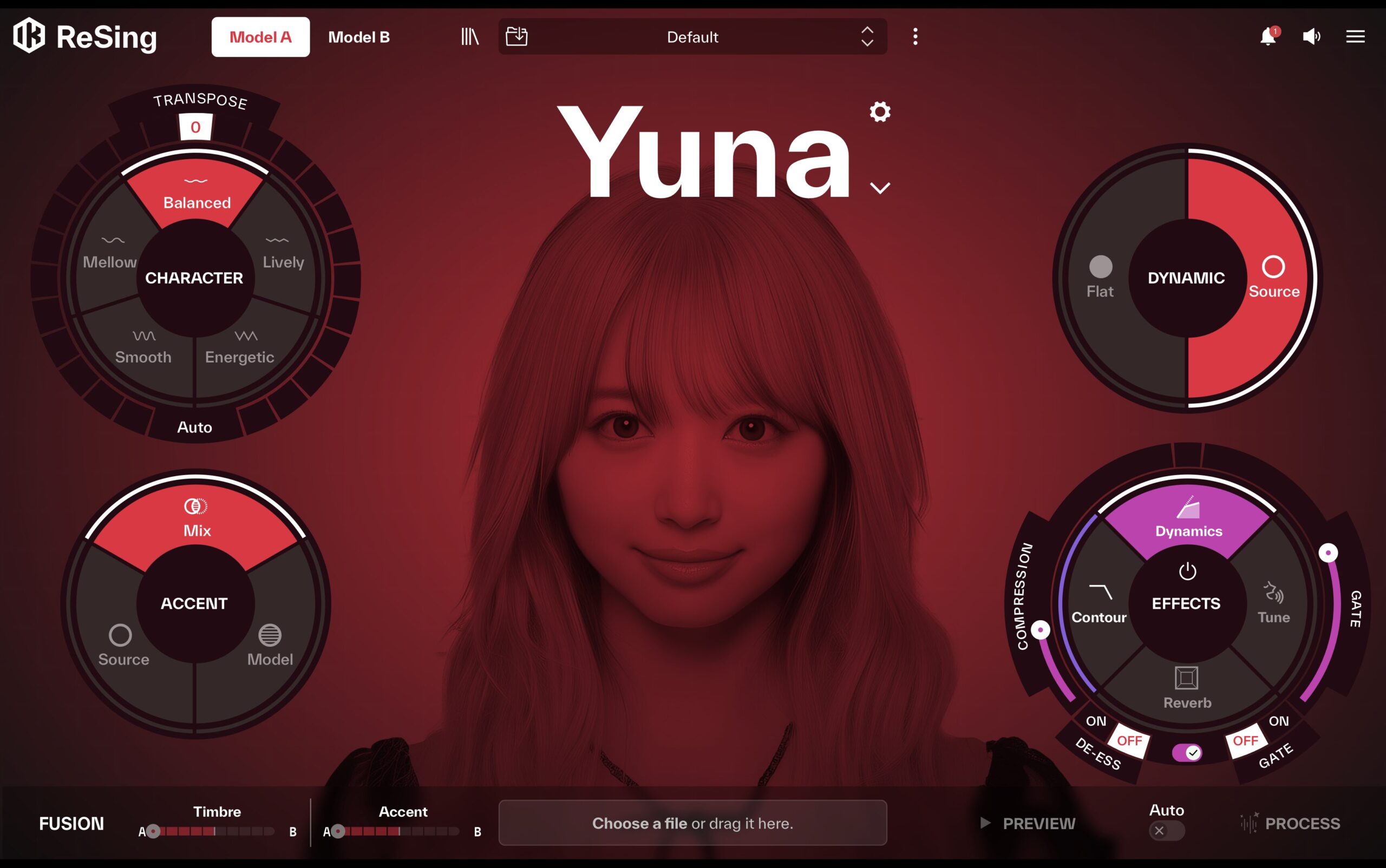
IK MultimediaからReSing Voices Japanese Packがリリース。日本語の歌声をスムーズに違う歌声に変換可能に
ReSingとはどんなソフトか
ReSingについて簡単に振り返っておきましょう。昨年10月の記事「ボーカルをまったく別の歌声にAIで変換。ユーザーがAIモデルの自作もできるIK Multimedia ReSing登場」でも詳しく解説していますが、ReSingはボーカルトラックの音色や発音の特性を、実在アーティストの歌唱データから生成された高品質なAIボイスモデルに置き換えることで、トラックのクオリティを向上させるソフトです。
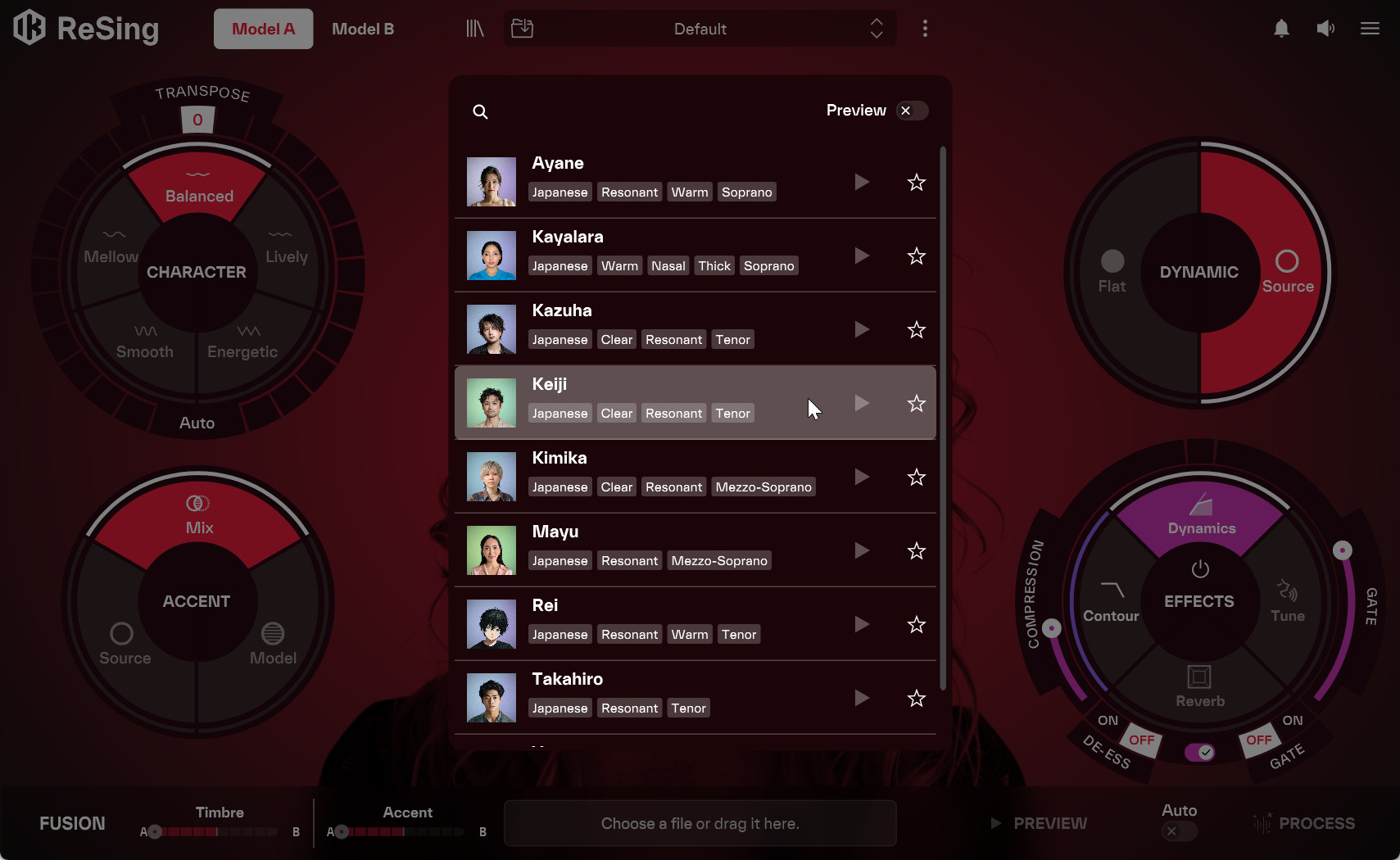
歌声を変換するAIボイスモデルを選択する
いわゆるリアルタイムのボイスチェンジャーとは異なり、「Process」ボタンを押すことでファイル全体をレンダリングする方式です。スタンドアロンのアプリとしても、VST/AU/ARA 2対応のDAWプラグインとしても動作します。処理はすべてローカル環境で完結し、クラウドへの接続やサブスクリプションは不要です。
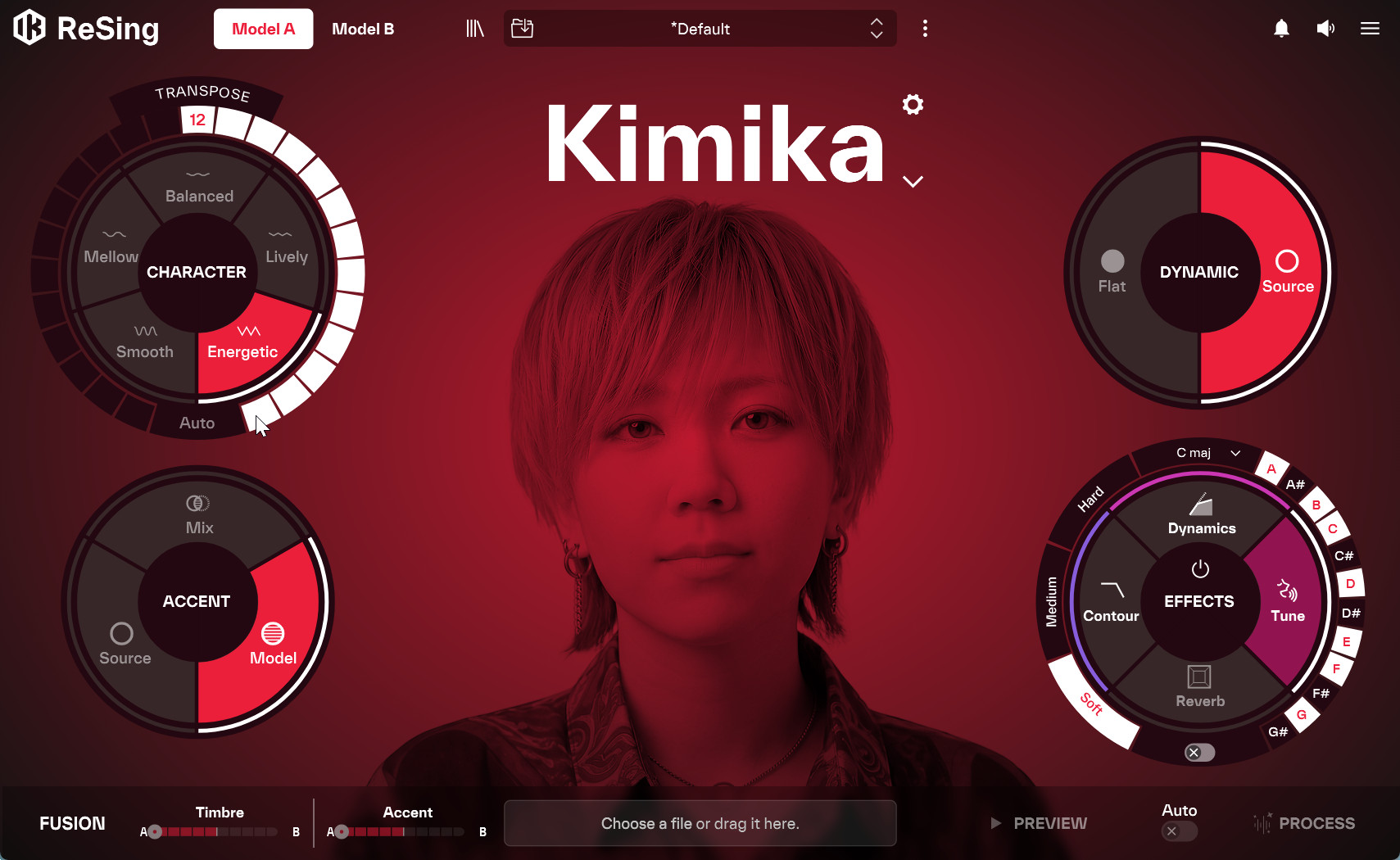
デフォルトの設定でOKだが、必要に応じてパラメータの調整も可能。男性ー女性間変換の場合はオクターブ調整が便利に使える
モデルごとに備わる「Character(キャラクター)」「Transpose(トランスポーズ)」「Accent(アクセント)」「Dynamic(ダイナミック)」といったパラメーター、さらに2つのモデルを混ぜ合わせてハイブリッドな声を作る「Fusion(フュージョン)」機能など、表現の幅を広げるための仕組みが充実しています。
10種類の日本語ボイスモデル、インストール方法と容量について
今回の「ReSing Voices Japanese Pack」には、女性シンガー4人・男性シンガー4人・女性ナレーター1人・男性ナレーター1人、計10種類のボイスモデルが収録されています。
| 写真 | 名前 | 性別 | 種別 | 声の特徴 |
|---|---|---|---|---|
 |
Yo | 男性 | シンガー | 明るく感情豊かなトーン。前に出る表現力とダイナミックなフレージングが魅力 |
 |
Kayalara | 女性 | シンガー | エアリーでブレス感があり、繊細さのなかに芯のある存在感のあるトーン |
 |
Kimika | 女性 | シンガー | 力強く明瞭で、正確にコントロールされた印象のトーン |
 |
Kazuha | 男性 | シンガー | クリーンでタイト、フォーカスの定まったモダンなトーン |
 |
Yuna | 女性 | シンガー | 明るくクリスタルのように澄み渡った若々しいトーン |
 |
Rei | 男性 | シンガー | 表現の幅が広く、バランスとレスポンスに優れた多彩なトーン |
 |
Ayane | 女性 | シンガー | クリアで輝きがあり、フォーカスの定まった純粋なトーン |
 |
Keiji | 男性 | シンガー | 成熟した落ち着きのある歌声で、豊かで安定感のあるトーン |
 |
Mayu | 女性 | ナレーター | バランスよく落ち着いた、安定感のある自然なトーン |
 |
Takahiro | 男性 | ナレーター | 生き生きとして明るく、表現力豊かなトーン |
これらのモデルはすべて、ReSingのために録音されたオリジナル音源をもとに生成されており、各シンガー・ナレーターとIK Multimediaとの間で正式な合意のもと、適切な報酬とともに制作されているとのことです。倫理的なAI活用という観点からも、透明性の高いアプローチが取られている点は注目に値します。
インストールはIK Product Managerを使って行います。パックを購入・ユーザー登録したのち、Product ManagerのSoundsタブからReSing関連の項目を開くと、各モデルが個別にインストールできる形で表示されます。
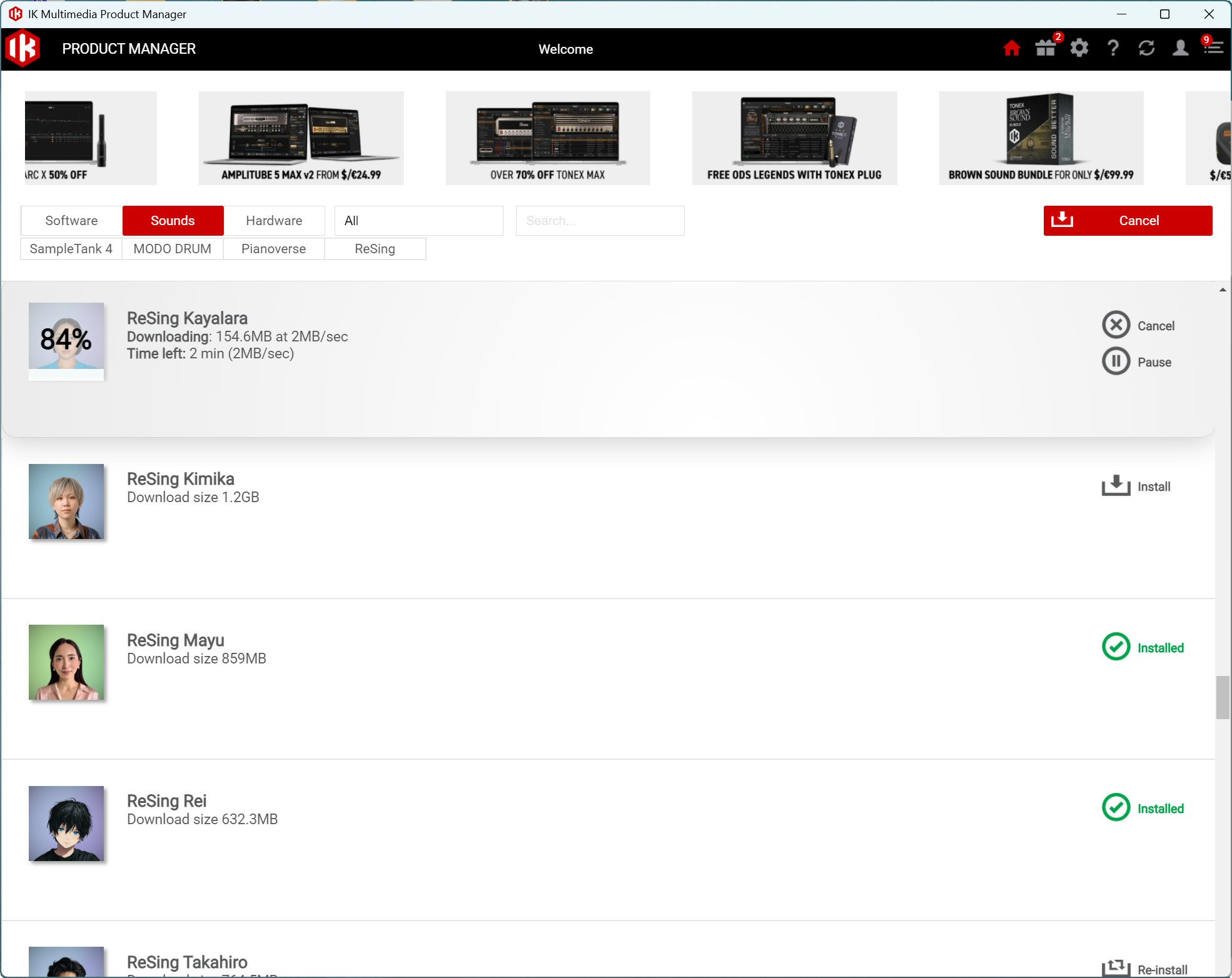
ReSingをインストール後、各ボイスモデルを1つずつインストールする必要がある
注意が必要なのは容量です。1モデルあたりおよそ1GB程度を見込んでおく必要があります(実際にはバラつきがあり、小さいものだと630MB程度、大きいものでは1.4GB程度)。10モデルをすべてインストールするとかなりの容量になるため、内蔵ドライブの空き容量が少ない場合は外部ドライブへのインストールも検討してください。「Settings」の「Models」タブでインストール先フォルダを変更でき、外部ドライブに保存した状態でも問題なく利用できます。
実験①「ハレのち☆ことり」を日本語モデルで歌わせてみた
まず最初に試したのは、前回記事でも題材にしたDTMステーションCreativeのアルバムの1曲で、多田彰文さん作詞・作曲、小岩井ことりさん歌唱の「ハレのち☆ことり」のボーカルトラックを元にして、今回のReSingの日本語モデルで歌わせるという実験です。使用したモデルはYuna、Ayane、Kayalara、Kazuha、Keijiの5つ。KazuhaとKeijiについてはReSingのTranspose設定で1オクターブ下げて変換しています。なお、このオクターブ設定以外はエフェクト等には一切手を加えておらず、基本的にはデフォルトの設定のままです。
前回記事では英語モデルに歌わせたのに対し、今回は日本語モデルということもあって、歌詞のイントネーションや子音の活舌が格段に自然になっています。英語モデルでは若干の違和感が残っていた部分が、日本語モデルではほぼ解消されており、リアルな歌声としてすっと聴けるレベルになっていると感じました。
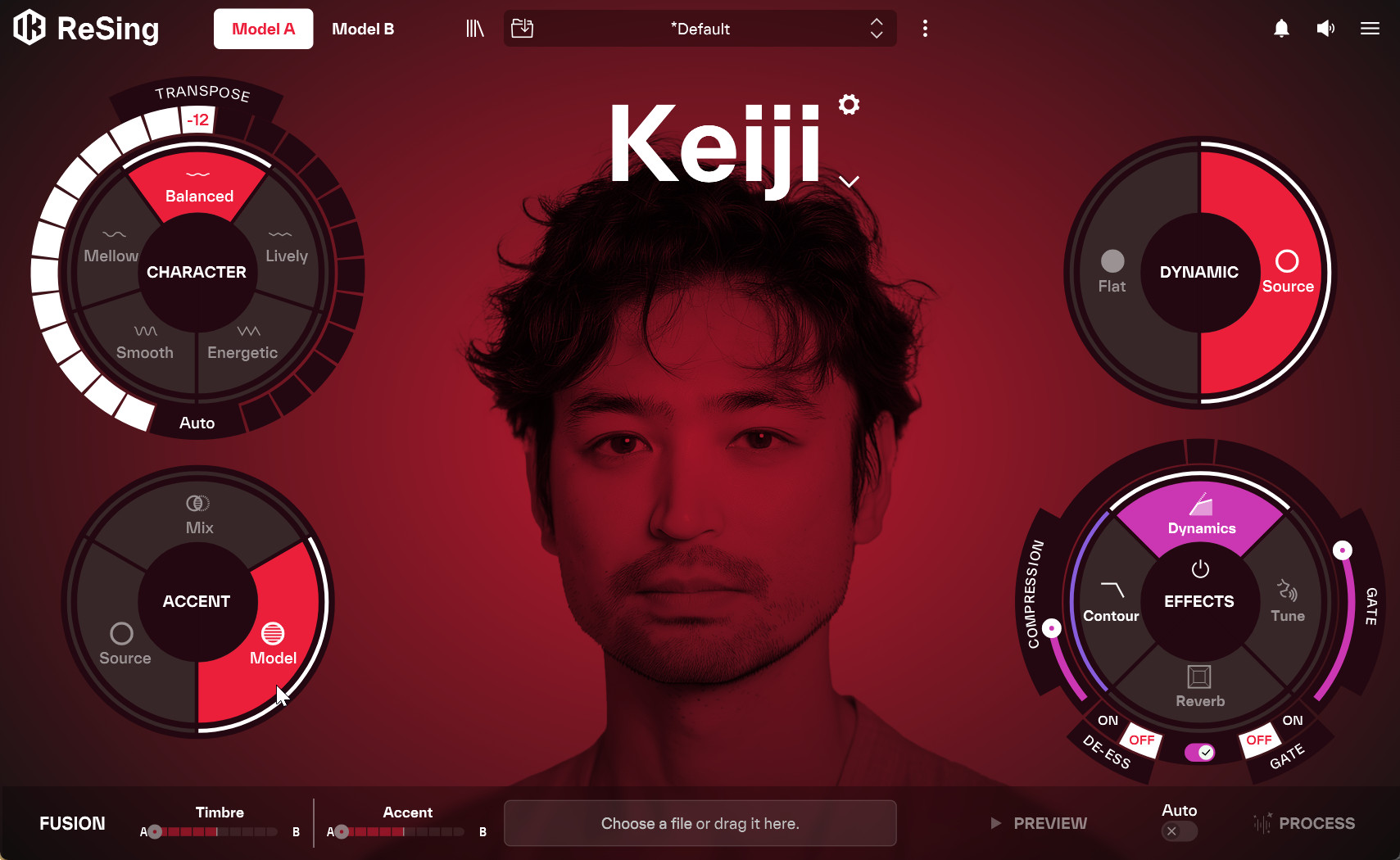
女性ー男性のボイス返還をする場合、ACCENETをModelにすると自然になるケースも多い
上記動画では「ACCENT(アクセント)」にて「Mix(変換前トラックとReSingボイス・モデル中間の発音)」を選んでいるため、男性ボイス・モデル変換時も女性(小岩井ことりさん)っぽく可愛い発音、歌い方になっていますが、違和感を感じる場合、「ACCENT」にて「Model(ボイス・モデル寄りの発音)」を選ぶこともできます。
実験②歌声合成(Synthesizer V 2 Mai 2)を元に変換するとどうなるか
2つ目の実験は、人間の歌声ではなく、歌声合成ソフトの出力をReSingに通してみるというものです。ここではSynthesizer V 2のMai 2を使って「ハレのち☆ことり」を歌わせたデータを入力音源として用意し、実験①と同じYuna、Ayane、Kayalara、Kazuha、Keijiの5モデルで変換しました。
結果は興味深いもので、人間の歌声を元にしたときよりもさらにクリアで、よりリアルな印象の出力が得られました。歌声合成ソフトのデータは音程の安定性が高く、ノイズも少ないため、ReSingのモデルが持つ音色の特徴がより明確に出やすいのかもしれません。歌声合成ソフトのボーカルをよりリアルな声に仕上げる用途としても、ReSingは非常に有効なツールになり得ると感じました。
実験③しゃべり声はどうなるか——ナレーターモデルとシンガーモデルの比較
3つ目は前回の記事ではおこなわなかった実験で、しゃべり声をReSingに通すというテストです。元音源にはVOICEPEAKのしゃべり声を使用しました。
今回の日本語パックではKayalara、Kazuha、Keiji、Kimika、Rei、Yo、Yuna、Ayaneの8人がシンガー、TakahiroとMayuの2人がナレーターという区分になっています。そこでまず、ナレーターとして設計されているMayuとTakahiroで変換を試みました。Takahiroについては通常のほかに1オクターブ低くしたバージョンも作成しています。また、シンガーモデルでしゃべり声を変換するとどうなるかも気になり、YunaとReiについても同様に実験してみました。
結果としては、ナレーターモデルのほうがよりクリアで落ち着いた声質になる印象でした。一方でシンガーモデルでも十分に変換は可能で、声質の違いを楽しむ使い方ができそうです。また、Takahiroを1オクターブ低くしたバージョンは、もとのナレーターとはまたニュアンスが異なり、落ち着いた低音ボイスとして活用できるものでした。
オリジナルのボイスモデルを作れる「ReSing Modeler」
ReSing Voices Japanese Packには、ユーザー自身がオリジナルのボイスモデルを作成できるスタンドアローンツール「ReSing Modeler」もバンドルされています。今回のアップデート(v1.0.6)では、このReSing Modelerに日本語オプションが追加されています。パックをユーザー登録することでLanguageメニューに「Japanese」が追加され、より自然な発音の日本語モデルを作成できるようになります。
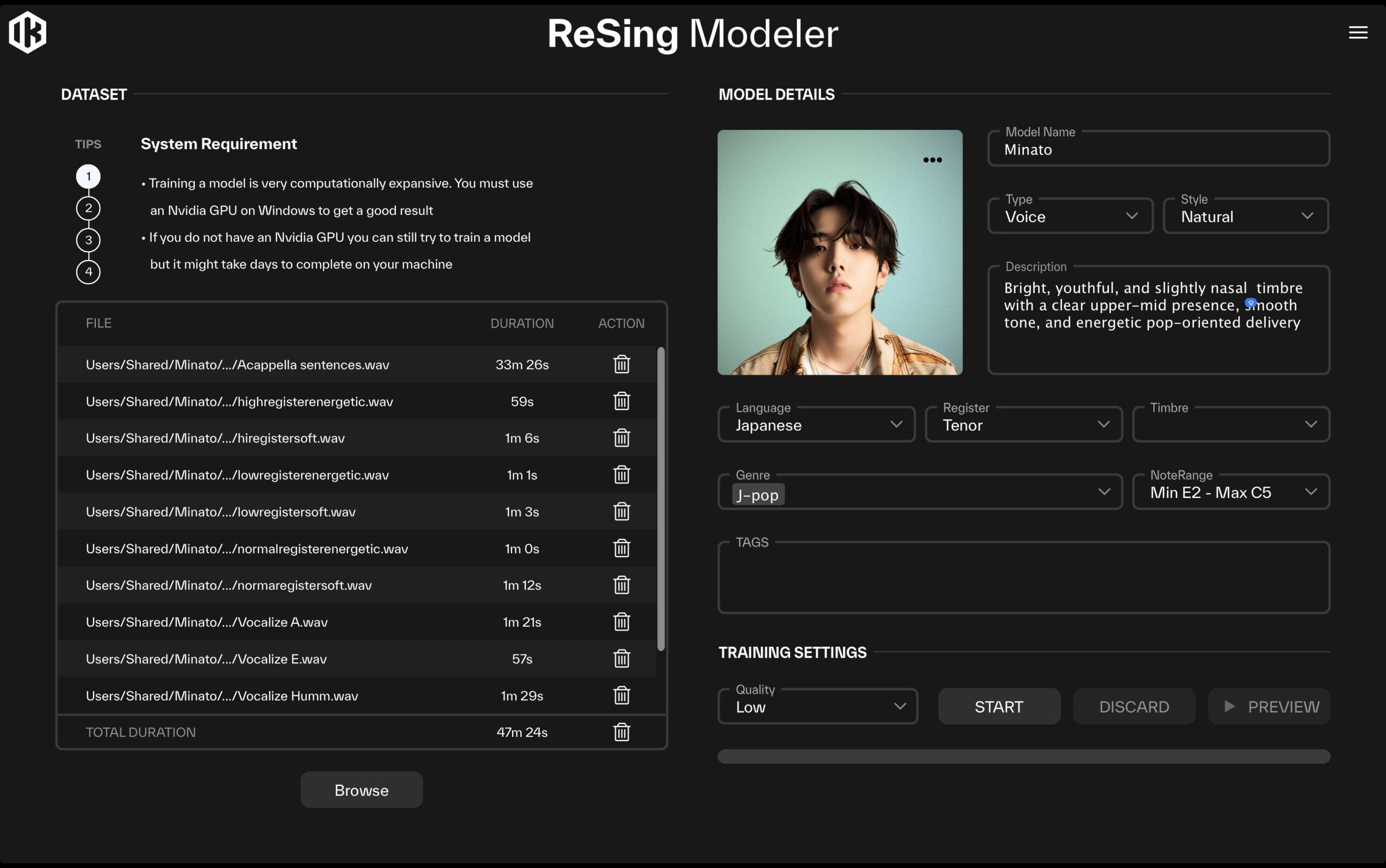
ReSing Modelerを使うことで、自分の歌声などを学習させてAIモデルを作ることが可能
マニュアルによると、学習データには以下のような素材が推奨されています。
・サンプルレートは48kHz
・ファイル形式はWAVまたはFLAC(非圧縮)
・ハモリや重ね録りなし、ノイズのない単独歌唱のみ
理想的なアプローチとしては、6曲を異なるキーで歌った素材を用意し、音域全体と多様な音素をカバーするのがよいとされています。収録時間の目安は15分以上です。
注意しておきたいのが処理環境です。NVIDIA製GPUとCUDA環境が強く推奨されており、これが整った状態ではトレーニングが数時間程度で完了します。ただしCPUのみの環境でもトレーニング自体は可能で、その場合は数日かかることもあるとのこと。ハイスペックなWindowsマシンを用意できるかどうかが、実用性を左右するポイントになりそうです。
また、コミュニティで広く使われているRVC v2形式のモデルをReSingにインポートする機能(ReSing Freeだと1つ、ReSingは10個、ReSing Maxなら無制限)もあります。.pthと.indexファイルを含むzipファイルを用意すれば読み込み可能で、自分で用意したモデルやサードパーティのモデルを活用したい場合にも対応しています。
プラグインとして使う——VST/AUとARA 2の違い
前回の記事ではあまり触れませんでしたが、ReSingはプラグインエフェクトとしてDAWに挿して使うことができます。ただし、あらかじめ明確にしておきたいのは、ReSingはリアルタイム・ボイスチェンジャーではないという点です。入力した音声をリアルタイムで変換するのではなく、「Process」ボタンを押すことでファイル全体をレンダリングする方式です。
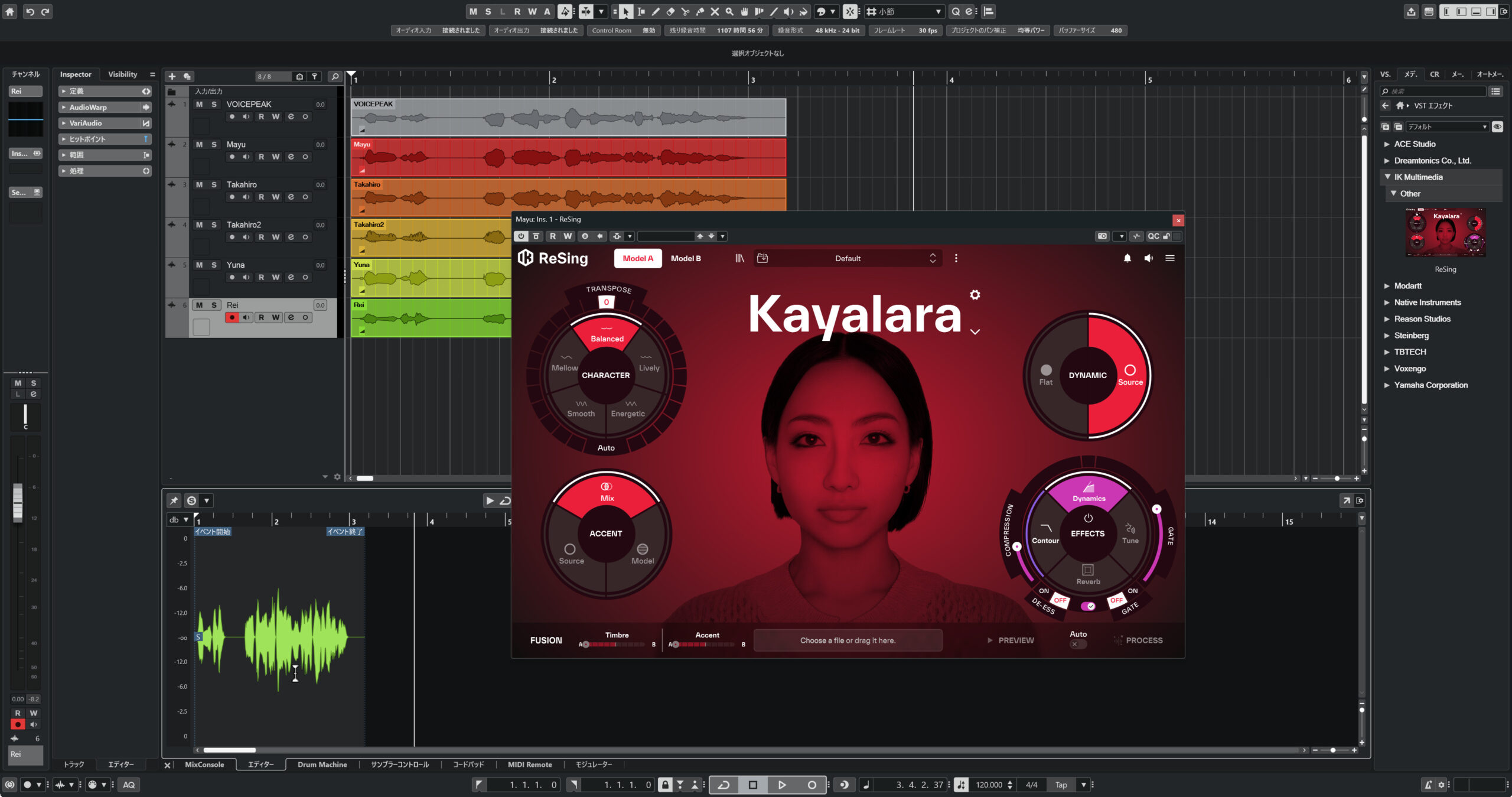
VST/AU対応のDAWに挿してスタンダードプラグインモードで使う場合は、基本的にスタンドアローン版と操作の流れはあまり変わりません。プラグインのウィンドウ内でファイルを読み込み、Processを実行して処理済みファイルをDAWのトラックにドラッグする、という手順になります。
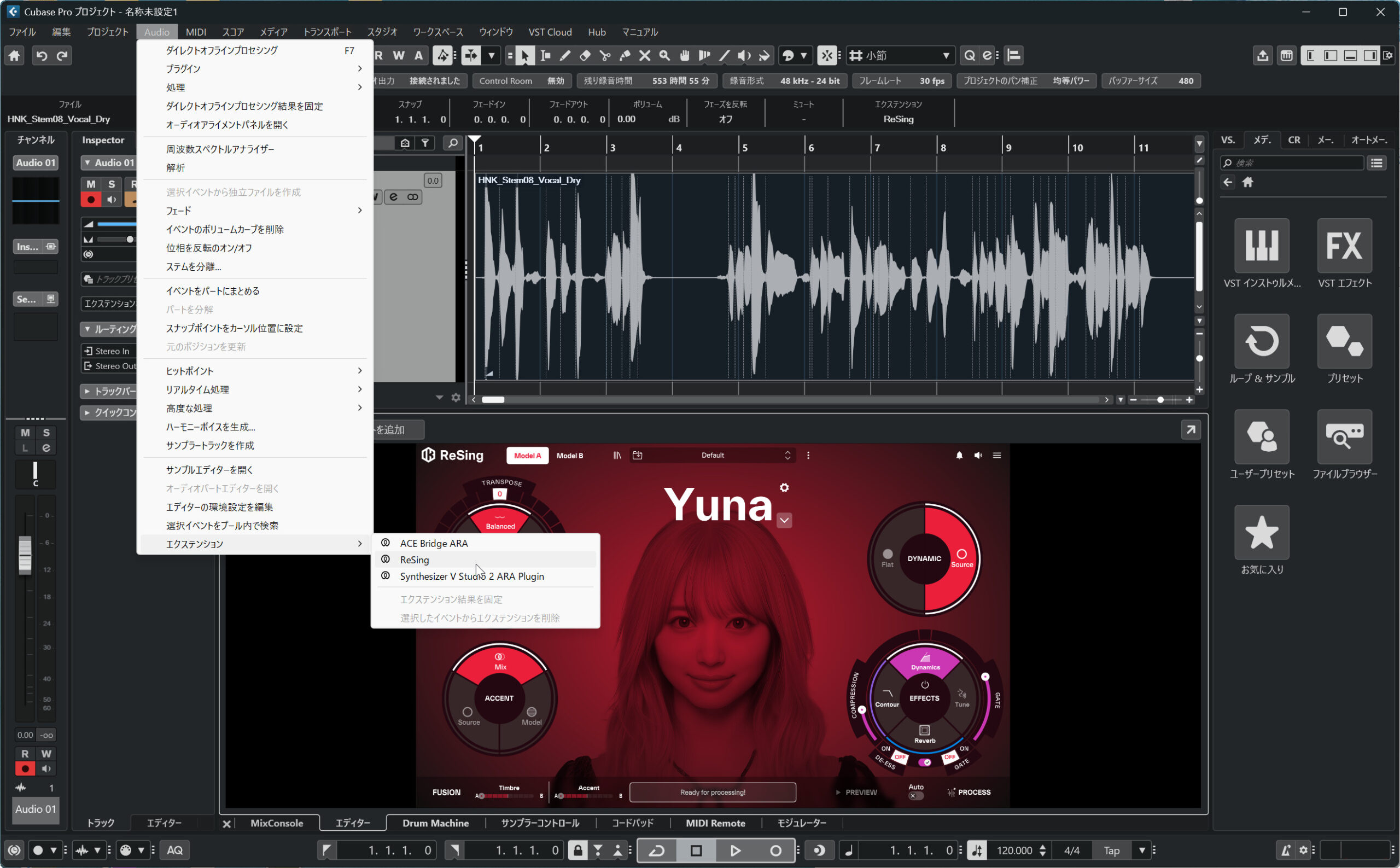
DAWにARA 2でReSingを組み込むことで、よりDAWと一体化させて便利に使うことができる
一方、ARA 2(Audio Random Access)に対応したDAW、たとえばReaperやCubaseでARAモードを有効にして使うと、ワークフローが大きく変わります。DAWのタイムライン上で対象のオーディオクリップを選択してProcessを実行するだけで処理が完了し、DAWとReSingの間でファイルをドラッグして往復する手間がなくなります。処理後はすぐにDAW上で再生確認でき、修正・再処理もスピーディです。テイク管理もしやすく、MelodyneのようなARAプラグインと似た感覚で扱えます。ARA 2対応DAWを使っているなら、このモードを積極的に活用することをおすすめします。
歌声合成とは違った活用ができるソフト
以上、ReSingの日本語対応のボイスモデルについて紹介してみましたが、いかがだったでしょうか?打ち込み不要で、自分の歌声をもとに、男性ボーカルでも女性ボーカルでも、さまざまな歌声に変換できるという意味では、VOCALOIDやSynthesizer Vといった歌声合成ソフトとはまた違った活用がいろいろできるのではないかと思います。デモ曲を作るといった用途にはもちろん、メインボーカルからコーラスパートを生成するなど、さまざまな用途も考えられそうですね。
なおReSing Voices Japanese PackはIK Multimediaのオンラインストアおよび国内正規代理店のbeatcloudにて購入できます。

ReSing Voices Japanese Packはbeatcloudで発売中
また、ReSingのアップデート(v1.0.6)はすべての登録ユーザーにIK Product Managerから無料で提供されます。ただし、ReSing Modelerで日本語モデルを作成する機能(LanguageメニューのJapanese選択)は、このパックをユーザー登録することで初めてアンロックされる形になっています。
ぜひ、この機会にReSingおよびReSing Voices Japanese Packを入手してみてはいかがですか?
【関連情報】
ReSing製品情報
ReSing製品情報(IK Multimedia)
ReSing Voices Japanese Pack製品情報
ReSing Voices Japanese Packリリース記念セール情報
【価格チェック&購入】
◎beatcloud ⇒ ReSing , ReSing MAX
◎beatcloud ⇒ ReSing Voices Japanese Pack



コメント