日進月歩の技術の世界ですが、もはや人間とコンピュータによる歌声の違いを識別できないレベルのところまで技術は進化してきたようです。本日、国立大学法人名古屋工業大学の国際音声言語技術研究所と名古屋の大学発ベンチャー企業である株式会社テクノスピーチが共同で「超高音質な歌声を再現するAI歌声合成システム」を発表しました。
これまでVOCALOIDを中心とした歌声合成のシステムがDTMの世界に広がり、ひとつの音楽ジャンルというかひとつの文化を作り上げてきたといっても過言ではありません。しかし、それとは明らかに次元の異なる歌声合成のシステムが登場してきました。ある種コンピュータっぽさ、無機質さが売りでもあったVOCALOIDに対し、今回発表されたのは人間の声質やクセ、歌い方を再現する、まさに人の歌声と区別のつかないレベルの歌声合成。現時点では技術発表であって、まだ製品化はされていませんが、歌声合成技術の革命といってもいいと思います。
名古屋工業大学とテクノスピーチが共同開発したAI歌声合成システムによる歌声
何はともあれ、まずはこの歌声を聴いてみてください。
どうですか?ちょっと衝撃ですよね。実は私にとって(きっと多くの方にとってもだと思いますが)、今年このような衝撃を受けたのはこれが2回目。そう7月26日にMicrosoftのAI女子高生「りんな」による歌声を聴いて驚いたのに続くものです。
もしりんなの歌声を聴いてないという方はこちらのビデオをご覧ください。
これも衝撃的だったわけですが、詳細については私のAV Watchの連載「AIりんな、歌の上達は驚異的。人のように歌う仕組み、ボカロとの違いとは?」で書いているので、そちらをご覧ください。
さて、今回のAI歌声合成システムも、Microsoftのりんなと無関係ではないようなのですが、これを開発した名古屋工業大学の国際音声言語技術研究所は徳田恵一教授による研究機関、そして株式会社テクノスピーチは徳田先生の研究室出身の大浦圭一郎さんが代表取締役を務める大学発のベンチャー企業。このお二人の名前を聞いて「ああ!」と言う方も少なくないと思います。

名古屋工業大学の教授、徳田恵一先生
そう、お二人は歌声合成ソフトであるCeVIOやクラウドで利用できる無料の歌声合成システムSinsyの開発者でもある方々。5年前に「ボカロに有力対抗馬登場!? 新歌声合成ソフトCeVIOの衝撃!」という記事でお二人にインタビューしたこともありましたし、7年前には「名古屋工業大学開発のフリーの歌声合成システム、Sinsyを使ってみよう」という記事でも紹介したことがありました。歌声合成の技術においては、世界的にも著名な研究者です。

株式会社テクノスピーチの社長、大浦圭一郎さん
本日発表のプレスリリースを見ると
とありますが、あまり詳しい話はありません。
が、徳田先生から、先ほどのデモ曲のボーカル部分だけを抽出したデータもいただきました。いただいたデータは2つあり、1つはこのディープラーニングによる技術革新前のデータ、つまりCeVIOやSinsyなどと同様の技術で歌わせたもの。もう一つが、技術革新後のデータです。
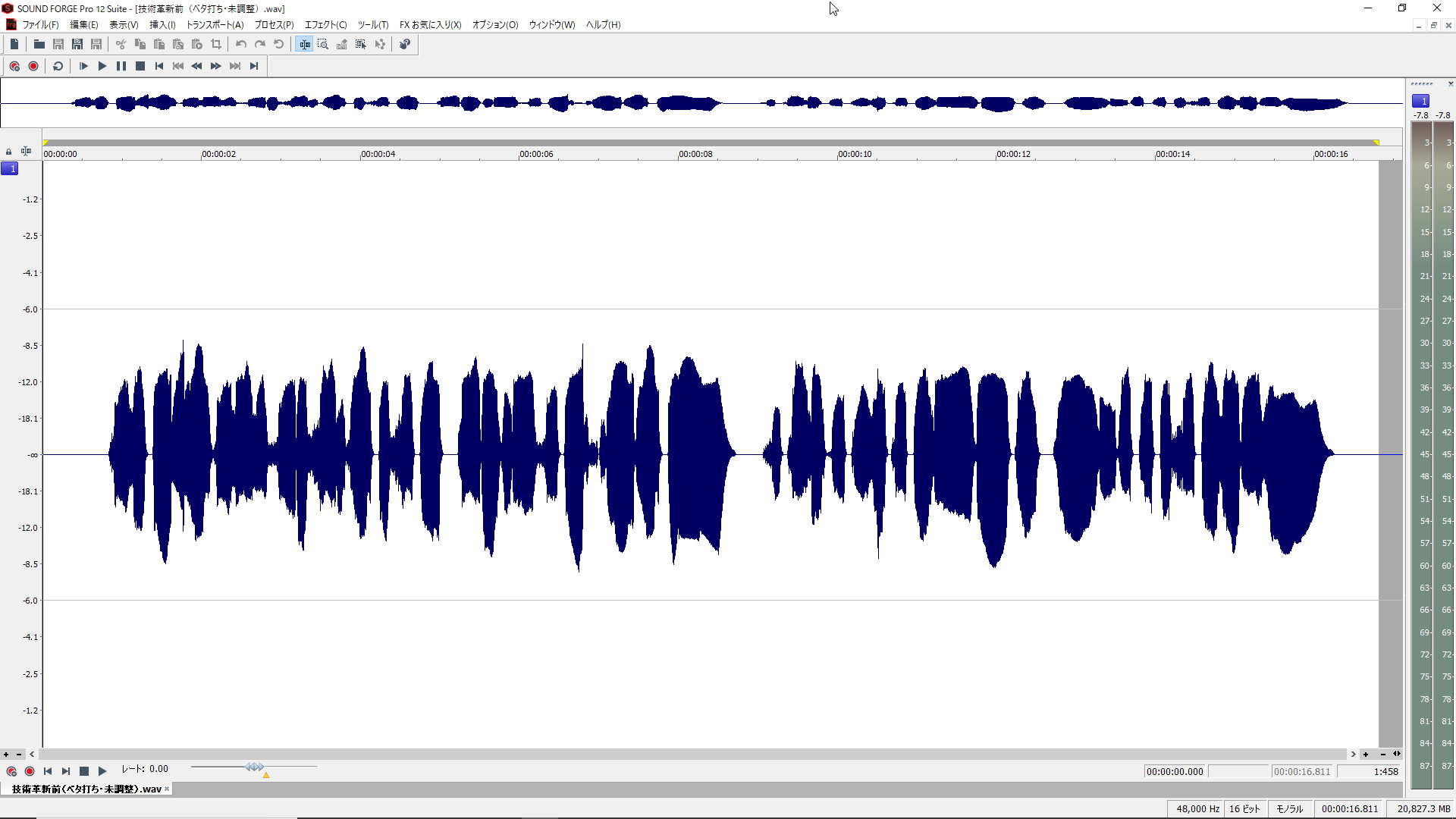
技術革新前=CeVIO、Sinsy時代の歌声合成の結果
それぞれを波形で見比べてみると明らかな違いがあります。技術革新前は単調でダイナミックレンジの幅が少ないのに対し、技術革新後のものはかなり大きく振れているのが分かります。これは単に音量の大小というものではないですね。
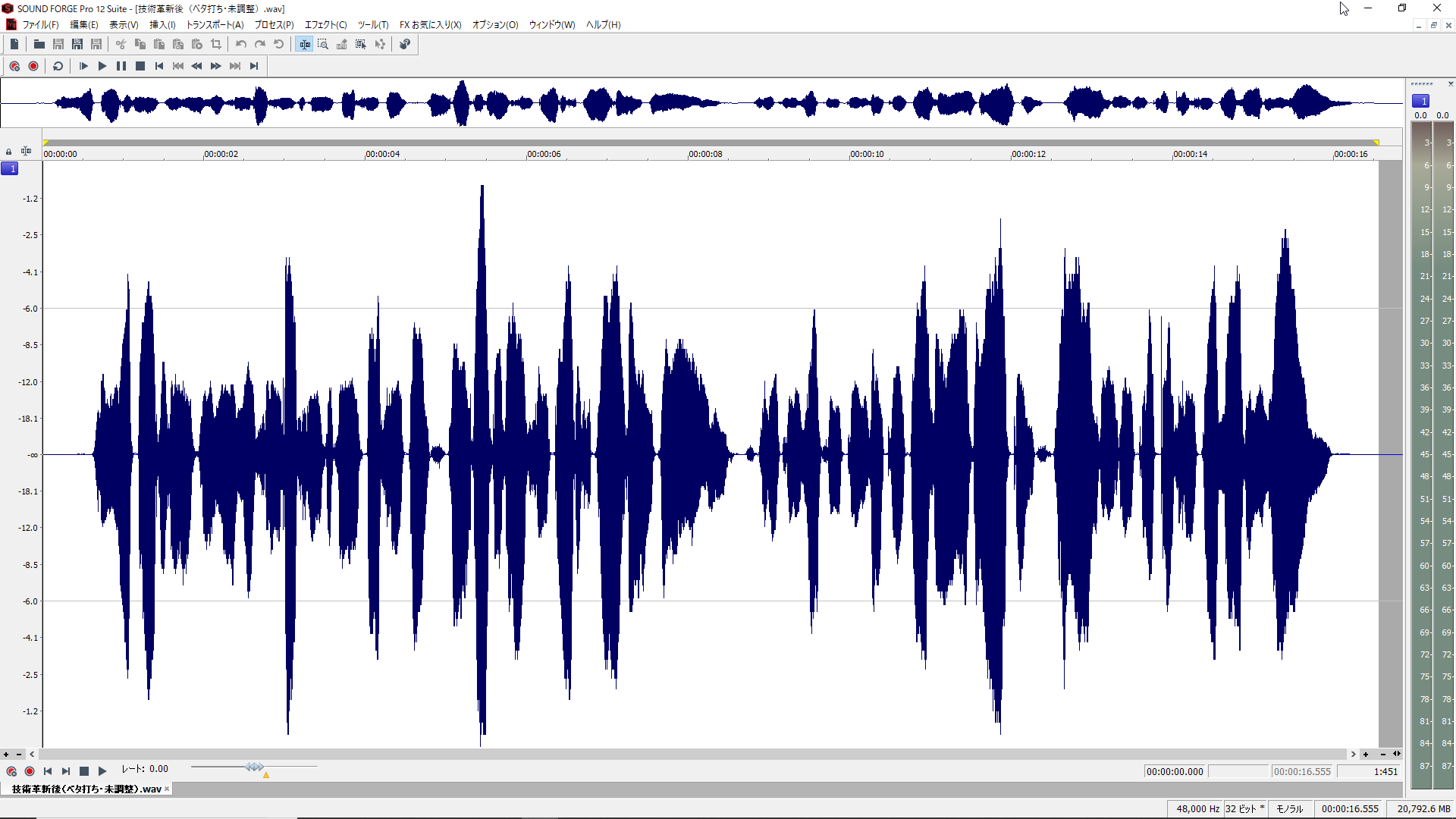
技術革新後のディープラーニングを取り入れたAI歌声合成システムでの合成結果
実際に聴き比べてみるとその差がよりハッキリと分かります。まずは、技術革新前のものから。
これは、聴きなれた感じのコンピュータによる歌声合成ですよね。もちろん、これでも十分キレイに歌えているとは思いますが、やっぱり「コンピュータが歌っている」という面を感じることは確かです。それに対し、今回の技術革新によって作り出された新しい歌声合成がこちらです。
冒頭のデモと比較すると、オケがなくなり、ボーカルだけとなった分、音質的な粗が多少目立つという面はあります。でも、従来の歌声合成とは明らかに次元の異なる歌声ですよね。声の消え入る部分なんか、シンガーの感情まで感じられるような気がして、鳥肌が立ってしまいました。もちろんベタ打ちでの入力ですから、感情なんてあるはずもないんですけどね。
このまま進めば、もう人の歌声との区別がつかなくなりそうです。よく人間に似せる技術進化の過程において「不気味の谷」というものがあるといいますが、このAI歌声合成においては、すでに不気味の谷は超えてしまってますね。
さらにプレスリリースを見ると
とあり、学会でもまだ正式発表前ということのようです。とはいえ、いろいろと気になることもいっぱい。そこで、メールベースで、徳田先生にいくつか質問を投げてみたところ、お答えをいただいたので紹介しておきます。
--今回のAI歌声合成システムでは、CeVIOなどのように、メロディー情報と歌詞を入力するだけで、このように歌わせることが可能になった、という理解でいいですか?
徳田:その通りです。
--実際にユーザーが使える形での製品化する予定はありますか?製品化に限らず、Sinsyのようなクラウド処理の形でもユーザーが使えるものが登場するでしょうか?
徳田:早々に何らかの形で製品化できればと考えていますが、現状では、GPUを使ってもそれなりに計算時間がかかりますので、クラウド処理も含めてどのような形態がよいか検討しているところです。
--今回の歌声を聴いてMicrosoftのりんなの歌い方を彷彿しました。りんなは徳田先生の研究室にいた沢田慶さんが担当されていますが、これとの関係性はあるのでしょうか?
徳田:Deep Neural Networkを利用しているという意味では共通の部分がありますが、Microsoftさんの方では、「歌詞と歌声」から「歌声」への変換という形で、ユーザーの歌い方を真似るために活用しているのに対して、本方式では、完全に「歌詞付き楽譜」のみから歌声を合成している点が大きな相違点になります。
--今回のAI歌声合成システムには、これまでのCeVIOなどとは異なる調整パラメータがあるのですか?つまり喜怒哀楽など感情表現をするパラメータがあったりするのでしょうか?
徳田:原理的には、学習の仕方により、声質パラメータ、歌唱スタイルパラメータなど、さまざまなパラメータを導入することができますので、今後、このような部分にも挑戦していきたいと考えています。
このように、まだすぐに私たちが使える製品があるわけではないようですが、近い将来は登場しそうです。また新しい情報が入ったらお知らせしていきたいと思いますが、まずは製品化を心待ちにしたいと思います。
【関連情報】
国立大学法人名古屋工業大学 国際音声言語技術研究所
株式会社テクノスピーチ
【関連記事】
ボカロに有力対抗馬登場!? 新歌声合成ソフトCeVIOの衝撃!
ボカロとまったく作法が異なるCeVIO Creative Studioを使いこなせ
着実に進化していたボカロのライバル、CeVIO Creative Studio S
AIりんな、歌の上達は驚異的。人のように歌う仕組み、ボカロとの違いとは?
名古屋工業大学開発のフリーの歌声合成システム、Sinsyを使ってみよう
女子高生AIりんながnanaで歌ってる!?どんな仕組みで、何を狙っているのかMicrosoftに聞いてみた

コメント
パッと聞いた瞬間、調声したCevio(さとうささら)のイメージを持ちましたが、当たらずとも遠からずだったんですね。これが無調声だとすれば、確かに一段階、歌わせるソフトが人の歌に近づくように思います。
自分は、趣味DTMerですが、身近に歌ってくれる人もおらず、歌い手さんにお願いするだけの技術も人脈もない。それでCevioなどを使い始めたという経緯もあり、自分にとってはボカロのような「機械っぽさありき」よりも「ナチュラルな人間っぽさ」の方が重要と考えています。
今回の技術が実用化される段階まで行けば、「Newさとうささら」など発売されることも期待できるかと思いますが、そうなれば、今のCevioささらさんを是非アップグレードしたいと考えております。
なので、趣味ユーザーの手にも届きやすいよう、何卒リーズナブルな価格にて実用化をお願いしたいところです(笑)
追伸
ちなみに、今回のデモ曲、察するに旧来のVerはCevioさとうささらでしょうか。
新しい技術の方も、ニュアンスというか声質というか、どことなくささらさん(あるいはパラメータ元になっている某声優さん)っぽい感じがしましたので、開発段階から、まずは「Newさとうささら」の製品化を目指しているのかなぁと、期待混じりの推測をしております。
PLG100-SGを初めて知った時の驚きを思い出しました。
「スゴイ!」
個人的には、是非、Sachikoのような大人の歌声合成システムを作ってもらいたいと思っております。
これって本当にAIなんですか?人の声そのものですよね!!
現状ではCPU並びにGPUまで駆使してとのことですが、なんとか解決して頂いてDAWのプラグインとしての製品化を望みたいです。
素人の意見として、例えばVIENNA ENSEMBLE PROの様な外部マシンを利用してのホスティングツールを利用した動作なら(それでもある程度のスペックは必要でしょうが)すぐにでも可能では、とも思ったのですがどうなんでしょうか?
これが出来るということは、たとえば人声ではなくても、バイオリンの名演奏を学習させておいて、
それから楽譜を入れると、デジタルで合成されたバイオリンの名演奏の音を作り出す、そういう
こともできそうですね。
[…] 歌声合成技術に革命!ディープラーニングで人間さながらに歌うAI歌声合成システムを名工大とテクノスピーチが開発 […]
[…] 動画説明欄に詳細あったhttps://www.dtmstation.com/archives/22902.html […]