音楽制作におけるクワイヤー(合唱パート)の作り方の歴史が大きく動きました。ほとんどのユーザーが気づかないまま進行していたSynthesizer Vに関する”巨大な計画”が、1月15日に正式版、Synthesizer V Studio 2.2.0として公開されたのです。これにより最大16人の合唱をAIが自然に生成できるようになると同時に、日本語・英語・中国語の3つの新コーラス音源が発売されたのです。昔からシンセサイザ/サンプラーでクワイヤー音源というものはありましたが、それとは比較にならないレベルです。また歌声合成の世界でもこれまでも複数の歌声DBを並べて1つのトラックから合唱を生成する合唱機能を装備したソフトはありましたが、今回のSynthesizer Vのアプローチはそれとは根本的に異なります。1つの音源から最大16人の合唱を生成し、各声部のピッチやタイミングに自然な揺らぎを持たせ、さらに立体的な音場まで制御できる——これは歌声合成における合唱表現の新たな地平を切り開くものと言えるでしょう。
また今回の2.2.0では新スケールモード、ルームシミュレーター、EQ/コンプレッサー/リバーブを備えたエフェクトパネル、さらにレンダリングキャッシュやMusicXMLインポートなど、制作ワークフローを一変させる機能も多数搭載されている点も重要なポイント。今回のアップデートは単なる機能追加ではなく、AI合唱という新しい制作領域を切り開く”革命”と言っていい大きな進化となっているのです。この前代未聞のアップデートについて、開発者でありDreamtonicsそしてAHSの代表取締役でもある Kanru Hua(カンル・フア)さんへの独占インタビューを交え、その全貌に迫っていきましょう。
Synthesizer V Studio 2.2.0が登場し、合唱機能が搭載された
何が”史上最大”なのか——2.2.0アップデートの全貌
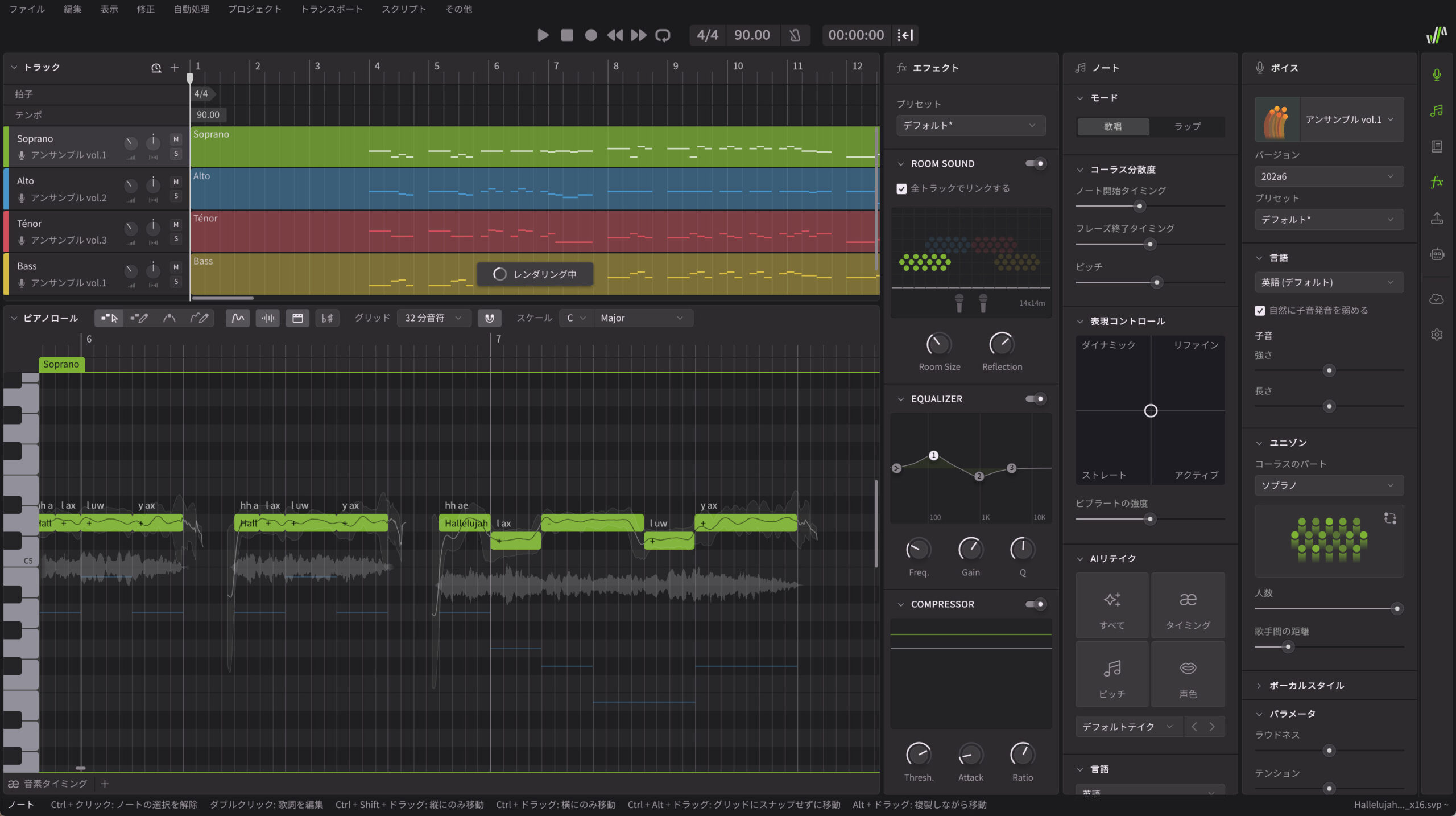
まずは以下のデモ動画をご覧になってみてください。これは、筆者がフリーで配布されていたヘンデルの《メサイア》の「ハレルヤ」合唱曲をmusicXML形式でダウンロードして、Synthesizer V 2.2.0のベータ版に単純に読み込ませて再生してみたものです。
いかがですか?こんなことが簡単にできるようになると、音楽制作におけるクワイヤーのパートづくりが抜本的に変わりそうですよね。今回の2.2.0アップデートが”史上最大”と呼ばれる理由は、機能の数ではなく、その”質的転換”にあります。歌声合成における合唱機能自体は、例えばACE Studioが複数の歌声DBを並べて1つのトラックから合唱を生成する「合唱モード」を既に実装していました。しかし、今回のSynthesizer Vのアプローチは、それとはまったく異なる次元のものなのです。
これまでのSynthesizer Vは、どんなに優れた歌声を生み出せても、基本的には「ソロ歌手」を想定したものでした。トラックを重ねることで疑似的な合唱を作ることはできましたが、それはあくまで「同じ人が何度も歌っている」状態でしかありませんでした。
しかし2.2.0では、1つの音源から最大16人の合唱を自然に生成できる機能が実装されました。これは単なるダブリング機能ではありません。Synthesizer Vのユニークな機能であったAIリテイクの技術を活用しながら各声部のピッチやタイミングに微妙な揺らぎを持たせ、さらに新たに搭載されたルームシミュレーターと連動して各パートの立体的な配置まで制御できるのです。つまり、従来の歌声合成における合唱表現を大きく超える、「本物の合唱団」のような表現をAIで制作できる時代が到来したということなのです。
合唱制作を支えるために追加された基盤機能
そしてこの合唱制作を支えるために、スケールモード、エフェクトパネル、レンダリングキャッシュ、MusicXMLインポートといった基盤機能も同時に追加されています。これらすべてが同時に、しかも”突然”公開されたことによる衝撃は計り知れません。実はこのプロジェクト、2年間にわたって秘密裏に進められてきたものなのです。
さらに今回のリリースに合わせて、
Choir Voices #2(アンサンブルシリーズ vol.2):中国語
Choir Voices #3(アンサンブルシリーズ vol.3):日本語
という3つの新コーラス音源も同時発売されます。それぞれ男女混合の16人分の声が収録されているのがポイント。従来からの歌声データベースを使っても合唱生成は可能ですが、この新しいアンサンブルシリーズを利用すると、ホンモノの合唱団を簡単に実現できるのです。日本語と中国語の歌声データベースはクラシカルな合唱、英語はゴスペル寄りのスタイルという、明確な個性を持っています。
デモ動画の合唱の制作に関する補足
上記の動画は、MuseScoreの楽譜データベースからフリーのものをmusicXML形式で読み込ませたものです。
読み込むとソプラノ、アルト、テノール、バスの4つのパートに分かれるので、3種類のアンサンブルシリーズを適当に割り当ててみました。さらに各トラックそれぞれ4人が歌っている形に設定するとともに、ルームシミュレーターを用いて左からソプラノ、アルト、テノール、バスと弧を描くような感じで4人ずつ、計16人を配置した上で、再生したものです。
また合唱なので、新たに搭載されたリバーブを軽く掛けたうえでレンダリングしています。
以下では、開発者であるDreamtonics・AHS代表のKanru Huaさんへのインタビューをもとに、この革命的なアップデートの詳細を深掘りしていきます。
Synthesizer V開発者、Kanru Huaさんインタビュー
2年間秘密裏に進められた合唱プロジェクト
——今回の合唱機能、まさに”突然の発表”という印象ですが、いつ頃から準備されていたのでしょうか。
Kanru:実は2年くらい前から準備していたんです。合唱というのは研究開発の部分も含めると、結構大きいプロジェクトであり、収録にも大きなパワーがかかったので、時間を要しました。2年前に最初の技術検証を行って、そこから開発を進めていったのです。

インタビューに答えてくれたSynthesizer Vの開発者でDreamtonics、AHSの代表取締役であるカンル・フアさん
——2年間も水面下で動いていたとは驚きです。なぜ合唱機能を開発しようと思ったのでしょうか。
Kanru:ここ数年でユーザー数が増えてきて、使い方もさまざまになってきたんです。そのうち半分がプラグインのみを使って、半分がスタンドアロンのみを使っている。例えば音楽学校で授業するためだけに使う先生もいらっしゃいます。そういう方は、電子音楽制作ではなく、作曲のハーモニーやコードを教えるためにSynthesizer Vを立ち上げてコードを置いたりしているんですね。そういった教育用途や、作曲家の方々にも使いやすいものにしたいと考えました。
そしてもちろん、合唱というジャンル自体が音楽として非常に重要なものですから、これをAIで実現できたら素晴らしいと思ったんです。
16人合唱を実現する技術的な仕組み
——今回の合唱機能は、最大16人まで増やせるとのことですが、内部的にはどのような処理をしているのでしょうか。
Kanru:まず、今までの声、例えばNatalieやMAIなどのソロのボーカルでも利用できるように、ボイスパネルに「ユニゾン」という機能を追加しました。このスライダーをデフォルトの1から2、3と増やしていくと、最大16人まで増やせるようになります。
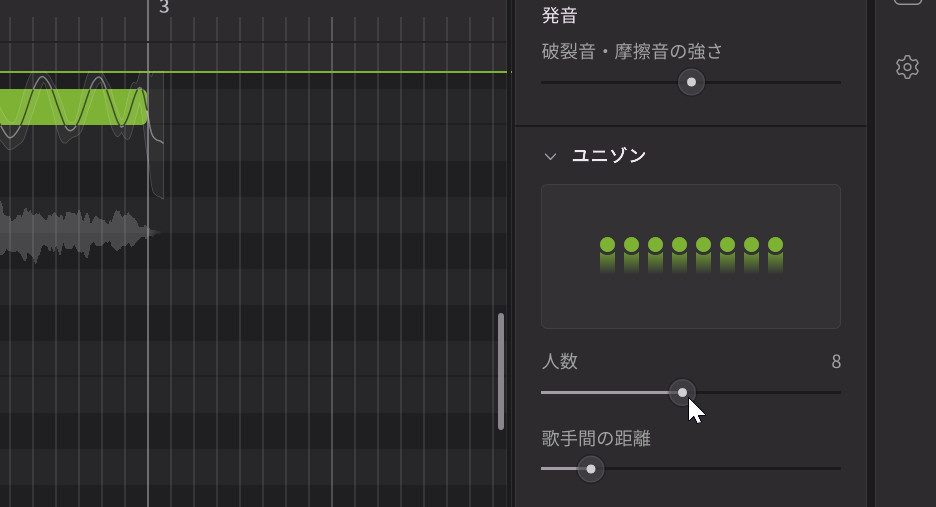
ユニゾン機能により1つのトラックで歌う人数を1~16の範囲で指定できるようになった
人数を2にすると、ピッチカーブが3つのカーブになるんです。真ん中が平均で、上と下が最大値と最小値。ピッチとタイミングが少しずれるようになっています。タイミングはあまりずれないようにしていますが、ピッチは適度に揺らぎます。内部的にはAIリテイクをやっているんですね。また最大16人いる歌手間の距離の設定も0.50~2.00mの範囲で5cm刻みで設定できるようになっており、歌声の空間の広さが変わってきます。
——16人まで増やすと、レンダリングも重くなりそうですね。
Kanru:そうなんです。16人にすると16回レンダリングされるので、当然レンダリングが遅くなります。その分、今回追加したレンダリングキャッシュ機能が効いてくるんです。
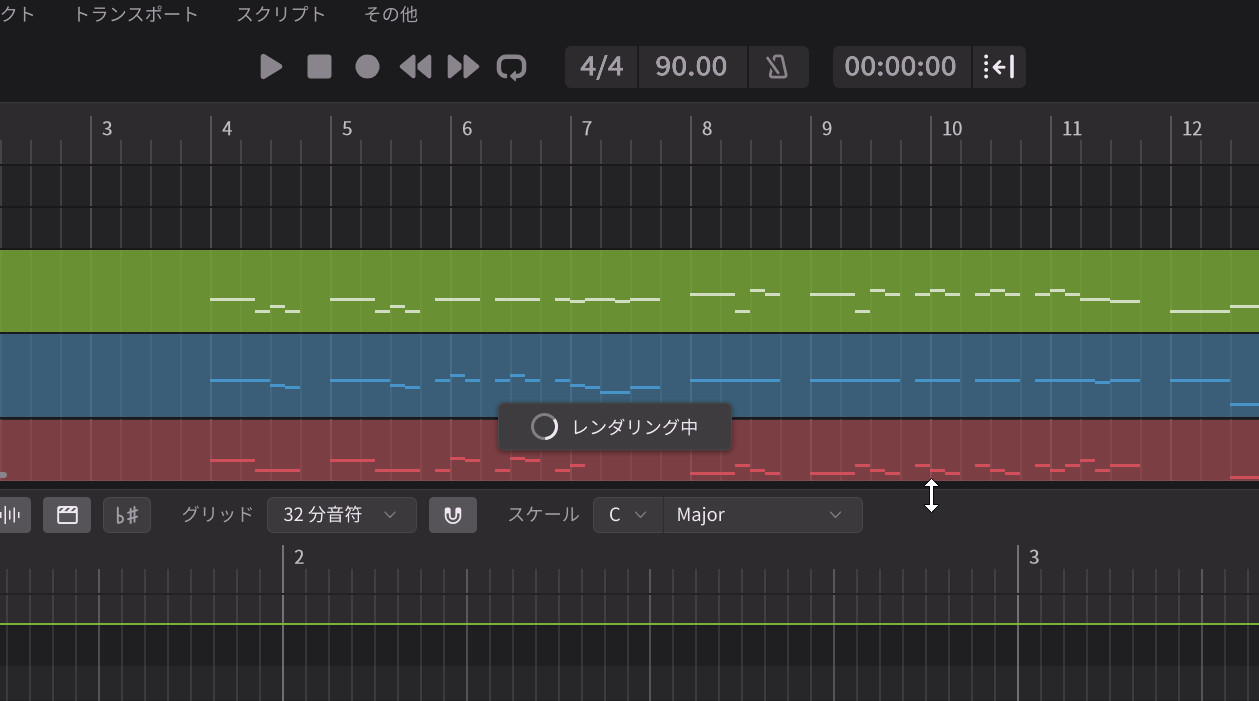
合唱機能を使うとその分レンダリング時間はかかるが一度レンダリングした結果はキャッシュされ、効率よく変換できるようになっている
さらに、ルームシミュレーターと連動して、16人それぞれの位置を変えることができます。四角い部屋の中で、各パートをどこに配置するかを視覚的に設定できるようになっています。
3つのコーラス音源——日本語・英語・中国語の違い
——今回、3つのコーラス音源が発売されるとのことですが、それぞれどのような特徴があるのでしょうか。
Kanru:英語の歌手16人分を収録して1つのライブラリとした「Choir Voices #1(アンサンブルシリーズ vol.1)」、中国語の歌手16人分の「Choir Voices #2(アンサンブルシリーズ vol.2)」、そして日本語の歌手16人分の「Choir Voices #3(アンサンブルシリーズ vol.3)」、という3つの歌声データベース、全部で48人の声があるんです。
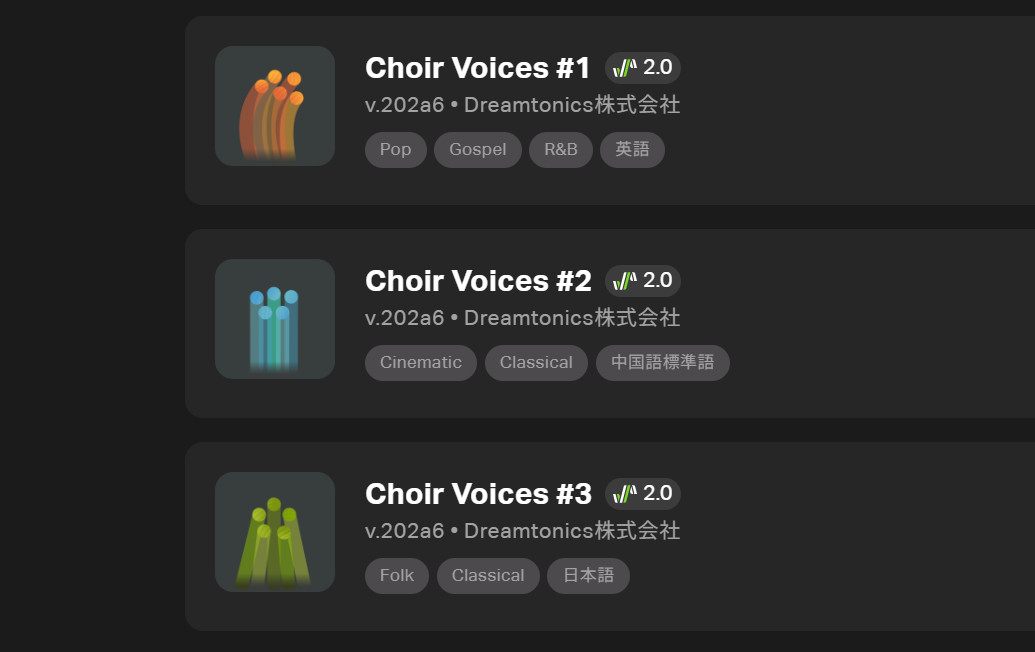
3種類の合唱用歌声データベースが発売された
——48人分の声ですか。それは膨大ですね。
Kanru:はい。Dreamtonicsで過去最大のライブラリになります。それぞれのライブラリには、ソプラノ、テノール、アルト、バスの4人組が収録されています。そして音を出すときに、ピッチや声色を少し調整して、8人や16人の歌声として使えるようになっています。
——スタイルにも違いがあるのでしょうか。
Kanru:日本語と中国語はどちらかというとクラシカルな合唱に近いんです。オペラ式の合唱ですね。一方、英語はゴスペルの方向性なんです。ゴスペルの声は明るくて、トップとバーが得意な感じになっています。

同じアルトでも、中国語のアルトと日本語のアルトでは声質が違います。どの言語であっても、英語、中国語、日本語で歌わせることが可能であり、それぞれ異なる個性を持っているので、全部を揃えていただいた方がいろいろなジャンルを歌えるようになりますね。
前代未聞の収録方法——4人同時録音とクロストーク除去技術
——収録はどのように行われたのでしょうか。
Kanru:日本語版は当社のスタジオで収録しました。一番最初は技術検証として、オフィスの中で試しに4本のマイクを立てて、それぞれ一人ずつマイクの後ろに立って歌ってもらったんです。これをオーディオインターフェイスを介して4つのトラックに録音しました。全員同時に、同じ部屋で同じタイミングで歌ってもらったんです。

マイクのセッティングなど、いろいろ工夫しながら合唱のレコーディングを行った
——一人ずつ別々に録音したのではなく、4人同時に録音したんですか?
Kanru:そうなんです。本物の合唱を録りたかったんで、このようにしました。でも、データを確認したら、やはり指向性の強いマイクを使っていても音が漏れて、横にいる人の歌声が入ってしまうんですね。クロストークが発生してしまう。そうなると、ソロの音源として学習もできなくなってしまいます。

そこで、その漏れを完全に消す技術を開発しました。空間オーディオをキャンセリングする技術です。この技術によって、4人同時に録音していても、完全にソロでスタジオで録ったように聞こえる音になるんです。
——それは画期的ですね。なぜそこまでして同時録音にこだわったのでしょうか。
Kanru:一人ずつ別々にスタジオで収録することもできますが、一緒に歌うときの音質とテクニックは、同じ人だとしてもスタジオで一人で録ったものとは違うんです。

クロストークキャンセリングの技術について解説するカンルさん
極端な言い方をすると、一緒に歌うときにみんないい感じにズレになるんですね。歌っている際、他の人の声を聴きてフィードバックする。だから合唱としてはいいアンサンブルにはなるけれど、個々の歌声が正確なピッチにならないというか、そういう心理的な効果が出ていると思うんです。そのため、収録した一人ひとりの声をソロで聴くとちょっと不安定で、アマチュアっぽく聴こえてしまいます。ところが、これを一緒にしたら、とてもリッチな合唱になってくるんですね。これをまったく別々に収録して合わせても、こうはならないんですよ。
——なるほど。つまり、合唱に最適化された声なんですね。
Kanru:そうです。明らかにピッチがずれるところは修正しているので、そんなに変なことはないんですけど、今まで出しているソロ音源に比べると、やはりソロにはそんなに向いていません。ソロとして使うときは、リードシンガーというより、バッキングボーカルに近いかもしれません。でも、それを合唱にするとすごく良くなるんです。
合唱制作を支える基盤機能
——今回、合唱機能以外にもさまざまな機能が追加されていますね。
Kanru:はい。まずスケールモードを追加しました。ユーザーからずっと要望があったんですが、スケールを選ぶとピアノロール上に色が表示されて、どの音を使えばいいかのガイドになります。音を入れられなくなるわけではなく、視覚的なガイドです。合唱で複数のパートを作るときに、これがあると便利なんです。

スケールの設定ができるようになった
それから、エフェクトパネルも追加しました。EQ、コンプレッサー、リバーブ、そしてルームシミュレーターです。これはあくまでプレビューのためのエフェクトで、外部のプラグインには及びませんが、スタンドアロンで使っているユーザーの方にとっては、聴きやすくするための便利なツールになります。もちろんレンダリング時にエフェクトを反映したままにすること
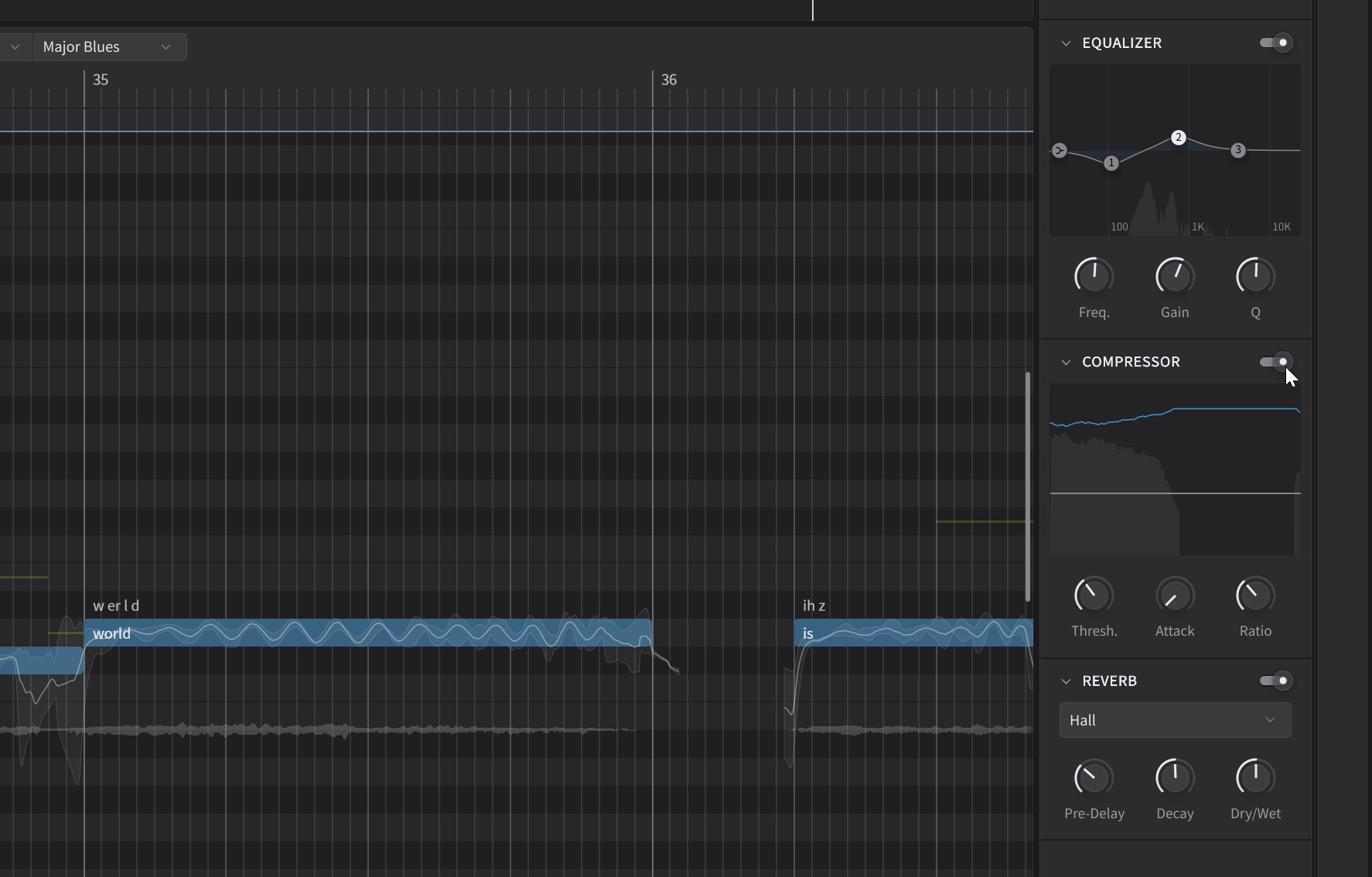
エフェクト機能が搭載された
——ルームシミュレーターというのは。
Kanru:部屋のサイズとリフレクションゲインを調整できて、音源の位置をずらすことができます。いわゆるPANではなく、奥行きも含めた形で、立体的に音源を配置することが可能です。また合唱させる場合、先ほどのとおり歌手間の距離も設定できるので、その距離幅を持った状態で、配置することが可能です。これはオーディオエンジンではなくエディタに組み込んでいるので、外部のプラグインよりはタイトになっています。
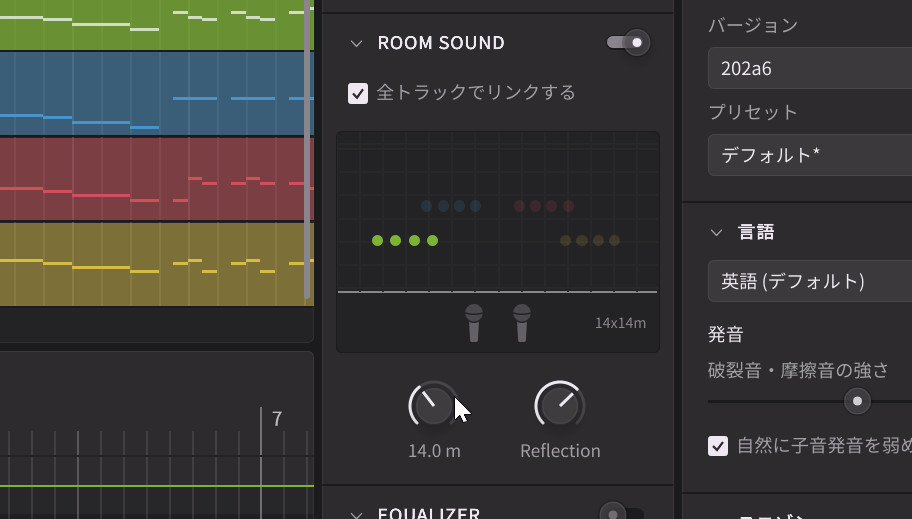
ルームシミュレータ機能が搭載され、立体的に歌声を配置できるようにあった
——そして、先ほど少し出ていた、レンダリングキャッシュ機能についても教えてください。
Kanru:今まで大きいプロジェクトを開くとき、前にセーブした時点ではレンダリングが終わっているのに、それを全部なしにしてゼロからやり直すことになっていたんです。これからは、一度レンダリングしたものをディスクに保存して、もう一度開いたときにそれを使うことにしました。
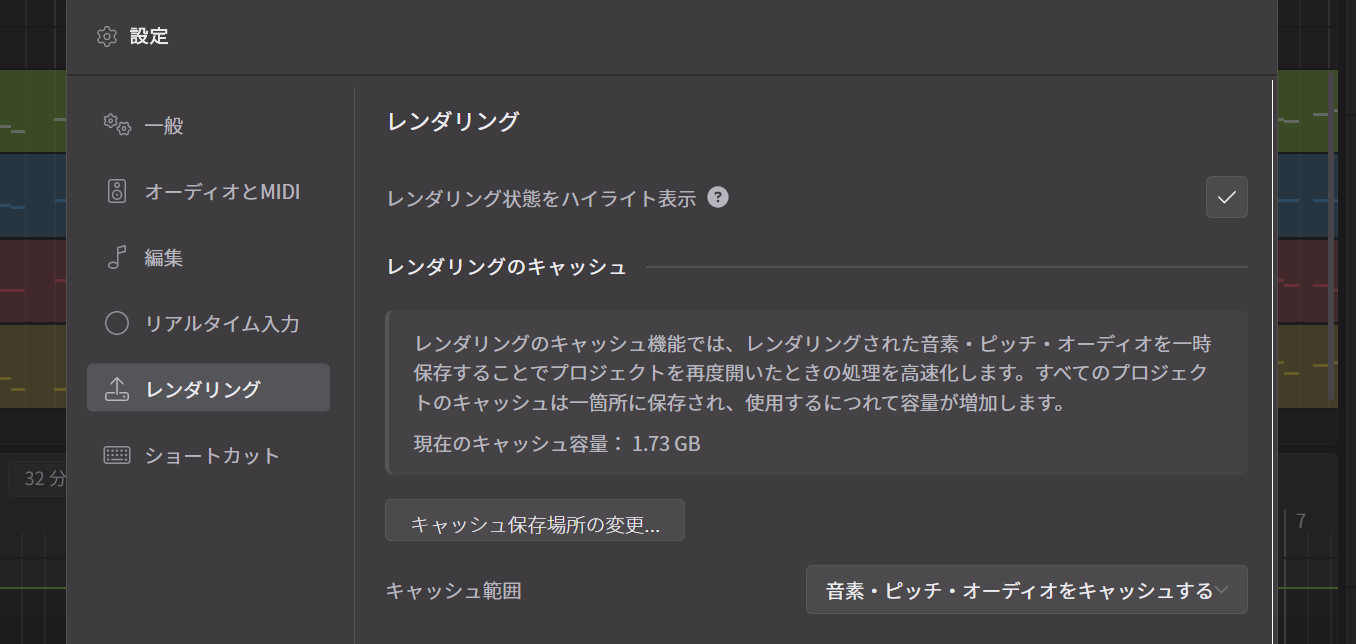
レンダリングキャッシュ機能も搭載
また、同じセッションの中でも、レンダリングしたものをすぐにディスクに保存するので、何ギガものデータをメモリに持つことがなくなります。16人の合唱など、重いプロジェクトには特に効果的です。
MusicXMLインポート機能で合唱制作が劇的に簡単に
——今回のバージョンアップでMusicXMLインポート機能も追加されたそうですね。
Kanru:はい。例えばMuseScoreやDoricoなどで作成した楽譜を、MusicXMLとしてインポートできるようになりました。今まではMIDIでしかできなかったんですが、MusicXMLの方がロスが少ないんです。歌詞も含めてインポートできます。
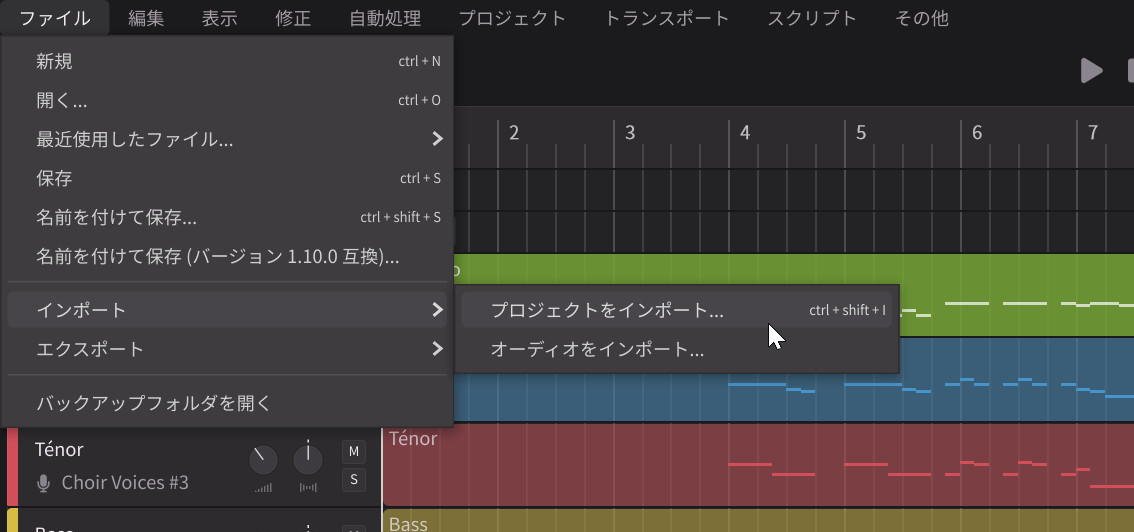
ついにMusicXMLのインポート機能を装備した
——実際にどのくらい実用的なのでしょうか。
Kanru:デモをお見せしましょう。これは400年前にできたバロック音楽なんですが、ネットで見つけたMusicXMLデータをドラッグ&ドロップでインポートするだけで、こうなります。
(デモを見せながら)パートを選んで、人数を設定して、ルームサウンドやリバーブを調整して、各パートをパンニングして……。歌詞の認識できない部分は多少調整する必要がありますが、基本的にはこれだけで合唱が完成します。
——素晴らしいですね。ただ、Kanruさんがこれをイギリスのコーラスの作曲家に見せたら、何か言われたとか。
Kanru:まだ開発途中のときに見せたところ「もし私の合唱団がこういう風な歌い方をしたら、あまり嬉しくない」と言われましたね(笑)。というのも、その時点ではあまりにもタイミングが揃いすぎているからです。
——なるほど。人間の合唱はもう少し揺らぎがあるということですね。
Kanru:そうなんです。そこで「コーラス分散度」という機能を用意しました。ノートパネルに「ノート開始タイミング」と「フレーズ終了タイミング」それに「ピッチ」というパラメータがあります。これは合唱の音源を選んだときだけ表示されるんです。

コーラス分散度という3つのパラメータが装備された
これにより時間軸と音程軸において、どのぐらい人と違うか、そのばらつき度合やピッチをコントロールできるようにしたのです。これらを調整することで、より自然な合唱のタイミングにすることができるんです。
——細かいところまで配慮されているんですね。
AI合唱が切り開く新しい音楽制作の未来
——最後に、今回のアップデートが音楽制作に与える影響について、どのようにお考えですか。
Kanru:今まで合唱というのは、実際に人を集めないとできないものでした。もちろん、プロのスタジオでライブラリを使うこともできますが、それでも制作のハードルは高かったんです。
今回のアップデートによって、合唱制作を”誰でもできるもの”にしたいと考えています。作曲家の方が頭の中にあるイメージをすぐに形にできる。音楽学校の先生が授業で合唱の仕組みを教える。個人のクリエイターが大規模な合唱作品を作る。そういったことが、すべて可能になるんです。
——今後、さらに機能を拡張していく予定はありますか。
Kanru:もちろんです。コーラス音源についても、今後さまざまなスタイルを追加していく予定です。そして、合唱機能自体も、さらに進化させていきたいと考えています。
AI合唱の時代は、今日から始まりました。これからどんな作品が生まれてくるのか、私自身もとても楽しみにしています。

——本日は貴重なお話をありがとうございました。
Synthesizer V Studio 2.2.0は本日より無償アップデートとして提供開始。新コーラス音源3種(日本語・英語・中国語)も本日より発売されています。詳細はDreamtonics公式サイトおよびAHS公式サイトをご確認ください。
【関連情報】
Synthesizer V Studio製品情報


コメント
今回のアップデートは相当画期的ですね。コーラス音源も凄く興味あります。購入資金の小遣いを工面出来次第Choir Voices #2から買う予定です。
合唱音源は色々調べてました…日本語どころか英語歌詞が出来るのも少なく、殆どラテン語なんですよね…
個人的には少女合唱団、小中学生の発表会で歌うような素人っぽいのとか、童謡・ポップス系のとか、欲しいです!
これは本当に画期的なことです。
…それにしても,最初のデモ音源,男声が1オクターブ低いのは修正していただきたかったです。
先月、購入資金を工面したので#2を買いました。このボイスデータが出るまではEWのSymphonic Choirを買うかどうかで悩んでたんですが、待った甲斐がありました。他ならぬSynthesizer Vでクワイア音源を製作頂いたのは本当に嬉しいです。使い心地は当然Synthesizer Vなので言う事ありません。音声のクオリオティ・発音のリアルさも今の私には十二分です。
今までは自由に言葉を入力出来る音源は、ほぼ先述のEW・Symphonic Choirだけという状況でした。しかし、これで大きく状況は変わりましたね。色んな製作者が色んなクワイアを聴かせてくれそうで楽しみです。しかも#1や#3とかの、ジャンル違いまであるんですよね。