今年に入り、AI歌声合成の動きが激しく、その進化のすごさ、クオリティーの高さには驚くばかりです。中でも注目すべきは今年2月に彗星のように登場し、フリーウェアとして公開されたNEUTRINO(ニュートリノ)です。これはSHACHI(@SHACHI_NEUTRINO)さんが開発するフリーのソフトであり、これまで東北きりたん、謡子、そしてJSUT(いずれも学術的に公開されている歌声データベースを利用して開発している)の3つの歌声ライブラリが同梱されてました。そこに9月18日、新たに東北イタコが追加されたのです(9月18日現在、公開されている0.400には東北きりたん、東北イタコのみが同梱。それ以外については後日公開される模様です)。
先日、「AIきりたんに次ぐ第2のAIシンガー、東北イタコの歌唱データベース制作プロジェクトのクラウドファンディングスタート」という記事でも紹介し、無事にクラウドファンディング成功となった東北イタコの歌声が、さっそくNEUTRINOに搭載されたという恰好です。このNEUTRINOは2月のリリース時のv.0.100から、どんどんと機能・性能が向上しており、今回登場したのはv.0.400。実際、東北イタコや進化した東北きりたんの歌声を聴いてみると、もはや人の歌声との区別がつかないレベルです。実際、何が起きているのか、開発者のSHACHIさんにもインタビューしてみたので、紹介してみましょう。
 NEUTRINO 0.400が公開に。東北きりたんに加え、東北イタコも歌声ライブラリに追加された
NEUTRINO 0.400が公開に。東北きりたんに加え、東北イタコも歌声ライブラリに追加された
まずは、この東北イタコによる歌声のデモ曲、「she」が公開されているので、これを聴いてみてください。
驚きですよね。このデモを作成したのは、NEUTRINO 0.100が公開されたときにも協力していた、くろ州(@kM4osM_96s)さん。まったく調声していないベタ打ちの歌声がこれだというのですから、すごい世界になっています。また、ClariSの「ヒトリゴト」を東北イタコと東北きりたんにデュエットさせたデモ曲がこちらです。
※2020.9.18追記
くろ州さんがUPされたYouTubeの「ヒトリゴト」が再生できなくなっているため、ニコニコ動画のものに差し替える形で掲載しました。YouTubeは無調声なのに対し、ニコニコ動画側は調声された歌声データになっています。
もう、数年前の歌声合成とは、まったく次元が異なる世界に進化したことが分かるのではないでしょうか? 以前の記事「AIきりたんの仕掛け人、森勢将雅准教授に聞く、AI歌声合成の世界で今起こっていること」でも紹介したとおり、東北きりたんの歌声は茜屋日海夏(あかねやひみか)さんの歌唱データベースをディープラーニングさせたものであるのに対し、東北イタコの歌声は木戸衣吹さんの歌声をディープラーニングさせたものとなっています。楽曲を制作したくろ州さんから、以下のようなコメントもいただいています。
くろ州さんからのコメント
 |
AIシンガーイタコを早めに触らせてもらいましたが、彼女は肺活量が大きく早口にも強い印象です。個性的でちょっとじゃじゃ馬な部分もありますが、人間らしさを保ったままできることが増えているので、きりたんと合わせて歌わせてあげるとよく輝いてくれます。 |
せっかくなので、もう1曲、くろ州さんがUPされた東北きりたん、東北イタコのデュエット曲「ギミック」を掲載しておきますので、ぜひ、こちらも聴いてみてください。
東北きりたんと東北イタコというポップス系を上手に歌えるアイドル歌手が2人揃ったことで、さらにできることの幅が大きく広がったと思います。
 NEUTRINOはmusicXMLファイルを読み込ませることで歌声合成を行うソフト
NEUTRINOはmusicXMLファイルを読み込ませることで歌声合成を行うソフト
一方、NEUTRINOのシステム自体もこの半年ちょっとの間で急速に進化してきているので、簡単に紹介してみましょう。
まず初期の0.100のときにWindows、さらに0.102でLinux版、0.103βでmacOS版も登場し、無料であることもあって、多くの人が試していました。それが4月に0.200になった際にNSFというエンジンに対応したのが最大のトピックスでした。
上記の森勢先生の記事でも紹介したWORLDというエンジンに対し、GPUで動かすNSFというエンジンを採用することで、より人間っぽい歌声が出せるようになったのです。ただし、NSFを使うにはNVIDIA製のGPU(3GB以上のGPUメモリを推奨)が必要となり、ない場合にはCPUベースで動かすWORLDでの合成となります。
 Google Colaboratoryを使うことで、ブラウザからの歌声合成が可能になった
Google Colaboratoryを使うことで、ブラウザからの歌声合成が可能になった
ただ、NVIDIAのGPUなんて持っていないという人も少なくないでしょう。そんな人のために、Googleの機械学習システム、Google Colaboratoryを用いて、クラウド上で歌声合成するシステムもリリースされています。これはもともとLinux版として出ていたNEUTRINOが進化したものであり、ブラウザ上から実行できるようになっています。
0.2xxまでは歌声ライブラリとして東北きりたん、謡子の2つだったのに対し、0.3xxになってJSUTという歌声ライブラリが追加されました。これは東京大学 猿渡研究室が作成し無償公開している音声コーパスをディープラーニングさせて作ったものですね。
さらに、0.310、0.320と進化する過程で、高速化が実現されたり、スタイルシフト機能なるものが追加されるなど進化し、3分の曲を合成するのに1分程度で実現できるようになってきました。そして、今回それをさらに進めた0.400がリリースされたのです。
一方で、NEUTRINO自体は楽譜データであるMusic XMLを読み込むと歌声に変換するという、かなりシンプルなシステムであり、だからこそ、難しそうに感じた方もいるかもしれません。また、VOCALOIDやCeVIO、Synthesizer Vのようなエディタ機能を持っていないので、扱いにくいソフト、調声ができないソフト…というように認識している人も多いと思います。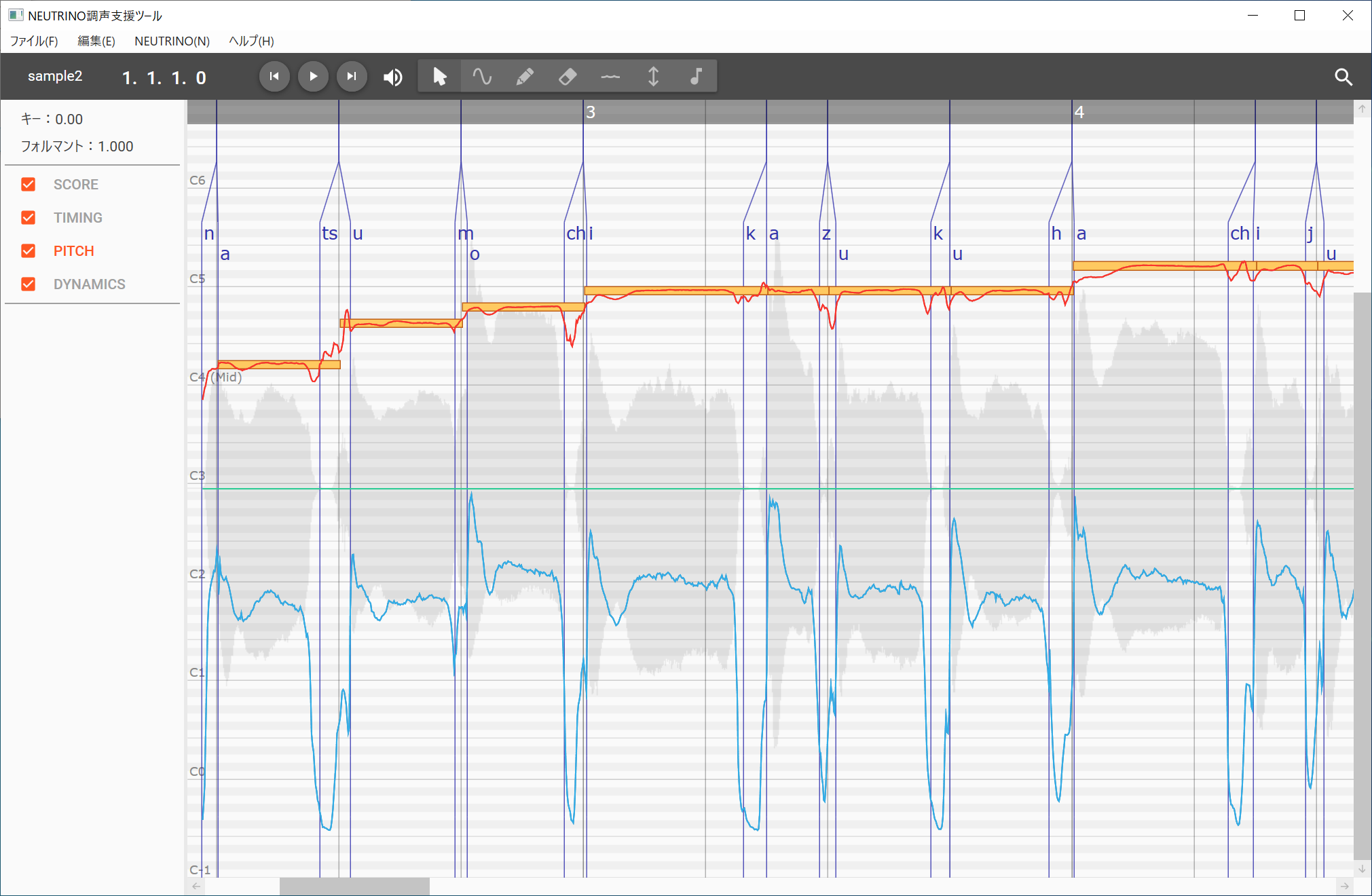 NEUTRINO調声支援ツール
NEUTRINO調声支援ツール
ところが、NEUTRINOの外部ソフトとしてsigさんという方がNEUTRINO調声支援ツールなるソフトを開発し、やはりフリーウェアとしてリリースしているため、VOCALOIDなどと同じような感覚で使うことができるようになっており、タイミングを動かしたり、ピッチカーブを調整したり、ビブラートを付ける……といったこともできるようになっています。それでも、あらかじめMusic XMLのデータは作成した上で、このNEUTRINO調声支援ツールに読み込ませて……という手順は必要なものの、断然使いやすくなっているので、セットで使うことをお勧めします。
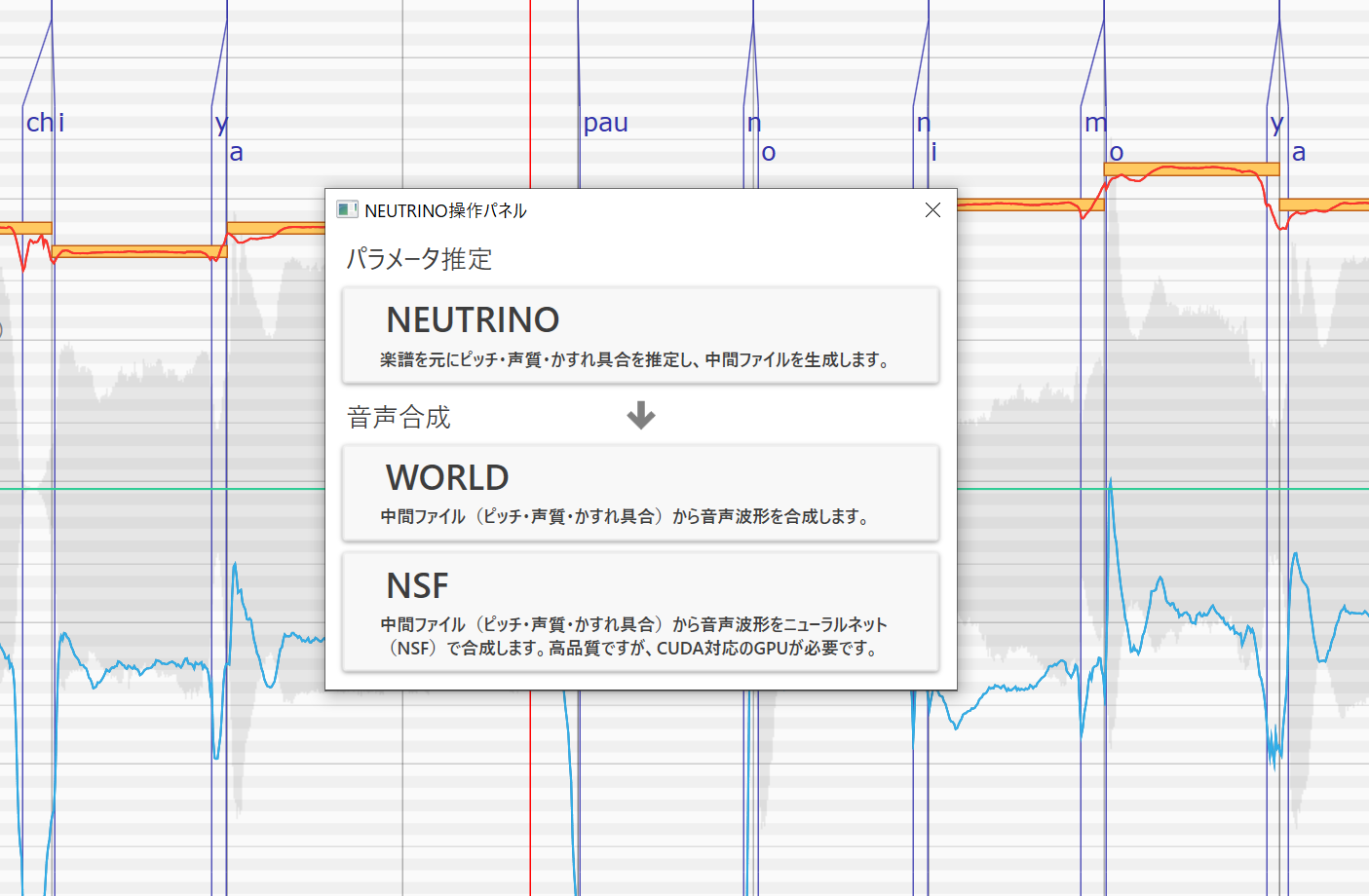 NEUTRINO調声支援ツールからNEUTRINOを使った合成ができる
NEUTRINO調声支援ツールからNEUTRINOを使った合成ができる
さて、このNEUTRINO、どうしてこんなすごいソフトが無料で公開されているのか、また東北イタコが、こんなにすぐに公開されたのかなど疑問に思うこともいっぱい。そこで、開発者のSHACHIさんにTwitterのDMを通じてインタビューさせてもらったので、紹介しましょう。
 |
NEUTRINOの開発者 SHACHIさんインタビュー |
ーー2月のNEUTRINOの突然のリリースに驚きましたが、SHACHIさんはもともとどういう経緯で、NEUTRINOを開発し、フリーで公開されたのでしょうか?
SHACHI:東北きりたん歌唱データベースが公開されたのがきっかけです。アイドル声優の歌い方・2013年以降の楽曲オンリー・権利関係がクリアという点が特徴的なデータベースで興味を惹かれました。デモ音源を作ったところで目的はある程度達成していたのですが、せっかくなので色々な人に使ってもらった方が面白いと思い、Windows用プログラムを作成し公開しました。非商用であれば手早く学習済みモデルを公開できそうだったのでフリーにしました。
ーーその後Linux版やmacOS版もリリースされていったわけですが、これだけの完成度があるのに0.1xxというバージョン名が、控えめですごいなとも感じました。
SHACHI:ちなみに初期バージョン(v.0.1)のコンセプトはローカルで動くSinsyです。『楽譜を渡すと音声が返ってくる』という必要最低限の機能ながらも、機械学習ベースの歌声合成器としてのコンセプトが活かされており気に入っています。最初は簡易なものをリリースしてどのように利用されるか様子を見つつ、半年ぐらいかけてアップデートしていくつもりでしたが、想定以上にに利用者が多く急ピッチでアップデートを行いました。
ーーv.0.2系で対応されたNSF対応について、手元にGPUがないので、初めてGoogle Colaboratoryをインストールして試してみました。クラウドでの利用なのにGPUが使え、高速に処理できるのに驚きました。とりあえず、デフォルトの「春が来た」を作成した場合、sample1_syn.wavとsample1.nsf.wavの2つができますが、synのほうがCPUでの処理、nsfがGPUでの処理という理解でいいのでしょうか?ちょっと聞いただけだと、あまり差を感じませんが、波形を見ると明らかな違いもあり、synのほうがダイナミクスがより大きく触れているようにも見えます。処理速度は別にして、音質重視で考えると48kHzという点も含め、CPUベースのほうが上と見たほうがいいのでしょうか?
SHACHI:現状では、WORLDはCPU、NSFはGPUのみで動作します。WORLDは入力したパラメータを忠実に再現するのに対して、NN Vocoder(NSF)は人間の声に近くなるようにNNで補正が掛かるようなイメージです。サンプリングレートについては、0.320では24kHzという制限がありましたが、今回0.400にしたタイミングで32kHzにまで向上させました。確かにそれでも32kHzという制限があるわけですが、パラメータ推定時のミス(over-smoothingなど)が補正されるため、適正音域であれば基本的にはNN Vocoderの方がより生音声に近くなります。もっとも、東北きりたんはWORLDと相性がいいため、「春が来た」のサンプルでは違いは分かりにくいかと思います。ぜひ、JSUTなどでお試しいただけると分かりやすいかと思います。。
ーー 今回の東北イタコ、まだ森勢先生側での歌唱データベースが公開されていないのに、先にNEUTRINOでの歌声ライブラリがリリースされるということで驚きました。もちろんイタコのプロジェクトにSHACHIさんが入っていたのは存じていましたが、どうして森勢先生よりも先にリリースできたのでしょうか?
SHACHI:一般的な話で言えば、音声ファイルと楽譜(歌詞+メロディー)が基本セットになります。詳細な音素境界の時間が書いてあるラベルなどはオプション的な立ち位置です。たとえば、テキスト音声合成の方ではEnd-to-Endの流れに移行してきており、テキスト(+α)と音声を直接マッピングすることが盛んに研究されています。前処理・中間処理なども含めてニューラルネットに任せてしまう、というアイデアです。以下のようなサイトが一つの参考になるとは思います。
https://r9y9.github.io/blog/2017/10/15/tacotron/
https://jp.techcrunch.com/2017/12/20/2017-12-19-googles-tacotron-2-simplifies-the-process-of-teaching-an-ai-to-speak/
最近では歌声合成においてもこのような論文がMicrosoftから発表されております。web上で集めたデータを自動処理して歌声合成器を作るという方向性の論文です。
https://arxiv.org/abs/2007.04590
https://speechresearch.github.io/deepsinger/
一方で、研究用DBとしては様々な情報があった方がいい場合が多いかと思います。東北イタコの歌唱データベース制作プロジェクトの中では、私もアドバイザとして適宜、データベースにフィードバックしていければと思います。
ーー0.1xx、0.2xx、0.3xx、そして今回の0400と、この短期間の間にどんどんバージョンアップをされていますが、今後のバージョンアップ予定などがあれば、少し情報をいただけますか?
SHACHI:0.1~0.3は開発版(αテスト版)、0.4はテスト版(βテスト版)という位置づけでいます。v.0.320でこちらのデモ音源作成時と環境を提供できるようになりました。これまでの間の主なテーマは以下のようなものでした。
致命的なバグ・エラーの修正
使用感の改善
プラットフォームの拡大(Windows / MacOS / Linux)
v.0.2: 品質向上
NN Vocoder(NSF)への対応
オンライン版の公開
v.0.3: 高速化
GPU対応によりオンライン版が高速化
WindowsでもGPUを使うことで最大で4~5倍速で生成が可能に
9月以降発売のRTX3000番台はさらに高速になる見込み
v.0.4: 複数のDBの活用
各モデルの品質の改善
音源の追加
ーー現在v.0.400になったわけですが、どうなったら1.0になるというお考えなのでしょうか?まだかなり将来の話だとしてもいいのですが、目指す方向性などがあれば教えてください。
SHACHI:v.0.4以降、話者数が増えてくることで、調声・ボーカル曲の作り方も今までとは異なったスタイルのものが出てくると考えています。その辺りの様子をみつつ方向性を決めたいと思っています。
ーーありがとうございました。これからのNEUTRINOの進化にも期待しております。
以上、NEUTRINO 0.400について紹介してみましたが、いかがだったでしょうか?誰でも無料で使えるこのNEUTRINO。東北イタコが追加されたことで、さらに強力な音楽制作ツールへと進化したと思います。VOCALOIDやCeVIO、Synthesizer Vなどと比べると、ちょっととっつきずらい……と思う方もいるかもしれませんが、まずは一度試してみてはいかがでしょうか?
※2020.10.05追記
2020.09.29に放送した「DTMステーションPlus!」から、第160回「KOMPLETE 13 & MASCHINE+」のプレトーク部分です。「AI歌声合成は、もう人の歌声と区別できないレベルに。東北イタコも追加されたNEUTRINOの新バージョン、0.400が無料でリリース」から再生されます。ぜひご覧ください!
【関連記事】
AIきりたんの仕掛け人、森勢将雅准教授に聞く、AI歌声合成の世界で今起こっていること
AIきりたんに次ぐ第2のAIシンガー、東北イタコの歌唱データベース制作プロジェクトのクラウドファンディングスタート

コメント
すごいですね。
これ無料なんですね。
VOCALOID、パラメータ知る手間が大変でもちぐされているのですが、べた打ちでこうなっちゃうんですか!?
DAWと連携できるようになるくらいエディタ類が揃ったり敷居が下がってきたら・・・素人でものぐさな私はとりあえず乗り換えるところから。
SHACHIさん、自覚されているよりよっぽど素晴らしいことやってると思います!
藤本さんも、手広いながらもあくまでDTM路線で読むだけで、いつもわくわくさせて貰ってます。
ありがとうございます。
私もNSFを体験したくて、NEUTRINOオンライン版をダウンロードして使用しました。ここで一つどうしてもわからないことがでてきました。OUTOUTに無事NSFに出力され試聴もできるのですが、これをDAWソフトにインポートするため、パソコンのマイミュージックに保存したいのですが、保存の仕方が分かりません。ご教示願えれば幸いです。
澤田さん
DAWにインポートするのは、DAWの仕様にもよりけりですが、普通にWAVファイルをドラッグ&ドロップすれば使えると思います。
また、読み込み時に、マイミュージック以外のところを指定すれば読み込めると思います。
もし、その方法が分からず、どうしてもマイミュージックに持って行くのであれば、マイミュージックのフォルダを開いて、そこへ
WAVファイルをドラッグ&ドロップすればコピーできると思います。
ご多忙のところ早速のご返信有難うございました。オンライン版で出力したNSFファイルは、直接パソコンへドラッグアンドドロップできないことが分かり、一旦オンライン版のNSFファイルを右クリックしてダウンロードをクリックすれば、無事にパソコンに保存できました。これをDAWソフトにドラッグアンドドロップすればOK。初歩的な質問で申し訳ありませんでした。今後ともご指導のほど宜しくお願いします。