昨年8月、彗星のように登場し、音声合成業界に大きな衝撃を与えたオープンソースのAI音声合成ソフトウェア、VOICEVOX。リリース当初はWindows専用で「ずんだもん」と「四国めたん」という2つのキャラクタの声でテキストを読み上げるソフトでしたが、その後、Mac版、Linux版が登場するとともに、GPUを使って高速に処理できるモードも搭載。そして、「春日部つむぎ」、「雨晴はう」、「波音リツ」……などなど多くのキャラクタが追加されてきました。すごいのは、商用・非商用を問わず無料で使えるということで(キャラクタによって利用規約は異なります)、多くの人たちに利用されてきました。
そして今回、VOICEVOXとして10番目となる新キャラクタ、「九州そら」が誕生。ノーマル、まあまあ、ツンツン、セクシーという4つのスタイルに加え、はじめて「ささやき」というものが搭載されたのです。これまで音声合成の世界で、こそこそと喋るささやき声は難易度が高いとされてきましたが、今回登場した九州そらは、これまでの常識を大きく変える、かなり衝撃的なものでした。実際、どんな声でささやくのか試してみるとともに、VOICEVOX、九州そらの仕掛人であるSSS合同会社の小田恭央さんにオンラインインタビューするとともに、システムを開発したヒロシバ(@hiho_karuta)さんにもメールでコメントをいただくことができたので、紹介していきたいと思います。
 VOICEVOXの新キャラクタとして九州そらが誕生。ささやき声で喋ることができる
VOICEVOXの新キャラクタとして九州そらが誕生。ささやき声で喋ることができる
まずは、難しいことはともかく、私がVOICEVOXの九州そらに、ささやき声で喋らせてみたので、こちらのビデオを、できればヘッドホンを使ってお聴きください。
どうですか? かなりゾワゾワするというか、九州そらの危険性が十分に理解できますよね。息を飲む感じ、口の中の音までリアルに表現されているのには驚きます。
VOICEVOXとはどんなソフトなのかは、昨年のリリース時に「商用でも利用可能なAI音声合成ソフトウェア『VOICEVOX』がオープンソースとして無料でリリース」という記事で紹介しているので、詳細はそちらをご覧いただきたいのですが、そこから半年ちょっとで、MacやLinuxで使えるようになったり、多くのキャラクタが追加されるなど、かなり進展してきているんですよね。
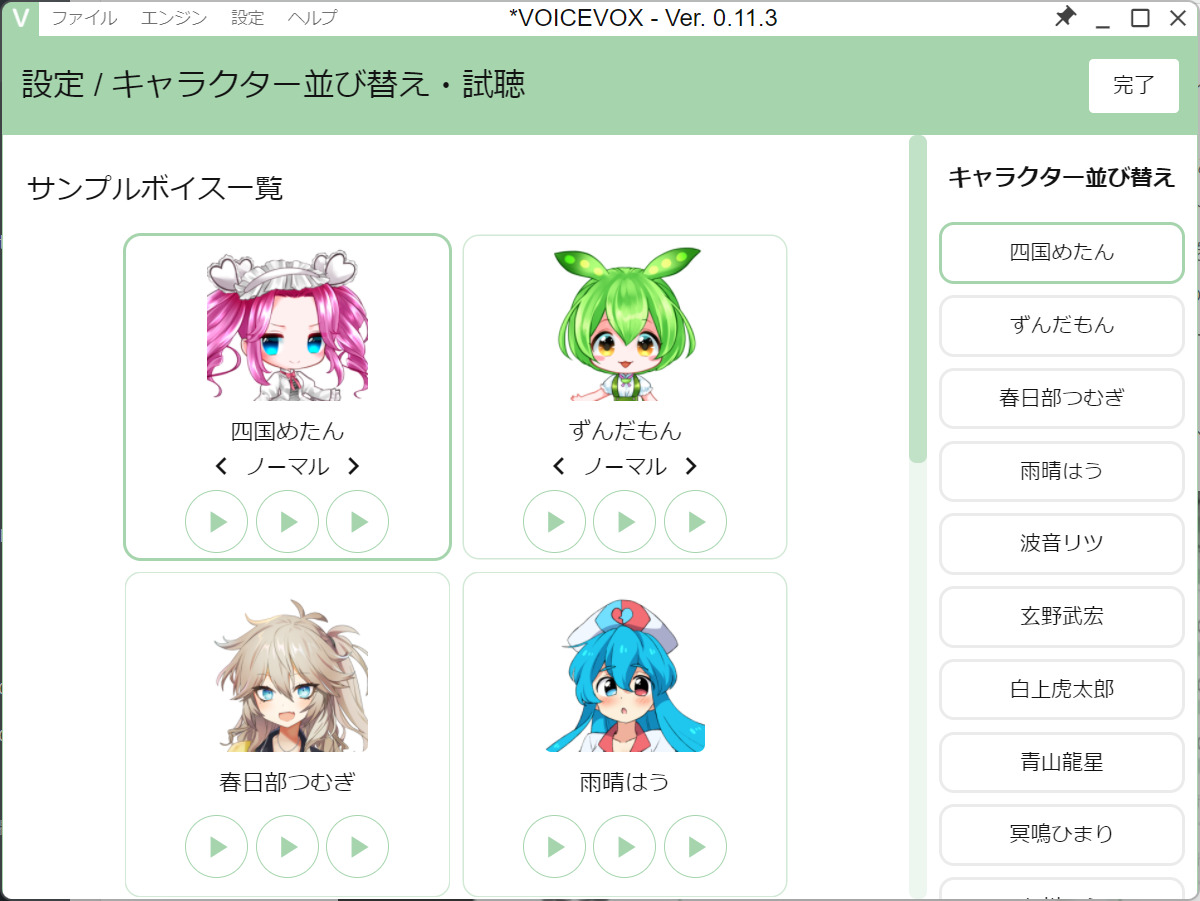 さまざまなキャラクタが追加され、これまで9種類のキャラクタが利用できた
さまざまなキャラクタが追加され、これまで9種類のキャラクタが利用できた
どのキャラクタもまさに人間そのものという感じで、昨今のAI音声合成の進化には驚かされるばかりですが、今回はまたこれまでにない、新たな試みという感じです。
使い方はいたって簡単。VOICEVOXのサイトからソフトをダウンロード、インストールした上で、キャラクタを選び、テキストを入力、再生すればいいだけなので、初めての人でも迷うことはないと思います。
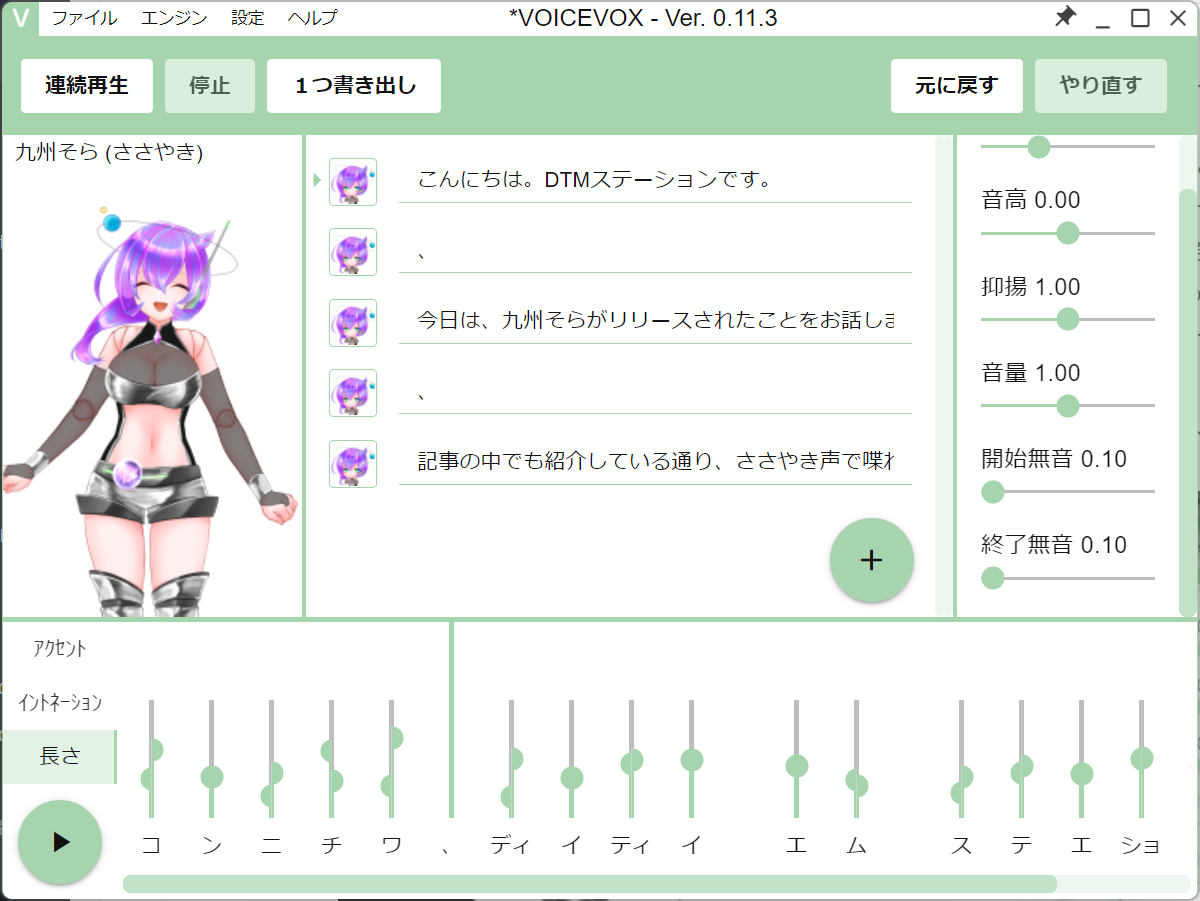
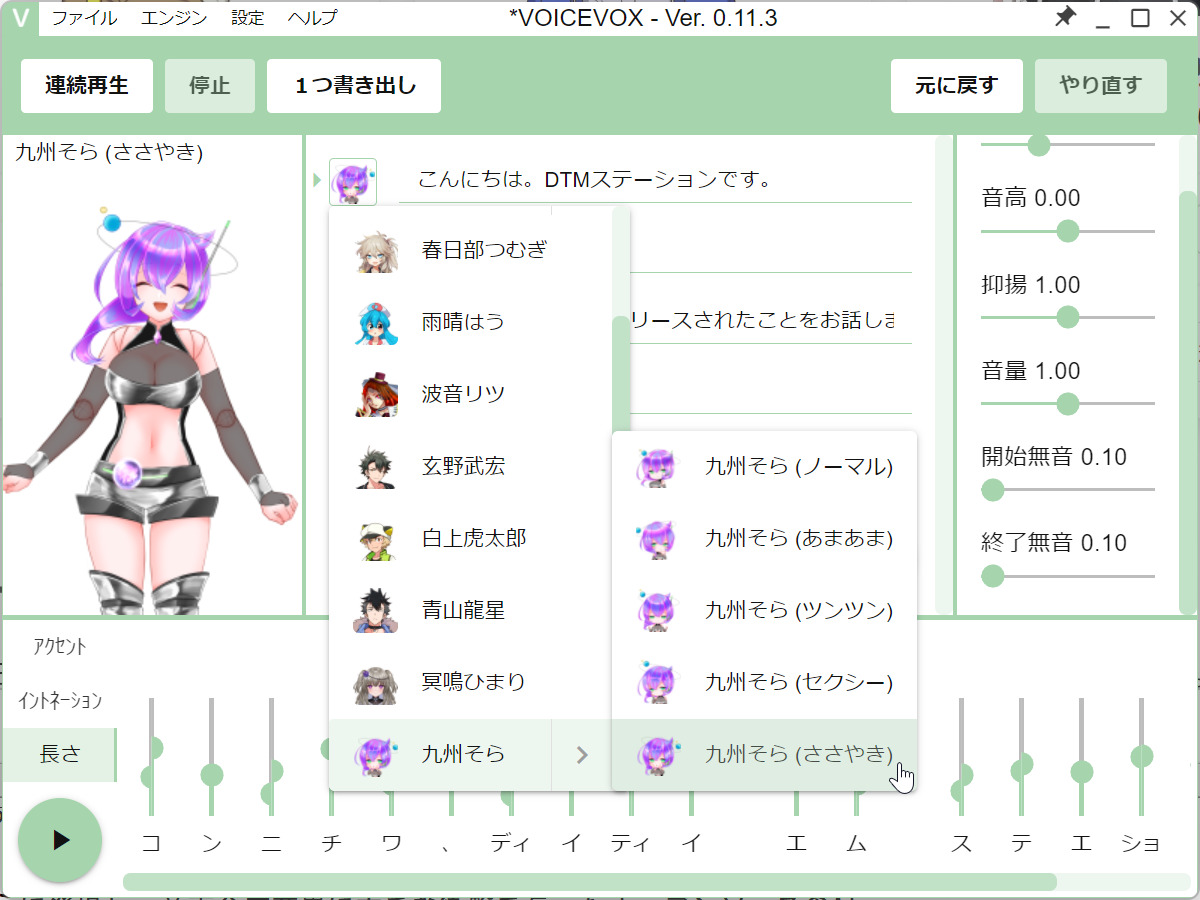 10番目のキャラクタ、九州そらは、全部で5つのスタイルを持っている
10番目のキャラクタ、九州そらは、全部で5つのスタイルを持っている
10あるキャラクタのうち、SSSが手掛ける、四国めたん、ずんだもんは、ノーマル、まあまあ、ツンツン、セクシーという4つのスタイルが選択できるようになっており、どれを選ぶかで喋り方の雰囲気も結構変わります。そして、今回登場した九州そらは、これら4つのスタイルに加え、「ささやき」が追加され、それを選ぶことで、先ほどのビデオのようなささやき声を簡単に喋らせることができるのです。
もちろん、このソフト上で喋らせてもいいしファイルメニューから「音声書き出し」を選べば、WAVファイルで書き出していくことが可能。この際「音声をつなげて書き出し」を選べば、すべての行をまとめて一挙に1つのWAVファイルを書き出せるようになっています。
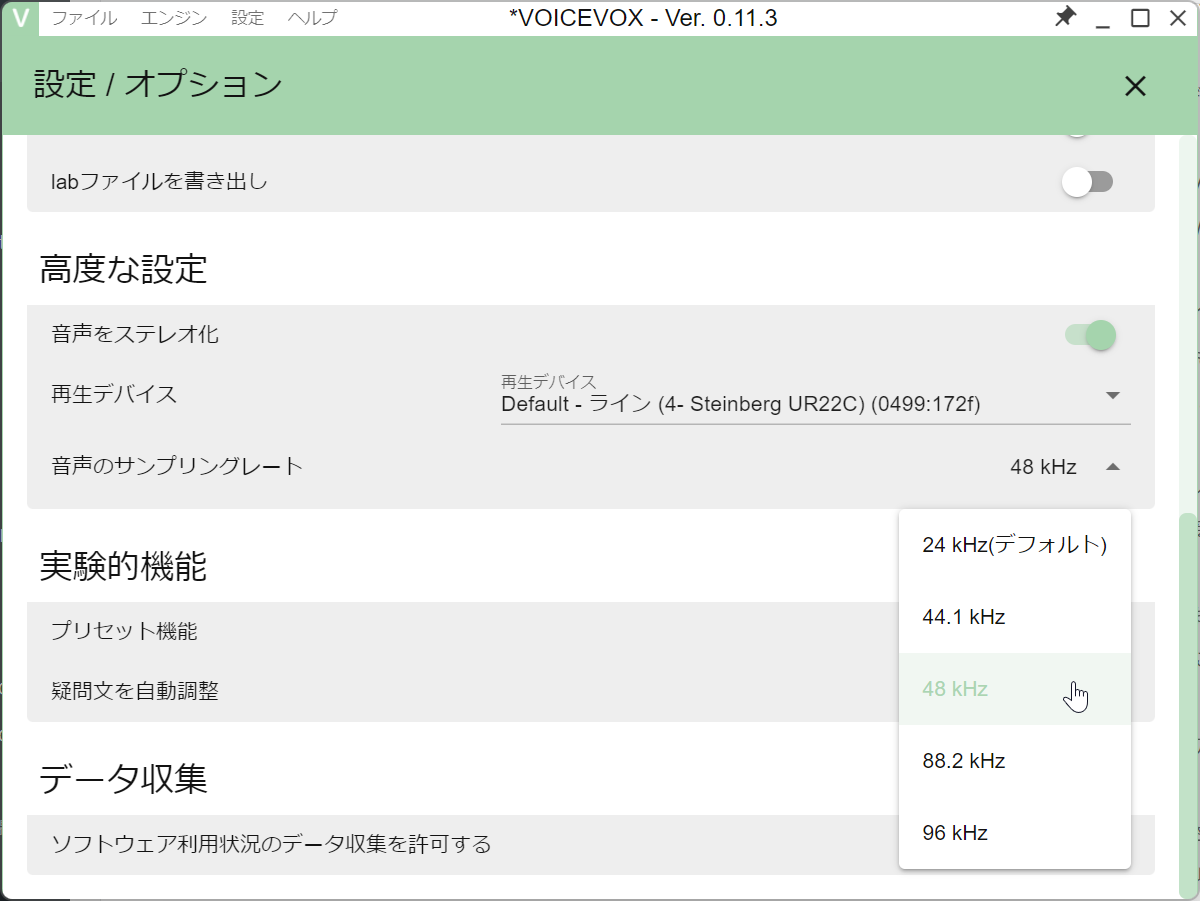 デフォルトでは24kHz/16bitだが、最大96kHzのサンプリングで出力することができる
デフォルトでは24kHz/16bitだが、最大96kHzのサンプリングで出力することができる
また、デフォルトでは、24kHz/16bitのWAVファイルとなっていますが、設定を変更することで44.1kHz、48kHz、88.2kHz、96kHzのサンプリングレートにしたり、ステレオにすることも可能です。ただ、ステレオといっても、音が広がるわけではなく、モノラル信号を単純にL/Rに展開してステレオにしているだけなので、両耳でささやかれるようにするには、DAWで加工したり、少しトーンを変えて2つ書き出す……などの工夫が必要だとは思いますが。
では、このささやき声をどのようにして生み出したのか、小田さんにインタビューしたので、紹介してみましょう。
SSS合同会社 小田恭央さん インタビュー
 オンラインインタビューさせていただいたSSSの小田恭央さん
オンラインインタビューさせていただいたSSSの小田恭央さん
--今回の九州そらのささやき声、以前プロトタイプをTwitterで公開してたのを聴いて衝撃を受けましたが、どういう背景でこれを作ることになったのですか?
小田:音声合成を利用するユーザーが多様化しており、最近はボイスドラマに利用するなど、さまざまな音声作品が登場してきています。いろいろ聴いている中で感じたのは、癒し系の声が求められているな…ということ。その一つとしてささやき声ができたら、多くの人に受け入れられるのではないかと思い、企画してみました。
--これまでも有声音を消して、ささやき声を作り出すというケースはありましたが、ここまでリアルなささやき声はなかったように思います。
小田:そうですね。普通の声から有声音を消してささやき声を作り出すのだと、どうしても本当のささやき声と比較して、違和感があるんです。その癒し系になりにくいというか……。そこで、今回は最初からささやき声を収録することで作っていきました。

--九州そらの場合、5つのスタイルがありますが、5つそれぞれ別々に収録して、ディープラーニングさせた、ということなんですか?
小田:その通りです。ノーマルで収録し、まあまあで収録し、ツンツン、セクシーで収録したほかに、まったく別にささやきで収録しているんです。ホントにこれでうまくいくのか、収録当初はなかなか予想もできなかったのですが、想像していた以上にホンモノができたという感じですね(笑)。作ってみて分かったのは、ささやき声は有声音がない分、合成しやすい、ということ。ただ技術的にん難しかったのは音素のラベリングです。本来なら、一つ一つの音が[子音]+[母音]の構成になっていて、音を聴いたり、波形を見れば、すぐに子音と母音のスタート位置、エンド位置が分かります。しかし、ささやき声だと、ほとんど母音が存在しないので、どこにラベリングすればいいかが分からないのです。
--確かに、ささやき声だと、母音がないですもんね。
小田:たとえば「こんにちは」の頭の「こ」でいえば、普通はKとOの位置がハッキリわかります。でもささやき声だと、KはわかってもOがどこから始まるのかが分からないんですよ。そこで、たぶん、この辺だろうところでラベル付けをする。失敗するかもしれない…と思いつつ、これまでの経験値、感覚値でやってみたのですが、想像以上にうまくできましたね。

--制作にはどのくらいの時間がかかったのですか?
小田:収録は10月にしているので、リリースまでに半年かかりました。このラベル付け、すべて手動で行うと大変なので、プログラムを使って自動化させているんです。そのため、ノーマルやツンツンなどは、その手法でだいたいうまくいき、違和感のあるところだけをチェックして手直しする形でした。ところが、ささやきは、かなり手作業となったため時間がかかってしまいました。そのデータをヒロシバさんに渡して、学習させた結果、うまくいき、ようやくリリースとなったわけです。
--小田さん、本当にチャレンジングにいろいろ活動されていますが、音声合成はこの先どのような方向に進んでいくというか、どうのようにしていきたいですか?
小田:ささやき声は、かなりエンタメに寄せた形ですが、さらにもっとエンタメに寄せていきたいと思っています。最終的には演技ができるようになればいいな、と。かなりリアルになったとはいえ、今のAI音声合成は、まだナレーションにすぎません。驚いたり、泣いたり、叫んだり、まだまだ発展していくべきだと思っていますが、まだその入り口にも入っていない感じです。そうした演技をさせるためにはもっともっと音素をいっぱい取り入れた台本をつくっていなくてはならないですが、まさに演技用の台本が必要になるし、演者によっても表現が違うし……、そこのレベルに行くには、まだ10年以上かかるのではないでしょうか? まだまだ音声合成はリアルな声優さんには追い付けないな、と。そんな音声合成をやるより、声優さんに頼んだほうが早いし、安い。もっと、演技ができるように挑戦していきたいですね。

--なんか、音声合成の未来形が想像できて、ちょっと怖くなります。でも、どう進化していくか楽しみですね。ありがとうございました。
ヒロシバさんからのコメント
小田さんがレコーディングし、ラベリングしたささやき声の機械学習するにあたり、何か困ったことはあったのか、特別な処理をしたか?という質問をヒロシバさんにメールで聞いてみたところ、以下のコメントをいただきました。
強いていえば音量バランスは少し工夫しました。録音したささやき声をそのまま扱うと話し声に比べて音量がかなり小さく、かといってそのまま振幅を同じくらいにすると音量に違和感がありました。
最終的にはラウドネス値を揃えることで、機械学習的にも実利用的にも納得の行く結果が得られました。
以上、小田さん、ヒロシバさんにお話しを伺いましたが、VOICEVOXはWindowsでもMacでも、さらにはLinuxでもパソコンさえあれば、誰でも無料で使うことができ、それで生成した声を商用でも非商用でも無料で使えるソフトです。ぜひ一度試してみてはいかがですか?
【関連情報】
VOICEVOX情報


コメント