5月17日、ドワンゴがSeiren Voice(セイレンボイス)という、これまでにない新たなAI音声合成システムの販売を開始しました。これは、従来のTTS(テキスト to スピーチ)と呼ばれる文字を入力して音声合成とは異なり、人が喋った声を入力し、その発音の仕方、イントネーションやスピード、間の取り方などを、トレースするかのようにターゲットのキャラクタの声に置き換え、非常に高品位な音声合成を実現する、というものです。
今回、その第一弾製品として、「結月ゆかり」、「琴葉 茜・葵」が、それぞれ19,800円(税込)でダウンロード販売の形でスタート。Windows10/11用となっていますが、動作させるにはNVIDIAのある程度のスペックを持ったGPUを搭載していることが必須となっています。そのため、体験版もリリースされており、これを使うことで実際に自分のPC環境で動作させることが可能なのかチェックも可能になっているようです。そのSeiren Voiceを開発したのは、ドワンゴの研究開発部門であるDwango Media Villageの廣芝和之(@hiho_karuta)さん。先日、その廣芝さんにSeiren Voiceとはどんなシステムなのか、お話を伺うとともに、実際に声を入力して、その音声合成を試してみたところ、その凄さに驚かされました。このSeiren Voiceとは何なのか、廣芝さんへのインタビューという形で紹介していきましょう。
 ドワンゴからSeiren Voiceがダウンロード販売の形で発売された
ドワンゴからSeiren Voiceがダウンロード販売の形で発売された
このSeiren Voice、1年以上前からネット上で話題になっていたので、ご存じの方も多いと思います。私もTwitterなどで、その動画を見て驚いたのですが、イマイチどんなシステムなのか理解できなかったのも事実。先日、都内で行われた音声合成関連のイベント「ボイスコネクト2」に行った際、ドワンゴとエーアイが共同ブースを出展しており、ここで実施されていたSeiren Voiceのデモには、Seiren Voiceを自分の声で試すことができるとあって、長蛇の列ができていました。
 ドワンゴの廣芝さん(中央)、VOCALOMAKETSのBumpyうるしさん(左)とかごめPさん(右)
ドワンゴの廣芝さん(中央)、VOCALOMAKETSのBumpyうるしさん(左)とかごめPさん(右)
さすがに人が多すぎて、そのときは遠慮させていただいたのですが、会場で廣芝さんと、VOCALOMAKETSのBumpyうるしさんなどがオペレーションを行っていたので、場を変えて改めてお話を伺う約束をさせていただいたのです。ちょっと時間が経ってしまいましたが、リリース直前に廣芝さんと、うるしさん、そしてエーアイの栗田圭奈さんにお会いすることができたので、いろいろと伺ってみました。
--Seiren Voice、すごく話題になっていますが、なぜニコニコ動画の運営会社であるドワンゴが音声合成ソフトを?と少し不思議にも感じました。まずは、その辺の経緯から教えていただけますか?
廣芝:ここはDwango Media Villageという組織で、機械学習の研究開発とサービスへの応用を担っているところです。ここでの研究はニコニコのサービスに直結するものだけでなく、コンピュータビジョン、3Dグラフィックス、音声、ゲームAIなど幅広く研究しています。その中で、私自身が趣味として声変換、音声合成の研究をしていたことをキッカケにSeiren Voiceを開発することになったのです。

Seiren Voiceの開発者であるDwango Media Villageの廣芝和之さん
--声変換が廣芝さんの趣味!?
廣芝:実は以前は漫画の自動着色の研究や論文を書く……といった仕事をしており、音声合成の技術についてはまったく知りませんでした。が、「結月ゆかりに、なりたい!」という思いが強くなり、個人の趣味として音声合成を研究をはじめ、ある程度のメドがついてきたことから、上司に「Seiren Voiceをやらせてくれ!」と懇願し、実際の仕事として取り組むことになったのです。
--これまでも、多くの企業から、さまざまな音声合成ソフトが出ています。実際、エーアイから「琴葉 茜・葵」や「結月ゆかり」が発売されていますが、それとは何がどう違うのでしょうか?
廣芝:これまでさまざまなアプローチの音声合成がありましたが、もっとリアルなもの、もっと高い品質な音声合成を実現するにはどうすればいいんだろうか……と考えていた中、たどり着いたのがこの形でした。A.I.VOICEなどの音声合成ソフトは、テキストを入力して声を生成していますが、喋り声を入力することで、文字だけでない数多くの情報を渡すことが可能になり、より品質の高い声が生成できるのです。最近はリアルタイムでボイスチェンジを行う技術なども出てきていますが、どうしても品質面では劣ってしまいます。それなら、圧倒的に高い品質の声にする……という思いから開発を行ってきました。
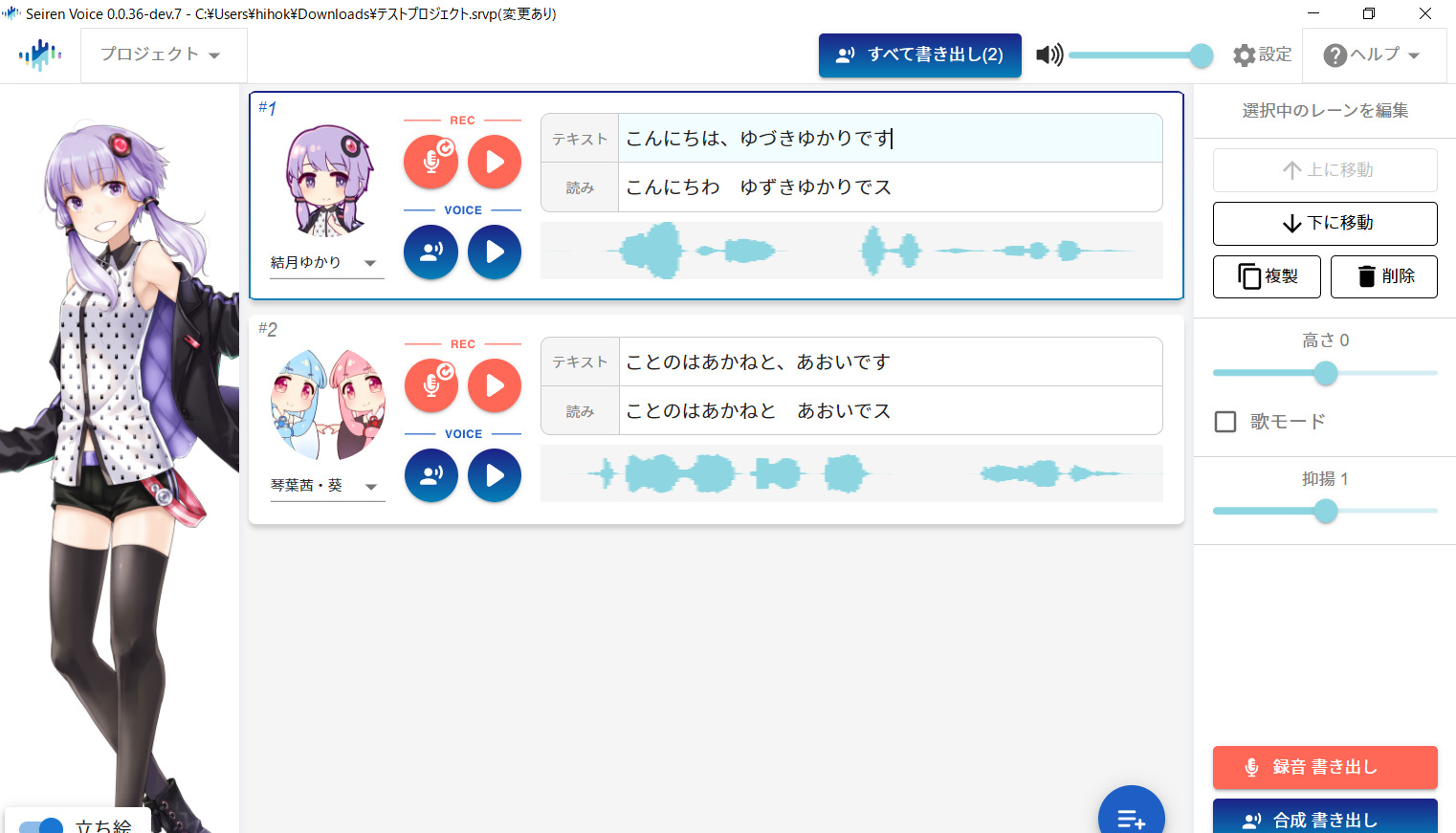
Seiren Voiceのユーザーインターフェイス
--実際、どんな声になるのか、少しデモしていただいてもいいですか?
廣芝:では「こんにちは、結月ゆかりです」と喋らせてみましょう。入力する声の喋り方を変えるとずいぶん違った感じでそれぞれ表現できるのがわかると思います。
--なるほど、これは確かに結月ゆかりの声だけど、ここまでの表現力を文字入力だけで実現させるのは無理ですね。一方で、声を入力するだけじゃなく、文字も入力する?
廣芝:音声認識によって読み方も自動生成されるようになっていますが、うまくいかない場合や認識ミスがある場合は手で入力したり修正したりする必要があります。
マイクを使って録音した喋り声を分解して要素を取り出した上でキャラクタの声を合成する
--詳細について、少しずつ伺っていきますが、その前に、Seiren Voiceってどういう意味でのネーミングなんですか?
廣芝:これは、ギリシャ神話のセイレーンから付けているんです。海の航路上の岩礁から美しい歌声で航行中の人を惑わし、海に沈める……という神話だったと思いますが、Seiren Voiceの声で魅了して、沼に沈める…というか(苦笑)。キャラクターの声になりたい、なり切りたいという思いを持つ人は少なくないと思います。でも、それを達成する上で、出てくる声が正にそのキャラクターであると思えることが大切です。だったら、品質に徹底的に特化しないといけないと……。
--「誰の声でも100人の声に変えられる声変換システム」というデモが公開されたときには、大きな話題になりましたよね。
誰の声でもいろんな声に変えられる声変換システムを研究開発しました。
また、品質を重視しつつ「誰の声でも」「様々な人の声に」するための課題と解決策を記事にしました。https://t.co/GKYklAb35K
(動画は開発者の声を声変換したものです。)#SeirenVoice #AIボイチェン pic.twitter.com/TZc5WYuRS1— Dwango Media Village (@Dwango_DMV) September 14, 2020
廣芝:これを公開したのは2020年9月でしたが、この時点ではまだホントにこの技術が世間に受け入れれられるのか分からなかったし、実際どんな製品にしていくべきかが見えていなかったので、まずは公開してみたところ、世間から注目が集まり、当時は研究者からも驚かれたので、行けそうだ、という手ごたえは感じました。ちなみに、この声は東京大学の高道研究室で作られたJVSコーパスという100人の声のデータを研究用ということでお借りしたものです。
栗田:私もこのときに初めて知りました。Seiren Voiceのデモができるページも用意されていたので、自分の声を入力して試してみたところ、そのクオリティーの高さに感動しました。100人の声になれるのですが、声によってすごくリアルにいくケースと、そこまでではないケースもあったりして……。やはり声によって相性はあるようですね。

株式会社エーアイの栗田圭奈さん
--うるしさんも、そのころに知ったのですか?
うるし:廣芝さんはVOICEVOXを開発するなど、会社とは別に「ヒホさん」として活動されています。が、そのヒホさんとして以前に紹介いただき、すごく面白い活動をされているなと思ったと同時に、何かご一緒できないかな…と思っていました。
廣芝:当初はこの技術にキャラクタをつける、つけない、といったところから議論しており、結構時間がかかりました。が、うるしさんや栗田さんをはじめエーアイの方々ともやり取りできるようになる中、製品の方向性なども固めていったのです。
--さて、そのSeiren Voice、実際どんな処理をしているのか、ごく簡単に教えていただけますか?
廣芝:Seiren Voiceは、いわゆるボイチェンソフトのように、声そのものを変換しているわけではなく、1度、声を要素に分解して、それを組み立てなおすという処理をしています。その要素とは3つあり「音素情報」、「音素の構成されているタイミング」、そして「音の高さ」のそれぞれです。この3つを得た後で音声合成をしているんです。こういう流れであるため、いわゆる文章だけでなく「え?」とか「えーと…」といった表現もできるし、ある程度歌うこともできるんです。
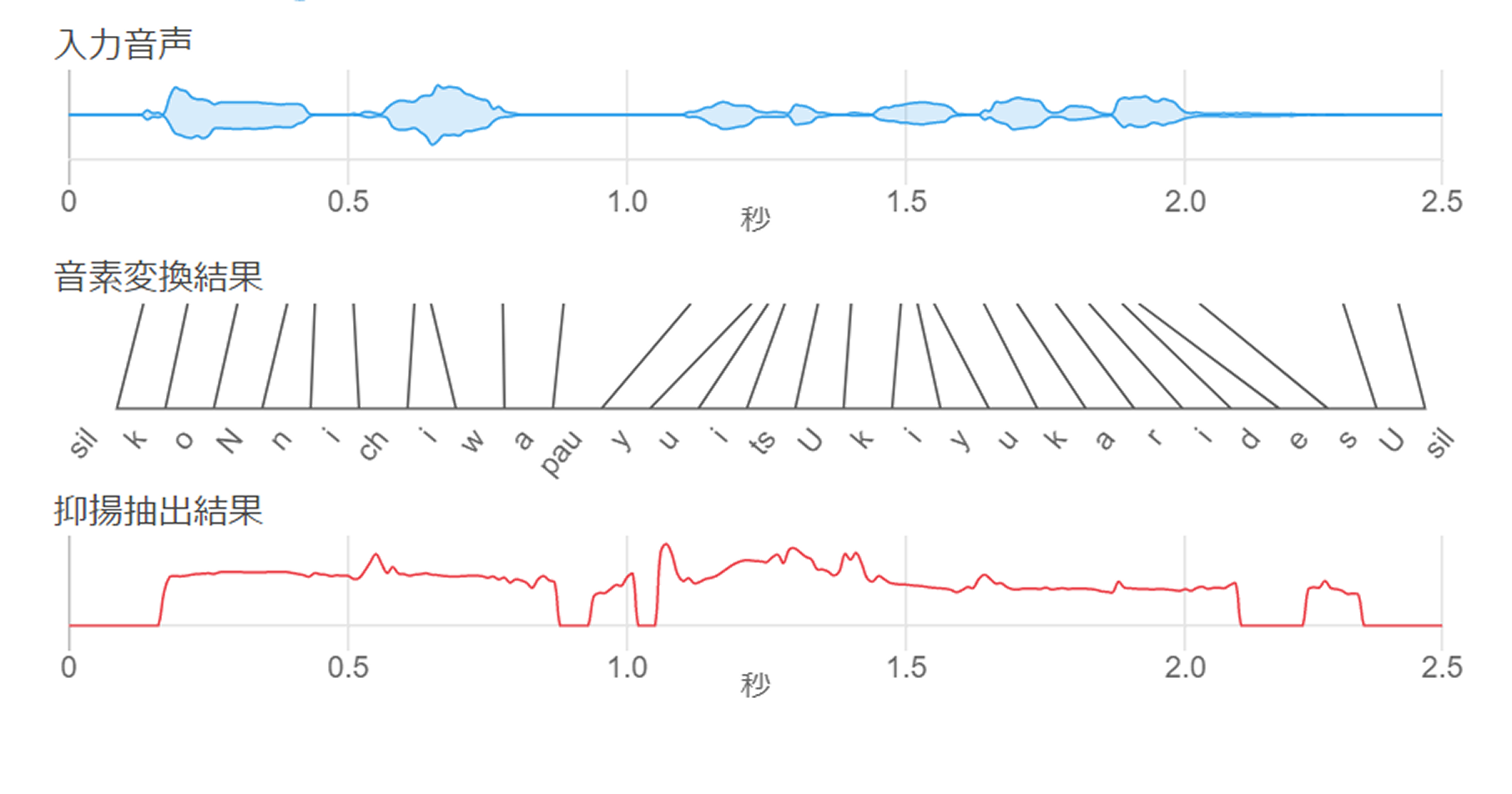
入力された音の情報を音素、その構成タイミング、音の高さの変化に分解する
--ということは日本語だけでなく、英語だったり、他の言語でも喋ることができるのですか?
廣芝:とってもいい質問ですね。先ほどのデモページでもそれを再現できるのですが、学習データが日本語であるため、英語にしかない発音はなかなか上手に発音できません。いわゆるジャパニーズイングリッシュになってしまうんです。だからこそ、そのキャラクタっぽくなるともいえます。イントネーションはネイティブだけど、発音はたどたどしい……といった感じになりますね。
Seiren Voiceの設定画面
--先ほど見せていただいたデモを見る限り、声を入力してから、音声合成が完成するまで、結構なタイムラグはありますよね?技術が進化したら、もっとリアルタイムに近づけたりするのでしょうか?
廣芝:Seiren Voiceの仕組み上、文章の頭から最後まで、端から端までを入れてから変換するという形になっているので、リアルタイムに……というわけにはいかないんです。でもだからこそ、文末に近づくほど声が小さくなっていく……といった表現も可能なのです。また、一度、入力された声を3つの要素に分解してから、組み立てなおすという形になっていることもあり、どれだけコンピュータ、GPUが高速化したとしても限界はありますね。
--そのGPUに関して少しお伺いしたいのですが、なぜSeiren VoiceはNVIDIAのGPUが必須となっているのでしょうか?
廣芝:NVIDIAでもGeForce GTX 1050などのクラス以上のGPUが必要となります。というのも、CUDA(Compute Unified Device Architecture:クーダ)というNVIDIAのツールキットを使っているからで、これを利用できる環境が必要になるのです。本来ならGPUを使うにせよ、RADEONなどさまざまなものに対応できればよかったのですが、そうすると開発にかなりな工数がかかってしまうし、そうしたとしても速度面でCUDAにチューニングしたほうが圧倒的に速くなるので、今回の製品はCUDAが利用できる環境ということで、NVIDIAに絞っています。ディープラーニング関連のソフトだとCUDAを使うものが増えていますが、それらと動作条件は同じということになります。

--もう一つユーザーとして気になるのは、Seiren Voiceを利用する上で、オーディオインターフェイスやマイクが必要になるのか、という点です。
うるし:ボイスコネクト2でデモしたときも、今日も、私が先日買ったSONTRONICS PODCAST PROというマイクを使っています。ゆかりにマッチした色のマイク、ということでこれを導入したのですが、実際の利用においては録音の品質はあまり関係ないので、ノートPC内蔵のマイクでも大丈夫ですよ。
廣芝:そうですね、多少ノイズがある環境でもまったく問題ないというのもSeiren Voiceの特徴です。元の声を加工するボイスチャンジャーとは違い、前述のとおり、3つの要素に分解して、それを再構築するという性格上、分解さえできれば、元の音質は、できあがる音質に影響しません。音の高さの動きやタイミングがしっかり取れればいいので、高価な録音環境は必要としません。

VOCALOMAKETSのBumpyうるしさん
--なるほど、よくわかりました。音の高さの動きがキレイに再現できるということは、方言なども上手に表現できるわけですか?
廣芝:はい、その通りです。従来のTTSでの入力だと、微妙なイントネーションなどが表現しづらい面はありましたが、Seiren Voiceであれば、音の高さの変化、音素の長さも含め、キレイに再現するため、方言も上手に喋らせることが可能です。
栗田:琴葉 茜・葵で一つのキャラクタという扱いになっていますが、まさにデータ的には一つのキャラクタになっています。関西弁を入力すれば茜だし、標準語で入力すれば葵になる、ということですね。
--ソフトの画面で少し気になったのが右側にある「高さ」・「歌モード」といったパラメータです。これはどんな役割なのでしょうか?
廣芝:通常は入力音声の高さをキャラクターの声の高さに合わせて音高を補正しています。そのため男性の声を入力しても、琴葉 茜・葵や結月ゆかりにマッチした声の高さで出力されます。ただ、この状態で歌を入れると音程が思った通りのものになりません。そこで「歌モード」をオンにすると入力音声のキーを維持したままオクターブだけ変えて音高を補正するようになります。
--先ほど、歌を入力することもできる、というお話でしたが、実際それを聴かせてもらうことはできますか?
廣芝:「ふ~ん、ふん、ふ~ん」といった鼻歌でも可能なので、少し試してみましょう。ここでは「歌モード」をオンにしています。
廣芝:こんな感じで、鼻歌であっても、テキストを入力していく必要はありますが、しっかり歌わせることが可能です。ただ、歌声を学習しているわけではなく、あくまで喋り声を元に歌わせているので、こんな歌声になるのです。この際、「歌モード」にチェックを入れれば、元のピッチのとおりに歌わせることができる、というわけなのです。
うるし:すでにSeiren Voiceの先行版という開発中のバージョンがプレゼントキャンペーンが実施され8人に配布されていましたが、使った人達が公開した動画を見ると、うまく歌わせていたりするので、面白いですよ。VOCALOID的な歌声ともCeVIO AIなどで歌わせる本格的なボーカルともまったく違う、台所で歌ってるような雰囲気の歌になるのがいいですね。
--試しに、実際にボーカルレコーディングしたデータを使って歌わせてもらってもいいでしょうか?3年前、DTMステーションCreativeレーベルの第1弾として出した小寺可南子さんボーカルの「Sweet My Heart」のボーカルデータで24bit/48kHzのWAVデータです。
廣芝:やってみましょう。Seiren VoiceはWAVやMP3のファイルを読み込ませることも可能です。あとは歌詞があれば、歌わせることができますよ。琴葉姉妹で歌わせてみるとこんな感じです。
--歌い方の特徴はかなりリアルに残しつつ、明らかに琴葉茜・葵の歌声になっているのは、面白いですね。アイディア次第でいろいろな使い方ができそうです。
廣芝:この「高さ」に関するパラメーターのほかに「抑揚」というパラメーターもありますが、この設定を最低値にすると、ロボット的にまったく起伏のない単調な喋り声になります。
--Seiren Voiceを使って生成された喋り声や、こうした歌声も含め、まさに「結月ゆかり」、「琴葉 茜・葵」といった声になっていますが、これは何を学習させて、こう実現できているのですか?
栗田:当社から琴葉 茜・葵、そして結月ゆかりの収録データと、ラベリングデータをドワンゴさんにお渡ししています。A.I.VOICEでは、収録したときの声にできるだけ忠実に再現できるような形で音声合成をしているので、これを学習させたSeiren Voiceに違和感がないというか、そっくりな声が実現できているのではないかと思います。
廣芝:おそらく他社の製品も基本的に収録した声とラベリングしたデータがあるので、Seiren Voiceに喋らせることは可能だと思います。ただ、会社によって多少クセがある可能性はあるし、収録時と違った声質で合成しているとすると、少し違いが出てくる可能性はありそうですね。

--今後、Seiren Voiceがどんな使われ方をするのか、どのような作品が登場してくるのかが楽しみですね。
廣芝:とっても期待しているところです。先ほどお伝えした通り、Seiren Voiceを動かすにはNVIDIAのGPUを搭載している必要があるなど、少し制限もあります。体験版も用意しているので、まずはそれが動作するかを確認の上、ぜひ多くの方に使っていただければと思っています。ちなみに体験版は声を書き出す際に、オーディオウォーターマークが乗るのと、利用できるのが2週間以内という制限があります。が、それ以外は製品版とまったく同じなので、動作を確認するという面では、十分使えるはずです。使っていただいたみなさんの声などを元に、次期製品なども企画していければと思っております。
--本日はありがとうございました。
【関連情報】
Seiren Voice製品情報
週刊ニコニコインフォ 第75号

コメント