2018年のクリスマスに彗星のように誕生した新しい歌声合成ソフト、Synthesizer V(シンセサイザー・ヴイ)は、国内外の歌声合成の世界に大きな影響を与えています。このソフトを開発したのは、発表の時点で23歳であった上海出身の天才青年エンジニア、Kanru Hua(カンル・フア @khuasw)さん。翌2019年に来日し、日本でDreamtonics株式会社を立ち上げるとともに、Synthesizer Vの機能、性能を向上させ、2020年7月に新バージョンとして、国内では株式会社AHSからパッケージソフトとして発売される形となりました。
DTMステーションでも、これまで何回か取り上げてきたので、ご存知の方も多いと思いますが、リリース後、積極的にバージョンアップを繰り返し、AI歌声合成エンジンを搭載するなど、現在もどんどん成長を続けてます。先日、そのSynthesizer Vの解説書となる『歌声合成ソフトウェアSynthesizer Vユーザーズガイド』(三才ブックス)から出版しました。この本の最後で、Kanru Huaさんのインタビュー記事を掲載していたのですが、入門書という位置づけでもあり、あまり突っ込んだ話までは掲載しませんでした。そこで、書籍では書いていなかった話、マニアックなネタも含め、インタビューの特別版をDTMステーションに掲載したいと思います。
 Synthesizer Vの開発者であるDreamtonics株式会社の代表取締役、Kanru Huaさん
Synthesizer Vの開発者であるDreamtonics株式会社の代表取締役、Kanru Huaさん
小学校2年生のころからプログラミングを始めた
--Synthesizer Vの話に入る前、Kanruさんの子供時代について伺いたいのですが、最初のコンピュータに興味を持ったのはいつごろだったのですか?
Kanru:3歳のころ、父からもらったおもちゃで電気の仕組みに興味を持つようになり、小学校に入ったころからラジオ作りなどをしていました。コンピュータもラジオ作りと同じころで、小学校2年生のころにAdobe(当時はMacromedia)のFLASHを使ってプログラムを組むようになったのが最初です。友達がみんなゲームで遊んでいたのに、親が厳しかったので、ゲームはダメと言われていました。そこで、FLASHを使ってクラスメイトが持っているゲームを真似して作ってみたのです。親も自分が作るゲームならいい、と。
 |
Profile
Kanru Hua(華 侃如) |
--プラグラミングのスタートがFLASHだったんですね。
Kanru:中学2年生くらいまでずっとFLASHを使っていました。考え方的にはJavaScriptと一緒なので、悪くはなかったのですが、もっと実用的なものを作りたいとVB.netなどを使うようになっていきました。そのころ、初音ミクにハマったんですよ(笑)。すごく感動して、これの中国語版を作ってみたい、と思ったのです。
--Synthesizer Vの原点はそこにあったんですね。
Kanru:ただ、当然ですが音声合成、歌声合成に関する知識はまったくなかったので、どこから何を始めればいいかも分かりませんでした。そこで、音をグラフにして表示させ、それを変形させるとちょっと音が変わったり……という試行錯誤の繰り返し。ホントはスペクトラムを動かせば音質を変えたりできたのですが、そんなこと当時は分からないから、このグラフを見ながら、母音だと繰り返す部分があるとか、特徴を経験的に覚えつつ、グラフの順番を変えて音を変えてみたり……無駄なことを続けていました。
bilibili動画にUPされている、中学生当時に作った中国語版歌声合成ソフトのデモ
--そうはいっても、中学生で誰にも教わらずに、音声をグラフ表示してエディットして……なんてことをする時点でスゴイです。
Kanru:当時はフィルターでさえもよく分かっていませんでしたが、窓関数を使って平均をとると音が籠った感じになることは見つけたりはしました。でも基礎的な技術やプログラミング技術がなければ、データ量を増やすしかありません。だからVOCALOIDが作り出す音を1つ1つサンプリングして、それをつなぎ合わせることで、なんとか中国語っぽくする試みをしてみました。たしかに、元の初音ミクよりは中国語っぽくはなったものの、あまりにも機械音すぎて納得いくものにはなりませんでした。そのプログラムをネットで公開もしてみたものの、あまりみんな興味を持ってくれなかったですね。こんな手探りを続けていても、これ以上、音質を向上させることはできない、と高校1年生のころに1回諦めたんです。
高校生で膨大な論文を読み漁り力をつけていった
--とはいえ、本当に諦めたわけではないんですよね。
Kanru:圧倒的に知識が足りないことを自覚し、真面目な勉強を始めたんです。音声合成とか歌声合成とかを独学でしっかり学ぼう、と。めちゃくちゃ難しそうで、高校1年生の知識では、最初さっぱり理解できません。でも気づいたのは2000年に発表されたソフトは1992年ごろの論文を元にしているなど、結構長い期間をかけて開発が行われていたということ。そこで、かなり古い論文から読み始め、少しずつ理解していきました。ネット上でこうした論文が公開されているし、それを勉強できるサイトもいろいろあったからです。
--高校生でそんな論文を読むって、普通の人にはできません! 当時、上海の高校に行っていたんですよね?
Kanru:はい、上海にある国際バカロレア(IBDP)プログラムの学校に通っていたので、授業も全部英語というところでした。そのためほとんど全員が卒業したら、海外に行くところだったから、海外の論文を読むこと自体は珍しいことではなかったと思います。私のターニングポイントとなったのは高校3年のとき。自分としては、音声合成でもっとも進
んでいる大学、アメリカのカーネギーメロン大学に進学したいと思っていたのですが、夏休みに申請書を出したのですが、11月にダメと拒否されてしまったのです。とてもショックでした。ほかにもいろいろな大学はあったけれど、あまり興味は持てませんでした。だったら、大学なんて入らなくても自分で勉強すればいいんじゃないか、と……。そこで、高校生の最後の半年は、本気の勉強をしました。スパルタみたいなトレーニングで、1週間で3本くらい自分で論文を読むとともに、それを実際に自分でプログラムに実装していく……という。1970年代の論文からスタートして、2015年ごろのものまで、数十個のプログラムを作って動かしました。
 GitHubにUPされているSHIROのプログラム
GitHubにUPされているSHIROのプログラム
--たとえば、どんなことをするプログラムを作ったのですか?
Kanru:CeVIOなどにも使われている、HMM(隠れマルコフモデル)を用いた歌声合成システムを、ほかの人が作ったライブラリなどは一切使わず、完全にゼロから作ったりしました。また卒業後の夏休みでしたが、歌声データベースを編集するためのラベリングツールとしてSHIROというプログラムを作って、GitHubにオープンソースとして発表したりもしました。
大学を中退してSynthesizer Vの開発に専念
--独学でということでしたが、結局、アメリカの大学に進学していましたよね。
Kanru:カーネギーメロン大学には行けませんでしたが、イリノイ大学の数学・コンピュータサイエンスの学科に進学しました。ここが自分の行けるところで、一番いい大学だったから。ところが、大学に入ると、やはり勉強がとても忙しくなって、ソフトウェア開発がなかなかできなくなってしまいました。あまり大規模な開発はできないから、小さいツールなどを作ろうと。でもやっぱり歌声合成がやりたいと、UTAUのプラグインを作ったりしました。史上最強のUTAUプラグインを作ってみようと、Moresamplerというものを2016年に発表しています。
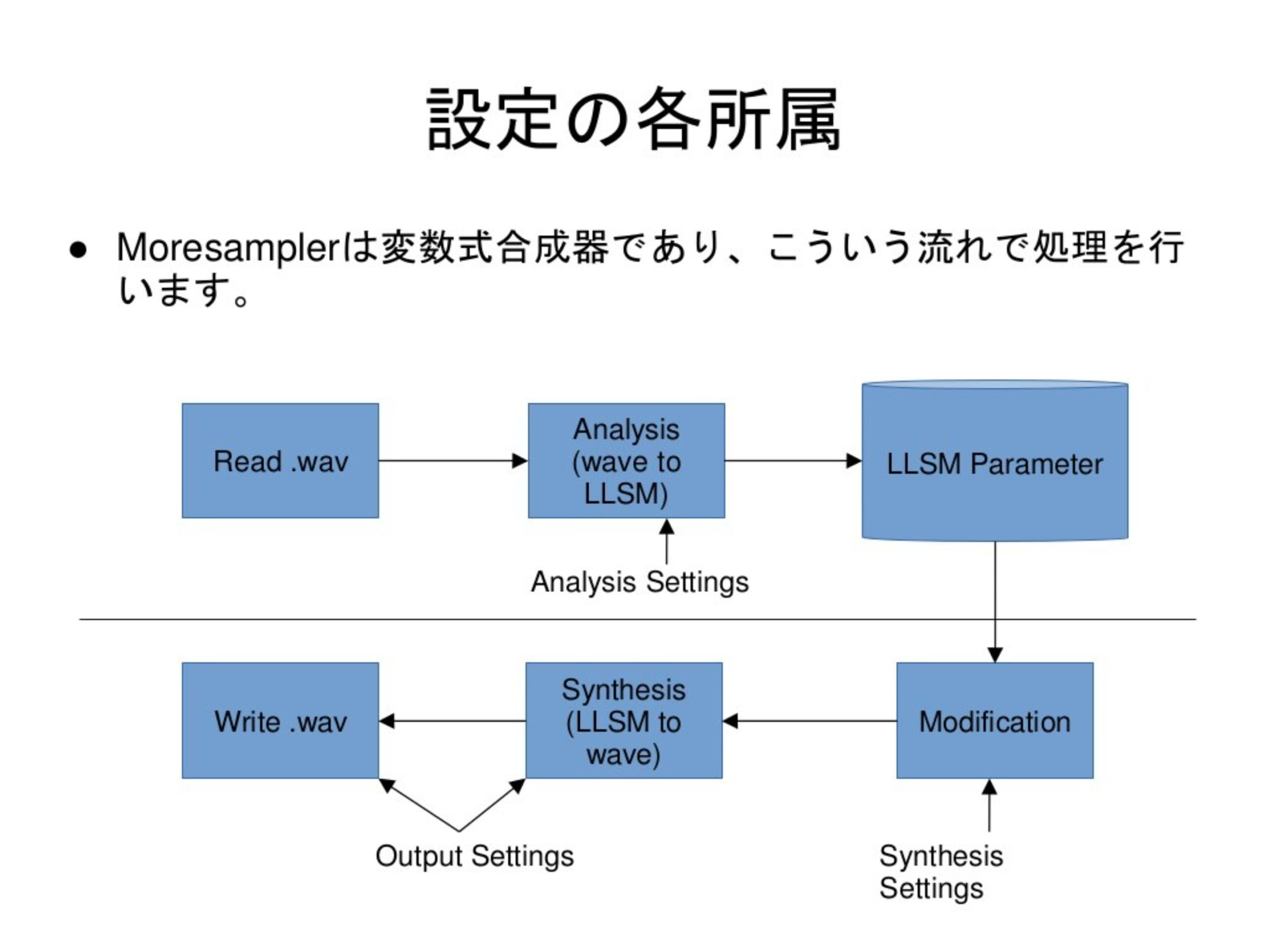 Moresamplerのシステム構成図(Kanruさん作成・Ejiさん訳のMoresampler使い方資料より)
Moresamplerのシステム構成図(Kanruさん作成・Ejiさん訳のMoresampler使い方資料より)
--Moresamplerの評判はどうだったのですか?
Kanru:自分ではすごくいいソフトができたと思ったのですが、ユーザーのみなさんが好むものとのギャップがあったようで、みんなが喜んでくれるソフトを作ることの難しさを実感しました。最初のころは、すぐにクラッシュするなど不具合も多かったのですが、ユーザーのみなさんからフィードバックをもらって、バージョンアップを繰り返し、バージョン5.0のころから安定するとともに、評価も上がっていったように思います。そのころ、SynthesizerVのコンセプトが頭に固まっていきました。
--当時どんなものを思い描いていたのですか?
Kanru:2016年ごろでしたが、音声合成のアプローチは2種類になってきていました。一つは従来のVOCALOIDのようなサンプルベースのもの、もう一つは最近のAIの前身ともいえるAIによるものです。ところが当時AI系のものには大きな問題がありました。それは表現は人間っぽくなるけれど、音質が悪く、どうしても声がこもってしまうのです。AIというと、ごく最近の技術のように聞こえますが、実ははそれほど新しいものではありません。ニューラルネットワークができたのは1990年ごろで、25年以上の歴史があります。一般の人から見ると新しい技術のようにも見えるけど、論文を見てると古くからあるものなんですよね。ただAIの限界というものがどこにあるかわからなかったので、今から作るならAIかな、と思いました。しかし、音質はサンプルベースのほうが明らかによかったから、ハイブリッドで行こう、と考えたのがSynthesizer Vのコンセプトです。

--とはいえ、大学の勉強も大変で、なかなか開発できないわけですよね。
Kanru:授業も大変で、宿題もいっぱいで……。もともとイリノイ大学は理論が中心であって、私がやりたかったのは応用。正直いって、大学は楽しくなかった。とはいえ大学に在籍中であることを利用して、スウェーデンの音声合成に関する学会に参加したり、そこで知り合ったヤマハの人に誘われて、2018年には日本に行ってヤマハで1か月インターンをさせてもらうなど、楽しいこともいろいろありました。このヤマハでのインターン、浜松に滞在していたのですが、実は自分にとって大きな刺激になったのはヤマハでの仕事よりも地元の人たちとの交流でした。そのことが自分の人生に大きな影響の与えてくれたと思うし、それがなかったら、今、日本に来ていなかったと思います。
--浜松の地元の人との交流というのは?
Kanru:地元の人たちと、外国人との交流会イベントで、15分間英語でやりとりし、その後15分間日本語でやりとりする…といったものでした。当時は日本のことも全然知らなかったし、普通の人たちはどのように生活しているのだろう……と好奇心いっぱいで参加したのです。もちろん、そこにはいろいろな立場のいろいろな人がいました。が、自分とは全然違う考え方で生きている人がいっぱいいることを知って驚きました。日本での生活、浜松の生活では、決まっていないこと、ルールが存在していないものが想像以上に多く、みんな、その中で生きているんだ、と。もちろん法律があるものは守るけれど、それ以外は自分が決めてルールで生きているというこうとを知り、より興味を引き付けられたのです。

2016年のハッカソンでのKanru Huaさん(右)、左から小南千明さん、渡部高士さん、江夏正晃さん
--一方で、私がKanruさんに初めて会ったのも、そのころでしたよね。渋谷で行われた「ガッキソン」というミュージシャンを交えたハッカソンで……。まさに道場破りみたいな感じで一人で参加して、優勝しちゃった(笑)。
Kanru:それは2016年7月なので、インターンの2年前ですね。友達に誘われて、その友達と一緒に参加するはずだったのですが、なぜかその友達が来なくて……(苦笑)。あのハッカソンも面白かったですね。普通ハッカソンというと、プログラムに精通した人ばかりが集まるイベントなのに、あそこはプログラミングをまったく知らない人がいっぱいで、ちょっとビックリでしたが、結果的にはクオリティーの高い作品がいろいろできたんですよね。プロミュージシャンの方もいっぱいいて、とても刺激的であり、また日本の別の側面が見えたような気がしました。
 ハッカソンではKanru Huaさんのチームが見事優勝
ハッカソンではKanru Huaさんのチームが見事優勝
--インターンにせよ、ハッカソンにせよ、日本は悪い印象ではなかったわけですね。
Kanru:もちろんですよ。とくに浜松でのインターンがなければ、自分の人生はまったく違うものになっていたと思います。インターン終了後、大学を取るか、Synthesizer Vを取るかと選択に迫られました。どうなるかは分からないけれど、まずはモノを作ってから考えようと、後者を選ぶことに決めたのです。いったん、上海の実家に戻って、プログラミングに専念。そして11月にはとりあえず形になったものが完成し、12月のクリスマスに発売することになりました。
日本に移住し、会社設立へ
--2018年末の突然のSynthesizer V発表には驚きました。リリース直前に連絡をくれて、メールのやりとりをしながら、ベータ版をもらってテストし、そのリリース日に「VOCALOIDの競合となるのか?中国人天才少年が開発した歌声合成ソフト、Synthesizer Vの破壊力」という記事を書いたんですよね。
Kanru:それ以前から、テクニカルプレビューという形で、公開はしていましたが、クリスマスのタイミングでダウンロード販売という形で発売しました。UIも英語、中国語、日本語に対応させたので、日本でも多くに方に使っていただきたいと思い、藤本さんに連絡しました。現在のSynthesizer Vとはだいぶ見た目も違う前のバージョンではありましたが、これで自分の仕事としてのスタートを切った形でした。
--その発売の3か月後くらいでしたっけ、すぐのタイミングで日本に来ましたよね? 中国で続けていくこともできるだろうし、ベンチャーならアメリカで企業するという選択肢もあった中、どうして日本へ?
Kanru:インターンの影響が大きくあるわけですが、実は日本には子供のころから何度も来ていました。2012年に家族旅行で船の旅行をし、福岡の大宰府などを1日見た後、韓国に行って……というのが最初。2回目は高校の卒業旅行で京都、奈良、大阪などを回りました。その後はアメリカの大学に行ったので、帰りに日本に寄るのは留学生にとってのお決まりコース。日本のビザはとりにくい、なんていいますけれど、アメリカの通学ビザを持っていると、日本の長い期間の観光ビザを申請するのに役立つんですよ。そうした経験もあったし、そもそもボーカロイド文化がある日本が好きだったので、せっかく歌声合成のビジネスをするなら日本に行こうと決めたのです。
 2019年に来日し、Dreamtonics株式会社を設立
2019年に来日し、Dreamtonics株式会社を設立
--日本はベンチャーに向かないと、海外に出ていく日本人も多い中、わざわざ日本を選んで来てくれたというのは嬉しくもあり、驚きでもあります。
Kanru:やはり歌声合成ソフトは、日本のマーケットが大きいと思います。やはりこのソフトウェアを成功させるには、日本での成功が最重要だし、これまでの日本で会った人たちや、その環境を考え、日本でならやっていけるのでは、と考えたのです。
--その後、販売においてはAHSが手掛けることになりましたが、その経緯はAHS代表の尾形友秀(@tomo_ahs)さんやアカサコフ==赤迫竜一(@s_akasakov)さん達と一緒に行った飲み会ですよね(笑)。
Kanru:日本に来て、会社を作ったまではよかったのですが、商習慣もよくわからず、どのようにビジネスを進めて行こうかと悩んでいました。日本に限ったことではないですが、いいものを作ってネットにUPしたからといって、売れるわけではないし、ビジネスのことはよくわからないこともいっぱいです。ちょうどそんなとき、藤本さんから「ボカロPの人たちと一緒に飲みにいかないか」と誘っていただきました。何か楽しそう……と期待はしつつ、あまり状況がよく分からないまま参加しました。みなさん、初めてお会いして、いろいろな意見もいただき、とても勉強になりましたが、そこで尾形さんとも話が盛り上がりました。
 日本に会社を作って少し経ったころのKanruさん
日本に会社を作って少し経ったころのKanruさん
--その後、トントン拍子でAHSでの販売が決まったわけですね。
Kanru:後日、尾形さんから連絡をいただき、AHSさんのサンプルをいくつかいただいたり、今後のSynthesizer Vの将来についてさまざまなアイディアもいただきました。一方で、製品が全部英語だと日本での展開が難しいこと、プロモーションも日本語で行わないと怖がってしまう人が多いということなども教えてもらい、日本での商習慣なども教えてもらったところ、めちゃくちゃ難しい。中国ともアメリカとも違うんですよね。自分はやはり技術・開発に専念したいので、マーケティングや販売、営業、サポートに時間を取られるのは厳しいところ。AHSさんにそうした面を任せたら、うまくいくのでは……と思ったのです。まったく別の経緯ではあるけれど、北京や台湾でも、販売をしてくれるパートナーが見つかったタイミングだったので、ビジネス部分は各社にお願いすることにしました。結果として、販売や宣伝といった手間が掛かることはパートナー企業に任せることができ、気も楽になりました。ところが、そのタイミングでまさかのコロナ禍に……。
 Kanru Huaさん(左)と株式会社AHS 代表の尾形友秀さん(右)
Kanru Huaさん(左)と株式会社AHS 代表の尾形友秀さん(右)
--ちょうど、私が開発の手伝いができる人を紹介するので、面接を……という連絡をしていた中、帰国もできなくなっちゃったんでしたね。
Kanru:もともと2020年2月に上海にちょっと行く予定にしていたけど、中国側が大変な状況になっていて帰国を見合わせていたら、その後、日本も緊急事態宣言になってしまって……。結局それ以来、日本からまったく出てないんですよ(苦笑)。AHSさんとはもともと4月に新製品を発表し、5月に製品リリースすることで話を進めていたのですが、難しい状況になってしまいました。このコロナ禍の影響もあり、英語版のライブラリであるエレノア・フォルテの開発も遅れてしまい……。結局2か月送らせて、2020年6月発表、7月発売ということになったのです。
 2020年6月26日に行われたSynthesizer Vの発表会
2020年6月26日に行われたSynthesizer Vの発表会
--AHSから国内正式発売がスタートして1年。手ごたえや反響や売れ行きはいかがですか?
Kanru:AHSさんほかパートナー企業に任せたことは、本当にメリットばかりです。一番はなんといっても開発に使える時間が大きく増えたこと。もちろん、ビジネス面は自分でやってもうまくできないことばかりなので、本当に感謝しています。東京、北京、台湾で販売を行っているわけですが、やはり地域によって反応はいろいろ違うんですよね。日本は自分で使って曲を作りたいという人が多く、実際に販売数も一番なのに対し、中国は聴きたい人が多く、Synthesizer Vを使った楽曲の再生数では日本より圧倒的に多い。bilibili動画などでは500万回を超えるような楽曲もでていますからね。一方、AHSさんからはダウンロード販売ということもあって、日本以外にも結構売れていると聞いています。アメリカやヨーロッパはもちろん、サウジアラビアなど中東地域からも注文がきていて、すでに60か国以上の方が買ってくださっているそうです。
 AHSが販売するSynthesizer V Studio Proと歌声ライブラリSakiのパッケージ
AHSが販売するSynthesizer V Studio Proと歌声ライブラリSakiのパッケージ
--リリースから1年の間にも、AI機能が搭載されたり、数多くの歌声データベースが発表されてきました。今後Kanruさんとしては、どのようにしていきたいとお考えですか?
Kanru:Dreamtonicsは、常に他がやっていないことにチャレンジしていきたいと思っています。誰もやったことがないことだからこそ意味があるのだ、と信じています。まだ、構想として頭にあって、実現させていないものもいっぱいあります。これから、もっともっと強力なソフトにし、もっともっと面白いことができるようにしていくので、ぜひみな
さん期待していてください。
--ありがとうございました。

|
歌声合成ソフトウェア Synthesizer Vユーザーズガイド
冒頭でも触れたとおり、このKanru Huaさんインタビュー記事は、三才ブックスから先日出版された「歌声合成ソフトウェア SynthesizerVユーザーズガイド」の一部を抜き出すとともに、特別版として編集しなおしたものです。この書籍はKanru Huaさん、AHSにも監修していただきつつ、初めての人でもすぐにSynthesizer Vで歌わせることができるように、その基本的使い方や操作手順などを解説しています。全160ページとなる、この書籍は普通に書店やAmazonなどから購入できるほか、AHSからは「Synthesizer V Studio Proガイドブック付き」というパックも販売されています。エディタソフトであるSynthesizer V Studio Proには、マニュアルなどが同梱されているわけではないので、とくに初めての方は、このガイドブック付きがお勧めです! 01 Synthesizer Vとは
02 無料のSynthesizer V Studio Basicを体験してみよう 03 Synthesizer V Studio Proをインストールしよう 04 Synthesizer V Studio Proの歌わせ方 基礎編 05 Synthesizer V Studio Proの歌わせ方 応用編 06 Synthesizer V Studio Proの歌わせ方 発展編 06 Synthesizer V Studio Proの歌わせ方 発展編 07 Synthesizer VをDAWと連携させる 08 開発者 Kanru Huaさんインタビュー ◎Amazon ⇒ SynthesizerVユーザーズガイド |

【関連情報】
Synthesizer Vシリーズ製品情報(AHS)
Dreamtonicsサイト
歌声合成ソフトウェア Synthesizer Vユーザーズガイド情報(三才ブックス)
【関連記事】
Synthesizer Vが着実に進化中。最新アップデートで歌声がより滑らかに人間らしく。弦巻マキも日本語・英語で登場
Synthesizer VとCeVIO AIトークボイスの小春六花が発売開始。実際どんな声が出せるのか試してみた
AI歌声合成に対応したSynthesizer V AIがいよいよリリース。既存ユーザーは無料アップグレード可能。併せてAHSが各種新情報を一挙公開
まるで人のように歌うAI歌声合成の世界がさらに進化。Synthesizer VがAI対応し、従来型とハイブリッドで利用可能に。Sakiユーザーには期間限定無料配布
新世代歌声合成ソフトSynthesizer V Studio ProがアップデートしVST3/AUに対応
歌声合成はさらに次の時代へ。Synthesizer Vがサンプルベースと人工知能のハイブリッドで大きく進化
VOCALOIDの対抗馬、Synthesizer Vが無料で使えるWebブラウザ版を公開。2020年、歌声合成はさらに進化する
VOCALOIDの競合となるのか?中国人天才少年が開発した歌声合成ソフト、Synthesizer Vの破壊力


コメント
藤本様
初めまして。ジャスト株式会社の古川純一といいます。
以下の文章を読んで、コメントを送りました。
https://www.dtmstation.com/archives/45880.html?fbclid=IwAR1NPz9X8wfUvjCTYGUJNLCCV3AZ2IPbp9Vi2kcOZlGYujhyHklwVMqxVII
以下の情報も読んでみてください。
https://www.dtmstation.com/archives/42205.html?fbclid=IwAR1vYmVWgbrybP77t-fp36pKHg8GXmbwsIG7YeftkI4X-zBSL4V3VNZcY_E
私は、かつて大学院生時代に人工喉頭装置を研究していたことがあり、今の音声合成の欠点である喜怒哀楽情報を再現できない問題を解決するアイデアと音声合成のデモを持っています。
以下にご興味がございましたら、メール頂けると嬉しいです。
「人が聴いても違和感が少ない、不特定話者の声の特徴データを再現した音声合成技術の応用特許」
アニメ声優や映画俳優、歌手が亡くなっても未来永劫喋ったり歌ったりできる音声合成です。
サンプル音声として、私は英語をネイティブに喋ることはできませんが、あたかもネイティブのように喋たったかのように聴こえるサンプルがあります。
※この技術は、応用が無限にあります。今まで映画の世界で再現できない映像が無くなったように、音声も再現できないことが無くなります。
※母国語しか喋れない声優さんや歌手が、多言語の母国語をネイティブで喋ったり歌ったりすることができるので現地の吹き替えが不要になります。(不特定話者に喋って頂く必要があるのでリアルタイムに喋ったり歌ったりはできません、アニメや映画など喋ることが決まっている音声に対応できます)
以上、よろしくお願いいたします。
——————
氏名 古川 純一 (ふるかわ じゅんいち)
役職 代表取締役
社 名 ジャスト株式会社